Hadoop安装及配置
1、将hadoop-2.7.5.tar.gz上传到/opt目录下并解压缩到/usr目录下
tar -zxvf hadoop-2.7.5.tar.gz -C /usr #修改文件名 mv hadoop-2.7.5 hadoop
2、修改配置文件
vim /etc/profile //添加以下内容 export HADOOP_HOME=/usr/hadoop export HADOOP_CONF_DIR=/usr/hadoop/etc/hadoop PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH //保存配置 source /etc/profile
查看Hadoop目录结构:
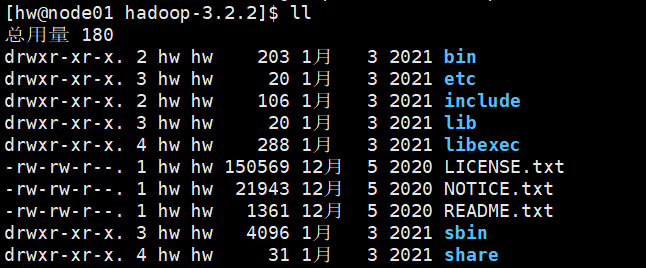
- bin目录:存放对Hadoop相关服务(hdfs,yarn,mapred)进行操作的脚本;
-
etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件;
-
lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能);
-
sbin目录:存放启动或停止Hadoop相关服务的脚本;
-
share目录:存放Hadoop的依赖jar包、文档、和官方案例。
3、编辑hadoop/etc/hadoop/hadoop-env.sh文件,修改JAVA_HOME值对应到jdk安装目录
export JAVA_HOME=/usr/opt/jdk1.8.0_301
下面是配置Hadoop,在/opt/hadoop/etc/hadoop子目录下:
4、配置核心组件文件core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name> //配置节点地址和端口号
<value>hdfs://192.168.71.129:9000</value> //格式必须是host:port形式
</property>
<property>
<name>hadoop.tmp.dir</name> //Hadoop临时目录用来存放临时文件
<value>/usr/hadoop/hadoopdata</value> //该目录需要预先手工创建
</property>
<property>
<name>hadoop.proxyuser.spark.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.spark.groups</name>
<value>*</value>
</property>
</configuration>
5、配置文件系统hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.71.129:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
6、配置Yarn文件yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.71.129:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.71.129:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.71.129:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.71.129:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.71.129:8088</value>
</property>
</configuration>
7、配置MapReduce计算框架文件mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.71.129:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.71.129:19888</value>
</property>
</configuration>
8、若做集群还需要配置slaves文件vim slaves
//根据从机ip配置,例如:已经安装了slave0和slave1,并且计划将它们全部投入Hadoop集群运行。 192.168.71.130 192.168.71.131
注意:删除slaves文件中原来localhost那一行!
9、复制主机master上的Hadoop到slave节点
scp -r /opt/hadoop root@slave0:/opt
scp -r /opt/hadoop root@slave1:/opt
10、创建Hadoop数据目录
mkdir /usr/hadoop/hadoopdata
11、启动/关闭Hadoop
cd /opt/hadoop/sbin //启动 start-all.sh //关闭 stop-all.sh

 浙公网安备 33010602011771号
浙公网安备 33010602011771号