yolo系列详解--yolov1、yolov2、yolov3
1.yolo:You Only Look Once: Unified, Real-Time Object Detection
论文地址:https://arxiv.org/pdf/1506.02640.pdf
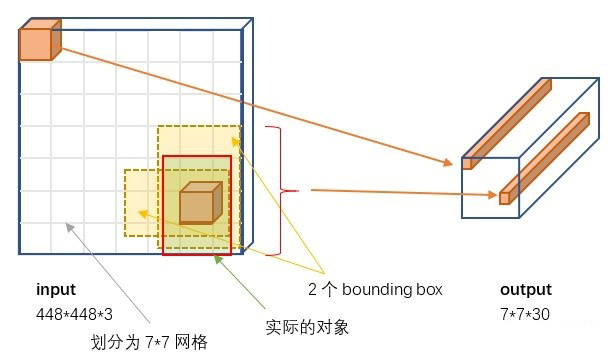
处理流程:输入图片需要缩放到448*448,最后生成一个维度为7*7*30的tensor。
创新点:因为是一阶段的网络,故而运行速度快。
论文的整体框架如下:

对于最后的7*7*30的tensor的意义如下:
将448*448的图片分割成S*S的网格,每个网格都预测2个bounding boxes(如果物体的重心落在bounding box中,那么此bounding box负责检测物体)。
等式:7*7*30=SxSx(B*5+C) 其中S=7,B=2,C=20(PASCAL VOC),5是指一个置信度和四个坐标值。
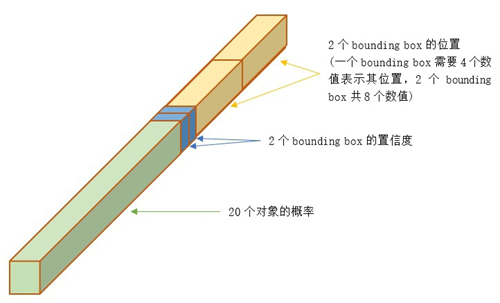
每个bounding box包含四个坐标值(Center_x,Center_y,width,height)和一个置信度(该bounding box内存在对象的概率 * 该bounding box与该对象实际bounding box的IOU)
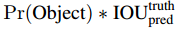
其中Pr(Object)={0,1},如果不存在物体,则为0,否则为1。
IOU可参考:https://www.cnblogs.com/AntonioSu/p/12193743.html
具体维度30各值所代表的意义:
2.YOLO9000: Better, Faster, Stronger
论文地址:https://arxiv.org/pdf/1612.08242.pdf
处理流程:两阶段训练网络,先classification,后detention。
classification:先用224*224的图片预训练Darknet-19,而后再用448*448的图片微调网络Darknet-19。
detention:每隔10个batches,换一种输入维度{320,352...,680},而后对darknet-19做如下处理
移除最后一个卷积层、avgpooling层以及softmax层,并且新增了三个3*3*1024卷积层,同时增加了一个passthrough层,passthrough
对最后一个池化层的输入做变化,将26*26*512变为13*13*2048做处理,而后与最后一层的13*13*1024拼接在一起,变为13*13*3072。最后通过1*1卷积核
变为13*13*125。
创新点:
1.通过聚类的方式找到每个特征点有5个anchor
2.没使用全连接
3.平滑处理
Darknet-19
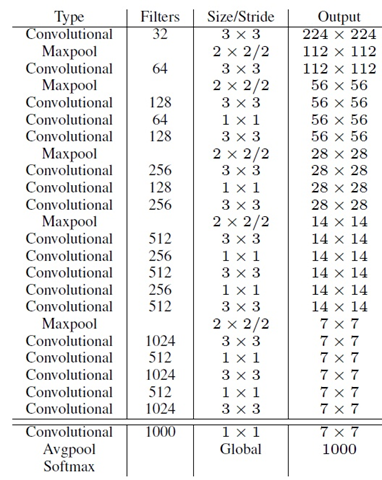
最后的13*13*125的解释:
125=num_anchors *(4+1+num_classes) ,其中 num_anchors=5,num_classes=20(VOC)。
passthrough是为了检测图片中的小物体, passthrough层操作方式:
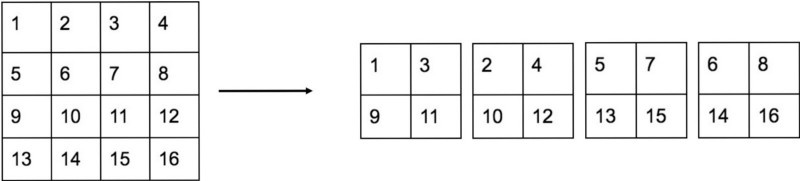
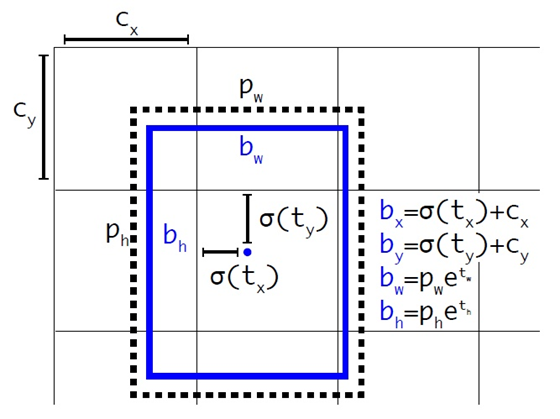
平滑处理:对坐标值加入exp(x)
3.YOLOv3: An Incremental Improvement
论文地址:https://arxiv.org/pdf/1804.02767.pdf
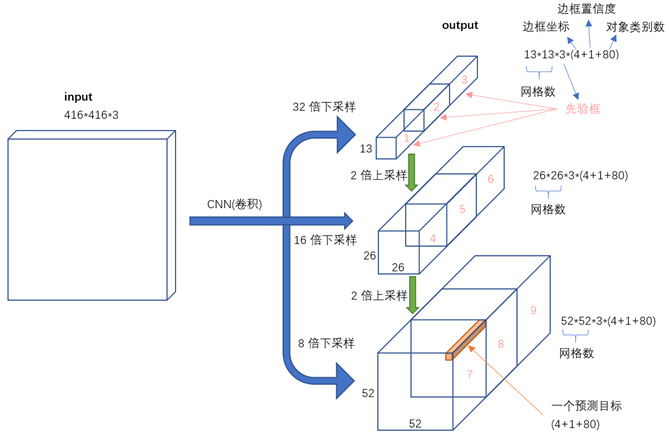
处理流程:先通过Darknet-53处理得到13*13*3*85的特征,而后再上采样,分别得到26*26*3*85和 52*52*3*85.
创新点
1.detention网络引入残差
2.在不同的特征图上做处理
3.没用pooling,没用全连接
Darknet-53
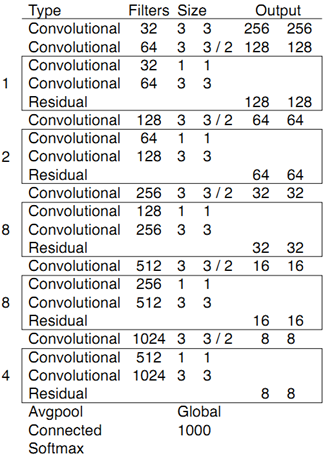
先验框:

总共有 13*13*3 + 26*26*3 + 52*52*3 = 10647 个预测。每一个预测是一个(4+1+80)=85维向量,这个85维向量包含
边框坐标(4个数值),边框置信度(1个数值),对象类别的概率(对于COCO数据集,有80种对象)。