ELMo Bert XLnet介绍
一、ELMo
1.基本信息
2018年提出的论文《Deep contextualized word representations》,其中一个很重要的思想就是ELMo,论文发表在NAACL。
ELMo是一种新型深度语境化词表征,可对词进行复杂特征(如句法和语义)和词在语言语境中的变化进行建模(即对多义词进行建模)。所以ELMo的模型对同一个字在不同句子中能生成不同的词向量。
2.整体框架
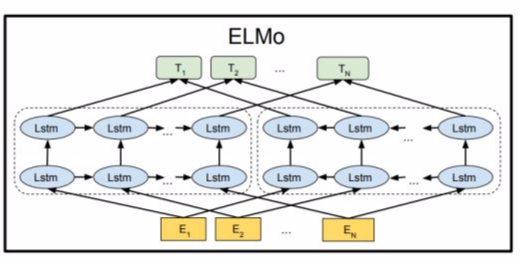
ELMo使用的是一个双向的LSTM语言模型,由一个前向和一个后向语言模型构成,目标函数就是取这两个方向语言模型的最大似然。
前向LSTM结构:
$ p(t_1,t_2,...,t_N)=\prod_{k=1}^N p(t_k|t_1,t_2,...,t_{k−1}) $
反向LSTM结构:
最大似然函数:
$O=\sum_{k=1}^N(log \; p(t_k|t_1,t_2,...,t_{k−1})+log \; p(t_k|t_{k+1},t_{k+2},...,t_N))$
在预训练好这个语言模型之后,就是把这个双向语言模型的每一中间层进行一个求和。最简单的也可以使用最高层的表示来作为ELMo。然后在进行有监督的NLP任务时,可以将ELMo直接当做特征拼接到具体任务模型的词向量输入或者是模型的最高层表示上。
二、Bert
1.基本信息
2018年由Google提出来的模型,论文名称《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
提出问题:单向问题:只考虑了前面的token,会是局部最优,对于QA问题,单向会是灾难性的;如果是双向,多层,那么会看到自己,就是要预测的词在给定的序列中已经出现。
创新点:双向,同时引入mask,去预测mask位置的词;在大量数据集上预训练模型;fine-tune,只改变一些超参设置。
答疑:只会看到自己会有什么问题?这样的话在训练的过程中损失会很小,很容易收敛,但是模型效果不好。
2.预训练
这一步目标就是做语言模型
1)模型结构

具体transformer结构可参考:https://www.cnblogs.com/AntonioSu/p/12019534.html
论文中主要有两种配置
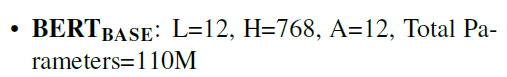
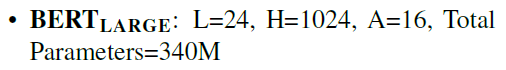
2)Embedding
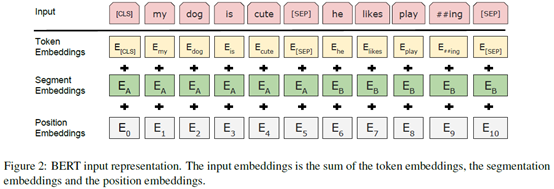
将三者相加:Token Embeddings+Segment Embeddings+Position Embeddings
- Token Embeddings是词向量,第一个单词是CLS标志,可以用于之后的分类任务
- Segment Embeddings用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务
- Position Embeddings和之前文章中的Transformer不一样,不是三角函数而是学习出来的
3)MASK LM
随机mask语料中15%的token,然后将masked token 位置输出的最终隐层向量送入softmax,来预测masked token。
这样输入一个句子,每次只预测句子中大概15%的词,所以BERT训练很慢。。。(但是google设备NB。。)

而对于盖住词的特殊标记,在下游NLP任务中不存在。因此,为了和后续任务保持一致,作者按一定的比例在需要预测的词位置上输入原词或者输入某个随机的词。如:my dog is hairy
- 有80%的概率用“[mask]”标记来替换——my dog is [MASK]
- 有10%的概率用随机采样的一个单词来替换——my dog is apple
- 有10%的概率不做替换——my dog is hairy
4)Next Sentence Prediction
在很多任务中,仅仅靠encoding是不足以完成任务的(这个只是学到了一堆token级的特征),还需要捕捉一些句子级的模式,来完成SLI、QA、dialogue等需要句子表示、句间交互与匹配的任务。对此,BERT又引入了另一个极其重要却又极其轻量级的任务,来试图把这种模式也学习到。
句子级负采样
句子级别的连续性预测任务,即预测输入BERT的两端文本是否为连续的文本。训练的时候,输入模型的第二个片段会以50%的概率从全部文本中随机选取,剩下50%的概率选取第一个片段的后续的文本。 即首先给定的一个句子(相当于word2vec中给定context),它下一个句子即为正例(相当于word2vec中的正确词),随机采样一个句子作为负例(相当于word2vec中随机采样的词),然后在该sentence-level上来做二分类(即判断句子是当前句子的下一句还是噪声)。
句子级表示——[CLS]

BERT是一个句子级别的语言模型,不像ELMo模型在与下游具体NLP任务拼接时需要每层加上权重做全局池化,BERT可以直接获得一整个句子的唯一向量表示。它在每个input前面加一个特殊的记号[CLS],然后让Transformer对[CLS]进行深度encoding,由于Transformer是可以无视空间和距离的把全局信息encoding进每个位置的,而[CLS]的最高隐层作为句子/句对的表示直接跟softmax的输出层连接,因此其作为梯度反向传播路径上的“关卡”,可以学到整个input的上层特征。
3.fine-tune
这一阶段是结合下游具体任务,微调参数。
可以调整的参数和取值范围有:
- Batch size: 16, 32
- Learning rate (Adam): 5e-5, 3e-5, 2e-5
- Number of epochs: 3, 4
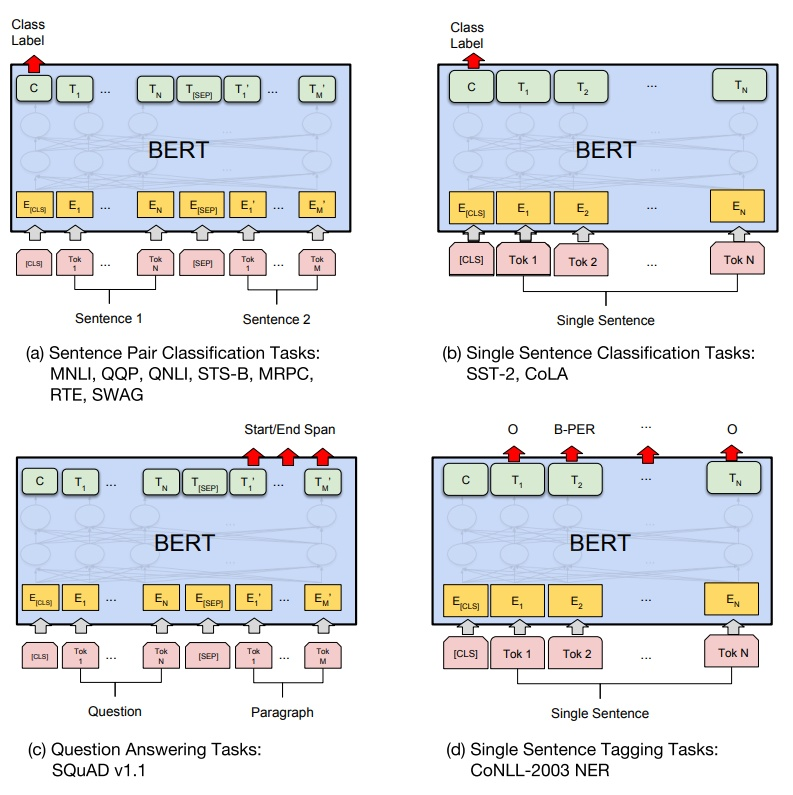
三、XLNet
1.背景
在论文里作者使用了一些术语,比如自回归(Autoregressive, AR)语言模型和自编码(autoencoding)模型等。自回归是时间序列分析或者信号处理领域喜欢用的一个术语,我们这里理解成语言模型就好了:一个句子的生成过程如下:首先根据概率分布生成第一个词,然后根据第一个词生成第二个词,然后根据前两个词生成第三个词,……,直到生成整个句子。而所谓的自编码器是一种无监督学习输入的特征的方法:我们用一个神经网络把输入(输入通常还会增加一些噪声)变成一个低维的特征,这就是编码部分,然后再用一个Decoder尝试把特征恢复成原始的信号。我们可以把BERT看成一种AutoEncoder,它通过Mask改变了部分Token,然后试图通过其上下文的其它Token来恢复这些被Mask的Token。
1)自回归
给定文本序列x=[x1,…,xT],语言模型的目标是调整参数使得训练数据上的似然函数最大:
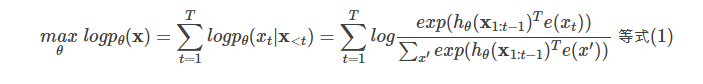
记号$x_{<t}$表示t时刻之前的所有x,也就是$x_{1:t−1}$。$h_θ(x_{1:t−1})$是LSTM编码的t时刻之前的隐状态。e(x)是词x的embedding。
自编码的缺点
独立假设
- 注意等式(2)的约等号≈,它的意思是假设在给定$\hat{x}$的条件下被Mask的词是独立的(没有关系的),这个显然并不成立,比如”New York is a city”,假设我们Mask住”New”和”York”两个词,那么给定”is a city”的条件下”New”和”York”并不独立,因为”New York”是一个实体,看到”New”则后面出现”York”的概率要比看到”Old”后面出现”York”概率要大得多。而公式(1)没有这样的独立性假设,它是严格的等号。
输入噪声
- BERT的在预训练时会出现特殊的[MASK],但是它在下游的fine-tuning中不会出现,这就是出现了不匹配。而语言模型不会有这个问题。
2)自编码
而BERT是去噪(denoising)自编码的方法。对于序列x,BERT会随机挑选15%的Token变成[MASK]得到带噪声版本的$\hat{x}$。假设被Mask的原始词为$\bar{x}$,那么BERT希望尽量根据上下文恢复(猜测)出原始词,也就是:
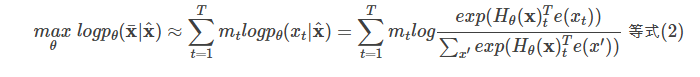
上式中$m_t$表示t时刻是一个Mask,需要恢复。$H_θ$是一个Transformer,它把长度为T的序列x映射为隐状态的序列$H_θ(x)=[H_θ(x)_1,H_θ(x)_2,...,H_θ(x)_T]$。注意:前面的语言模型的RNN在t时刻只能看到之前的时刻,因此记号是$h_θ(x_{1:t−1})$;而BERT的Transformer(不同与用于语言模型的Transformer)可以同时看到整个句子的所有Token,因此记号是$H_θ(x)$。
自回归的缺点
- 自回归模型只能参考一个方向的上下文,而BERT可以参考双向整个句子的上下文,因此这一点BERT更好一些。
2.排列语言建模(Permutation Language Modeling)
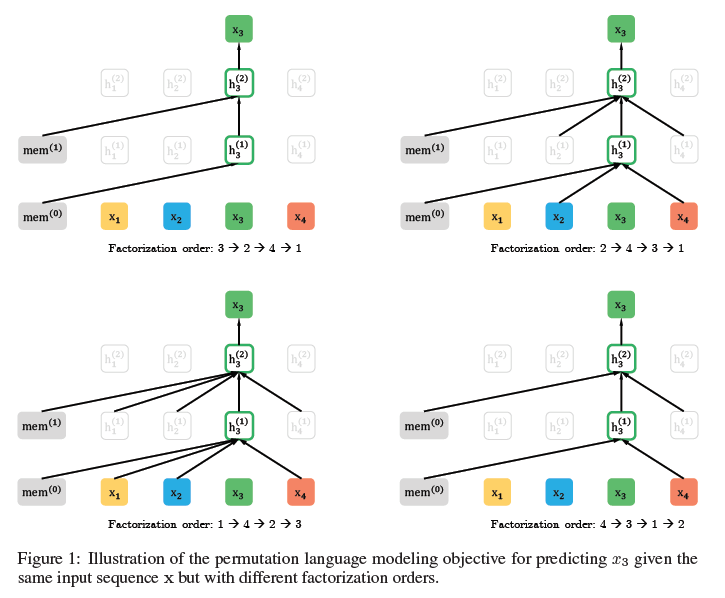
研究者展示了一个在给定相同输入序列 x(但因式分解顺序不同)时预测 token $x_3$的示例,如下图所示:比如图的左上,对应的分解方式是3→2→4→1,因此预测$x_3$是不能attend to任何其它词,只能根据之前的隐状态memmem来预测。而对于左下1→4→2→3,$x_3$可以attend to其它3个词。
给定长度为T的序列x,总共有T!种排列方法,也就对应T!种链式分解方法。比如假设x=x1x2x3,那么总共用3!=6种分解方法:
注意p(x2|x1x3)指的是第一个词是x1并且第三个词是x3的条件下第二个词是x2的概率,也就是说原来词的顺序是保持的。如果理解为第一个词是x1并且第二个词是x3的条件下第三个词是x2,那么就不对了。
如果我们的语言模型遍历T!种分解方法,并且这个模型的参数是共享的,那么这个模型应该就能(必须)学习到各种上下文。普通的从左到右或者从右往左的语言模型只能学习一种方向的依赖关系,比如先”猜”一个词,然后根据第一个词”猜”第二个词,根据前两个词”猜”第三个词,……。而排列语言模型会学习各种顺序的猜测方法,比如上面的最后一个式子对应的顺序3→1→2,它是先”猜”第三个词,然后根据第三个词猜测第一个词,最后根据第一个和第三个词猜测第二个词。
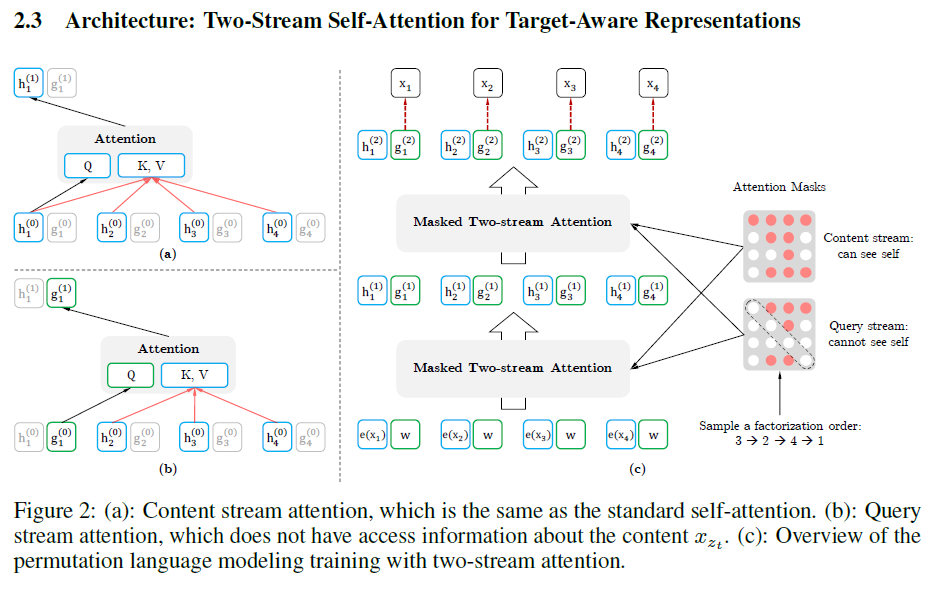
3.Two-Stream Self-Attention

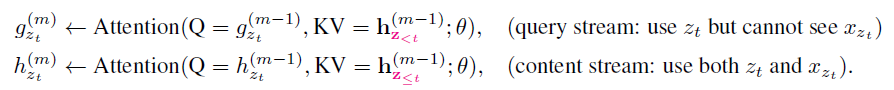
预测当前词,使用query stream,其他情况用content stream
参考网站:
https://www.cnblogs.com/huangyc/p/9860430.html
https://zhuanlan.zhihu.com/p/46652512
https://www.cnblogs.com/rucwxb/p/10277217.html
https://blog.csdn.net/weixin_37947156/article/details/93035607

 浙公网安备 33010602011771号
浙公网安备 33010602011771号