

dropout解析--缓解过拟合
一、dropout的提出和原理
在2012年,Hinton在其论文《Improving neural networks by preventing co-adaptation of feature detectors》中提出Dropout,目的是为了缓解模型的过拟合。
co-adaptation:在神经网络中,隐藏层单元之间有很高的相关性。
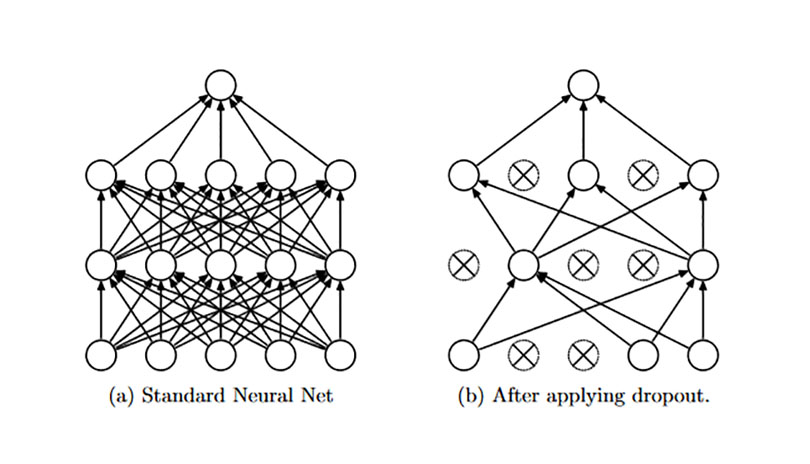
原理:我们都知道通过平均多个不同网络的预测输出可以很好地降低error,但是这种方法训练和测试时计算代价巨大。Dropout的本质其实与之类似,当每次训练随机忽略部分hidden units的时候(其实就是只用这些高相关性的隐藏层单元的一部分),就相当于在训练不同的模型。
可参考hinton的另一篇论文《Dropout: A Simple Way to Prevent Neural Networks from Overfitting》。
二、dropout的工作流程
训练:dropout是随机的置一些神经元为0,仅仅使用一部分神经元,在backward阶段,只改变那些神经元不为0的节点的参数。
测试:dropout的概率置1,不使用dropout。
三、dropout的代码演示
注意,输出的非0元素是原来的 “1/keep_prob” 倍,保证数据在整体上保持一致。
import tensorflow as tf dropout = tf.placeholder(tf.float32) x = tf.Variable(tf.ones([10, 10])) y = tf.nn.dropout(x, dropout) init = tf.initialize_all_variables() with tf.Session() as sess: sess.run(init) print(sess.run(x)) print (sess.run(y, feed_dict = {dropout: 0.5}))
对应输出
[[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.] [1. 1. 1. 1. 1. 1. 1. 1. 1. 1.] [1. 1. 1. 1. 1. 1. 1. 1. 1. 1.] [1. 1. 1. 1. 1. 1. 1. 1. 1. 1.] [1. 1. 1. 1. 1. 1. 1. 1. 1. 1.] [1. 1. 1. 1. 1. 1. 1. 1. 1. 1.] [1. 1. 1. 1. 1. 1. 1. 1. 1. 1.] [1. 1. 1. 1. 1. 1. 1. 1. 1. 1.] [1. 1. 1. 1. 1. 1. 1. 1. 1. 1.] [1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]] [[0. 2. 0. 2. 2. 0. 2. 0. 0. 2.] [0. 0. 0. 2. 0. 0. 0. 0. 0. 0.] [2. 0. 0. 2. 0. 2. 2. 0. 0. 2.] [2. 2. 0. 2. 2. 0. 2. 2. 0. 2.] [0. 0. 0. 0. 0. 2. 0. 0. 0. 0.] [0. 2. 2. 2. 0. 2. 2. 0. 2. 0.] [2. 0. 0. 0. 2. 2. 0. 0. 2. 0.] [2. 2. 2. 2. 0. 0. 2. 0. 2. 0.] [0. 2. 0. 0. 0. 0. 2. 0. 2. 0.] [0. 2. 0. 0. 0. 0. 0. 2. 2. 2.]]
