[论文分享] Self-Promoted Prototype Refinement for Few-Shot Class-Incremental Learning
这篇论文是CVPR’ 2021的一篇Few-Shot增量学习(FSCIL)文章
| No. | content |
|---|---|
| PAPER | {CVPR' 2021} Self-Promoted Prototype Refinement for Few-Shot Class-Incremental Learning |
| URL | 论文地址 |
| CODE | 代码地址 |
1.1 Motivation
· 小样本增量学习增量类别样本过少,不足以训练好分类和蒸馏过程,不能像现有增量学习方法那样促进表示空间进一步扩展。
· 新类别样本不足以支撑在维持旧类性能的同时在新类上学习到区分性很好的分类器。
· 新类样本不足,用于分类的prototype在增量学习后容易与其他类混淆,从而极大地影响后续任务的完成。
1.2 Contribution
· 采用随机episode选择策略(RESS),通过强制特征自适应于各种随机模拟的增量过程来增强特征表示的可扩展性。
· 引入了一种自提升的原型细化机制(SPPR),利用新类样本和旧类prototype表示之间的关系矩阵来更新现有的prototype。
1.3 Method
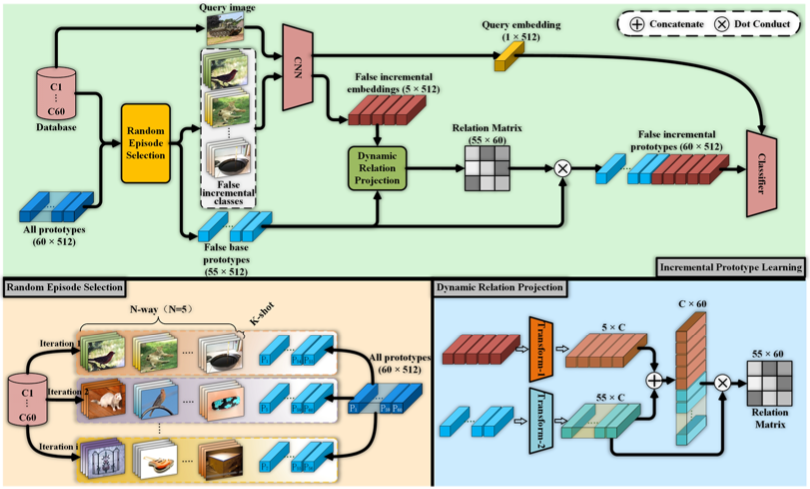
1.3.1 Standard Learning Paradigm
对于增量任务中base classes的训练过程,采用标准的分类pipeline。采用VGG或ResNet等分类器提取特征
然后通过参数为\(\theta_m\)分类器\(f_m\)进行分类(包括非参数的最近临分类器和余弦分类器、有参数的线性分类器),\(\theta_p\)是可学习的原型
例如余弦分类器上述公式可以写为:
其中\(\eta\)是scale。通过随机采样query图像样本来训练优化\(\theta\),通过如下公式最小化损失函数\(L\)
上式中的\(\theta\)包括\(\theta_e,\theta_p,\theta_m\)等。分类任务中,\(L\)大多采用CE Loss。
1.3.2 Incremental Prototype Learning
这部分作者提出了一个增量原型学习策略来解决standard learning中表示缺少可扩展性的问题。
Random Episode Selection
通过随机采集episode强制梯度适应随机生成的不同模拟增量过程,提高了特征表示的可扩展性。
与few-shot任务中识别一个episode的\(N way\)目的不同,作者提到设计模拟增量过程的目标是通过\(N way\)的少量样本来识别所有看到的类。
具体来说,除了上面查询的图像\(Q\)之外,模型的输入还包含一个随机从\(base\)训练集\(X^1\)中选取的\(N-way \ \ K-shot\)集合\(C\)。如图所示,在每次迭代中,从标签空间\(Y^1\)中随机选择\(N\)个类,然后选择\(K\)个样本用于特征提取器。得到的嵌入对每个类取平均值:
最后,假设这\(N\)个类在此迭代之前没有出现过,因此它们对应的原型将被删除
\(|Y^1|\)即为标签集\(Y^1\)的类别数,\(\mathbb{C}\)表示确定项目集合中可能分配的数学操作。
最终的分类过程如下
Dynamic Relation Projection
为了保持旧类间的依赖并增强新类间的区分度,作者提出了自促进prototype精炼机制,
首先通过变换将标准学习与增量学习原型转换到统一隐空间
\(f_{t_1}\)和\(f_{t_2}\)由标准1x1卷积、BatchNorm、ReLU组成。随后在新旧类之间计算余弦相似度
由此可以获得新旧类之间的关系矩阵,将其作为原型优化的过渡系数
由于精炼机制不仅明确考虑了新旧类之间的关系,而且在随机选择过程的指导下,原型动态地向维护已有知识和增强新类辨别能力的方向移动。
作者认为,在设计的这种学习机制下,模型不仅学习表示,而且鼓励网络向更利于后续增量任务的方向优化。
1.4 Analysis
作者分析了伪增量设置更新次数的影响,
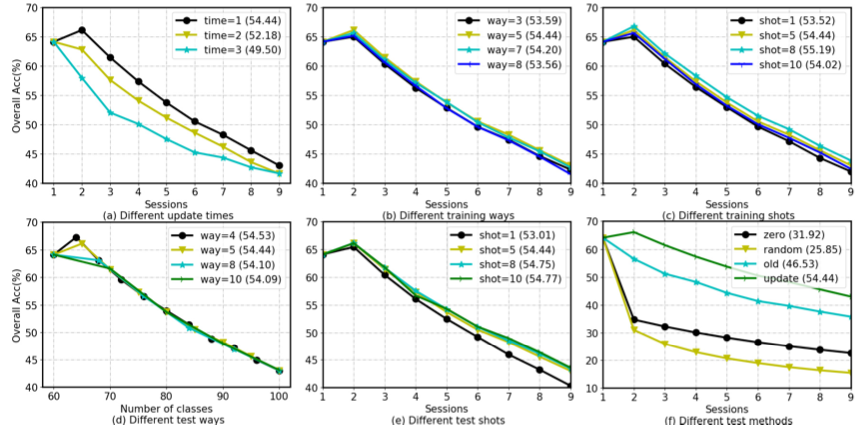
发现在base classes上,更新两次效果最好,也就是说,最后60个类的原型将通过50个类的伪base prototype(每次5个类)的两次增量更新获得。如上图(a)所示。
作者还探讨了train、test的way/shot大小的影响以及不同测试方法的影响如上图所示。
【参考文献】
[1] Zhu K, Cao Y, Zhai W, et al. Self-Promoted Prototype Refinement for Few-Shot Class-Incremental Learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 6801-6810.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号