

2019 CVPR 基于GAN的ImageCaptioning论文
1.MSCap: Multi-Style Image Captioning with Unpaired Stylized Text
生成多种风格的caption
当前的image captioning systems的问题:生成的caption是很相对很中性,不能体现人类语言风格的多种多样
面临的困难:得到配对的风格和对应的caption是很昂贵的,所以本论文只是使用image和对应的多个caption,最后加一个分类器,对caption分类
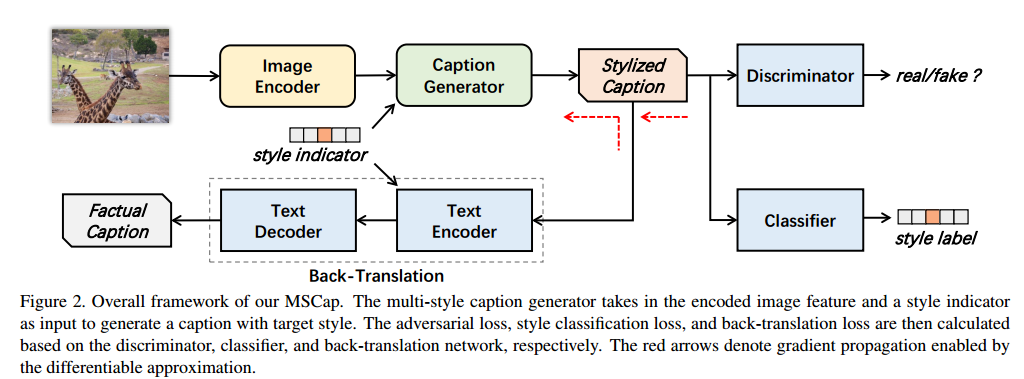
整体框架:Caption Generator输入图像和风格指示,生成对应的风格照片,Discriminator输入的是真实地文本和生成的文本,判断真假
2.Adversarial Semantic Alignment for Improved Image Captions
动机:解决生成的caption的多样性和自然性
方案:通过一个矩阵将文本和图像对齐,而后联合训练,使生成的文本更加的多样性
对于Generator无法全局更新参数的解释如下:
Discriminator只能对一句话判别真假,而不是对一个词判别真假,所以Discriminator提供给Generator的只是对整句话真假的判别,所以Generator无法仅仅根据这一指标来更新参数。
而Generator(使用的是LSTM)生成的是离散的词,只能是一个词一个词的对Generator进行更新,无法同时用所有的词更新参数,因为不可导。
整体框架如下:

