
关于文本翻译的经典论文小结
2014翻译论文
Sequence to Sequence Learning with Neural Networks
基本信息:2014 nips 6500+
目标公式:$ p(y_t|v, y_1, . . . , y_{ t−1}) $
参数:$y_t$是生成的翻译文本,$v$是表达输入文本的定长向量
创新点:1.多层LSTM优于浅层LSTM,2.句子逆序效果会更好
模型架构:用多层LSTM将输入序列$A,B,C,<EOS>$生成$v$ , 而后再利用另一个LSTM生成翻译文本。

如下为两层LSTM堆叠

2015翻译论文
1.Neural Machine Translation by Jointly Learning to Align and Translate
基本信息:2015 ICLR 6900+
提出问题:对于越长的文本翻译效果越差
解决方案:encoder-decoder模型,decoder时期的每个$h_j$都和encoder部分所有$h_i$得到加权值$α_i$,而后再$α_i$乘以对应的$h_i$求和,得到新表示的$c_i$。以上方法能够有重点的关注和解码部分最相关的部分。

2.Effective Approaches to Attention-based Neural Machine Translation
基本信息:2015 EMNLP 1800+
1)Global Attention
计算流程:
$a_t(s)=align(h_t,\bar{h}_s)= \frac{exp(score(h_t,\bar{h}_s)}{\sum_{s^\prime}exp(score(h_t,\bar{h}_{s^\prime})}$
$
score(h_t,\bar{h}_s)=\left\{\begin{matrix}
h_t^\top\bar{h}_s & dot\\
h_t^\top W_a\bar{h}_s & genral\\
W_a[h_t;\bar{h}_s] & concat
\end{matrix}\right.
$
$c_t$是$a_t$乘以每一个source hidden state得到。
$\tilde{h}_t = tanh(W_c[c_t;h_t])$
$p(y_t|y< t, x) = softmax(W_s\tilde{h}_t)$
故而步骤:$h_t \rightarrow a_t \rightarrow c_t \rightarrow \tilde{h}_t $

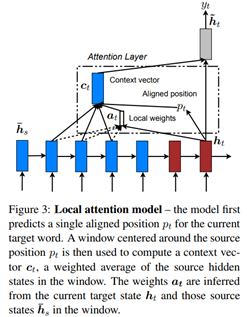
2)local attention
global 有两个缺点:1.关注整个input words非常昂贵 2.对于长句子也很不切实际。
寻找位置和目标词对应的时刻$p_t$,计算$p_t$左右距离为D的source hidden state权重。
计算流程:
$p_t = S \cdot sigmoid(v^\top_p tanh(W_ph_t))$,$p_t $的另一种计算方式是按照source和target的位置强制对齐。S是source 句子的长度。
$a_t(s)=align(h_t,\bar{h}_s)exp(-\frac{(s-p_t)^2}{2\sigma^2})$
2017翻译论文
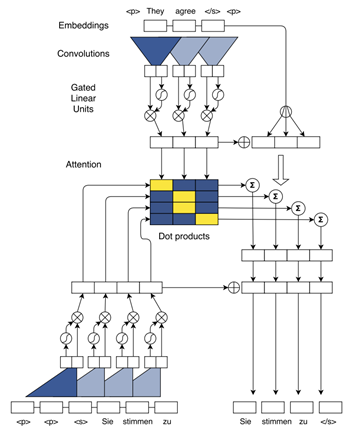
1.convolutional sequence to sequence learning
基本信息:2017 arXiv 600+
详解:参考https://www.cnblogs.com/huangyc/p/10152296.html
2.Attention Is All You Need
参考:https://www.cnblogs.com/AntonioSu/p/12019534.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号