
[Design Pattern] Upload big file - 4. Code Design - part 2 & Summary
How to Control Requests?
Controlling requests involves addressing several key issues:
1. How to Maximize Bandwidth Utilization
- In chunked uploads, a large number of requests are sent. These requests should not be sent all at once, causing network congestion, nor sent sequentially, wasting bandwidth.
- Solution: Use the foundational
TaskQueueto implement concurrency control.
2. How to Decouple from Upper-Layer Request Libraries
- For versatility, upper-layer applications may use different request libraries to send requests. Therefore, the frontend SDK should not bind itself to any specific request library.
- Solution: Use the Strategy Pattern to decouple from the request library.
The implementation of the request control mechanism can be complex. Below is the core code structure:
Request strategy:
// requestStrategy.ts
import { Chunk } from "./chunk";
export interface RequestStrategy {
// create file request, return token
createFile(file: File): Promise<string>;
// chunk upload request
uploadChunk(chunk: Chunk): Promise<void>;
// merge file request, return url
mergeFile(token: string): Promise<string>;
// hash check request
patchHash<T extends "file" | "chunk">(
token: string,
hash: string,
type: T
): Promise<
T extends "file"
? { hasFile: boolean }
: { hasFile: boolean; rest: number[]; url: string }
>;
}Request control:
import { Task, TaskQueue } from "../upload-core/TaskQueue";
import { Chunk } from "./chunk";
import { ChunkSplitor } from "./chunkSplitor";
import { RequestStrategy } from "./requestStrategy";
export class UploadController {
private requestStrategy: RequestStrategy;
private splitStrategy: ChunkSplitor;
private taskQueue: TaskQueue;
// other properties strategy
// ...
constructor(
private file: File,
private token: string,
requestStrategy: RequestStrategy,
splitStrategy: ChunkSplitor
) {
this.requestStrategy = requestStrategy;
this.splitStrategy = splitStrategy;
this.taskQueue = new TaskQueue();
// other properties strategy
}
async init() {
this.token = await this.requestStrategy.createFile(this.file);
this.splitStrategy.on("chunks", this.handleChunks.bind(this));
this.splitStrategy.on("wholeHash", this.handleWholeHash.bind(this));
}
private handleChunks(chunks: Chunk[]) {
chunks.forEach((chunk) => {
this.taskQueue.addAndStart(new Task(this.uploadChunk.bind(this), chunk));
});
}
async uploadChunk(chunk: Chunk) {
const resp = await this.requestStrategy.patchHash(
this.token,
chunk.hash,
"chunk"
);
if (resp.hasFile) {
return;
}
await this.requestStrategy.uploadChunk(chunk, this.uploadEmitter);
}
private async handleWholeHash(hash: string) {
const resp = await this.requestStrategy.patchHash(this.token, hash, "file");
if (resp.hasFile) {
this.emit.emit("end", resp.url);
return;
}
// according resp.rest to upload the rest chunks
// ...
}
}
Key issue for Backend
Compared to the client, the server faces greater challenges.
How to isolate different file uploads?
In the file creation protocol, the server uses a combination of UUID and JWT to generate a tamper-proof unique identifier, which is used to distinguish different file uploads.
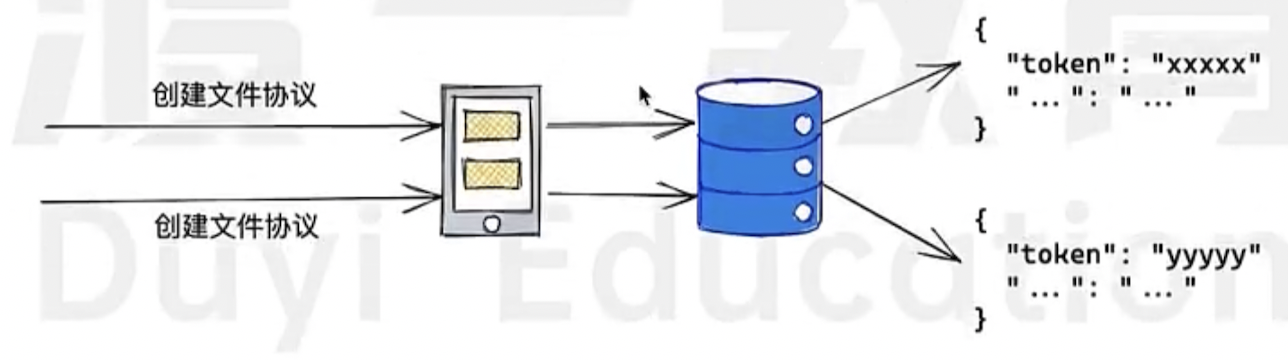
How to ensure chunks are not duplicated?
Here, duplication refers to:
- Not saving duplicate chunks
- Not uploading duplicate chunks
This requires chunks to be uniquely identifiable across files and never deleted.
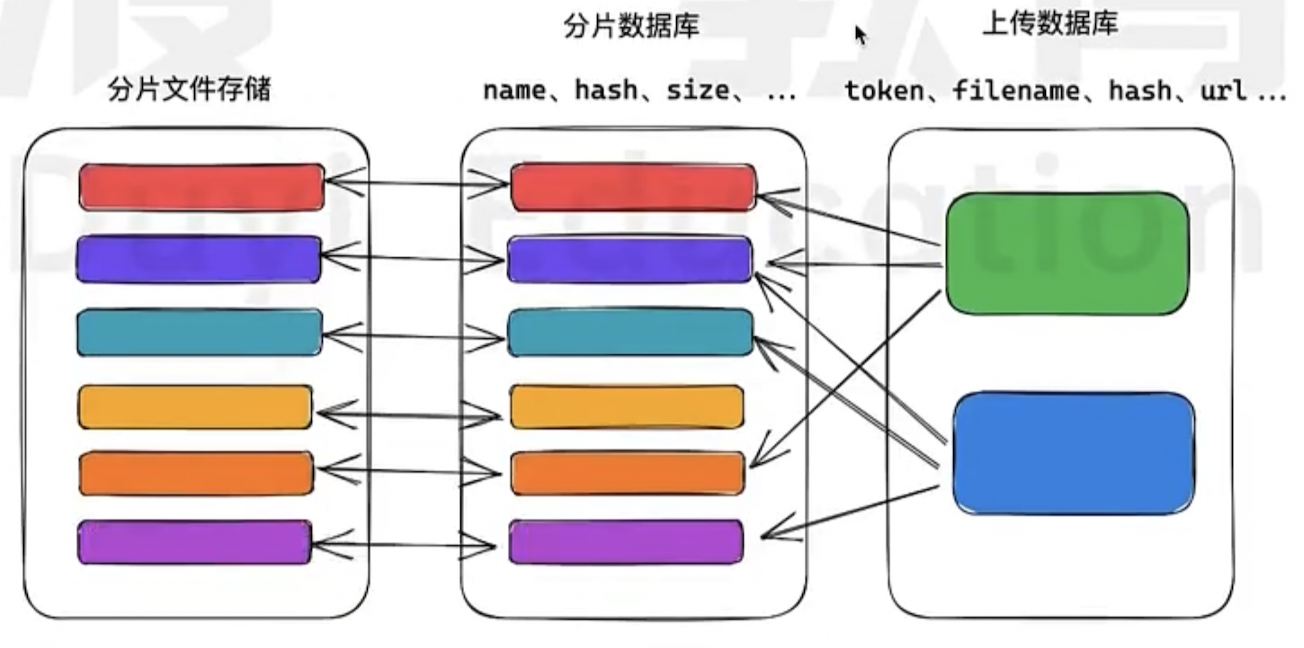
Chunk file storage, chunk database, upload database
Chunk file storage: Store all the chunks across all the files, due to it is possible that two files might share the same chunk
Chunk database: record name, hash, size of each chunk's metadata
Upload database: token filename, hash, url metadata of each file
In other words, the server does not store the merged file but only records the order of chunks within the file.
What exactly does chunk merging do?
Merging causes several problems, the most significant being:
- Extremely time-consuming
- Data redundancy
Therefore, the server does not perform actual merging. Instead, it records the chunks included in the file in the database.
Therefore, during the merge operation, the server only performs simple tasks:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号