
[Design Pattern] Upload big file - 1. Background & Solution overview
Background
Our SaaS platform includes the upload of large files such as company information and meeting videos. Without special handling, the following issues may arise:
- File upload failures caused by network interruptions, program crashes, or other issues, requiring a complete re-upload.
- The same file being repeatedly uploaded by different users, wasting network bandwidth and server storage resources.
Therefore, a solution for large file uploads is needed to address the above problems.
Problem and Solution overview
The common solution for large file uploads is file chunking.
If we consider file uploads as an indivisible transaction, the goal of chunking is to divide a time-consuming large transaction into multiple smaller transactions.
Our company utilizes a BFF (Backend for Frontend) layer to handle file requests from the frontend, so it is necessary to resolve all frontend-backend barriers related to file uploads.
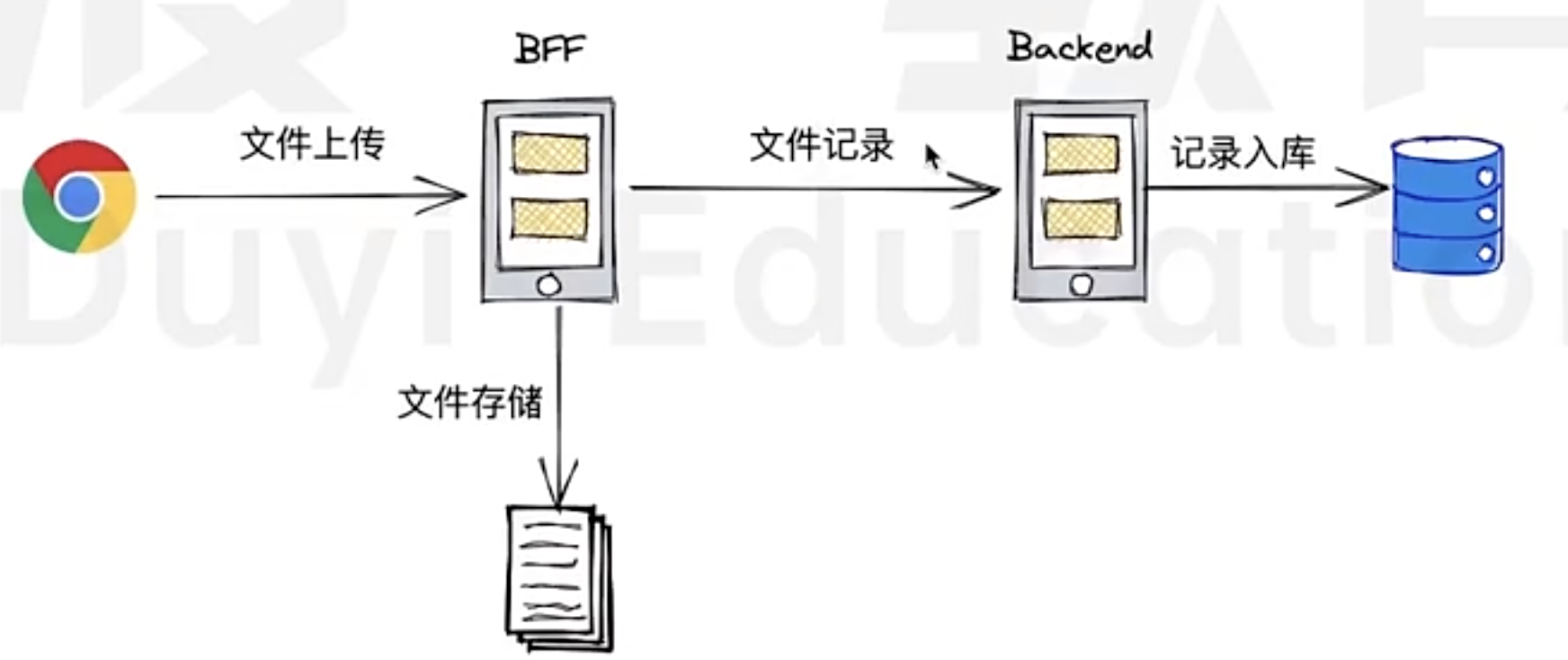
Why need BFF?
It is common that in large company, the data format fro backend and frontend is different; Sometime the requirements from Frontend cannot be 100% fulfilled by just backend (or it might be complex to do in backend); Vice versa;
In such cases, it is good to introduce a middle layer, BFF to handle/recompose the request from Frontend, then send it to backend; Or handle/recompose the response from backend then send it to Frontend.
The main challenges of chunked file uploads are concentrated in:
- Reducing page blocking
- Coordination between frontend and backend
- Code organization
- Complex logic in frontend code
- Complex logic in BFF code
Reducing page blocking
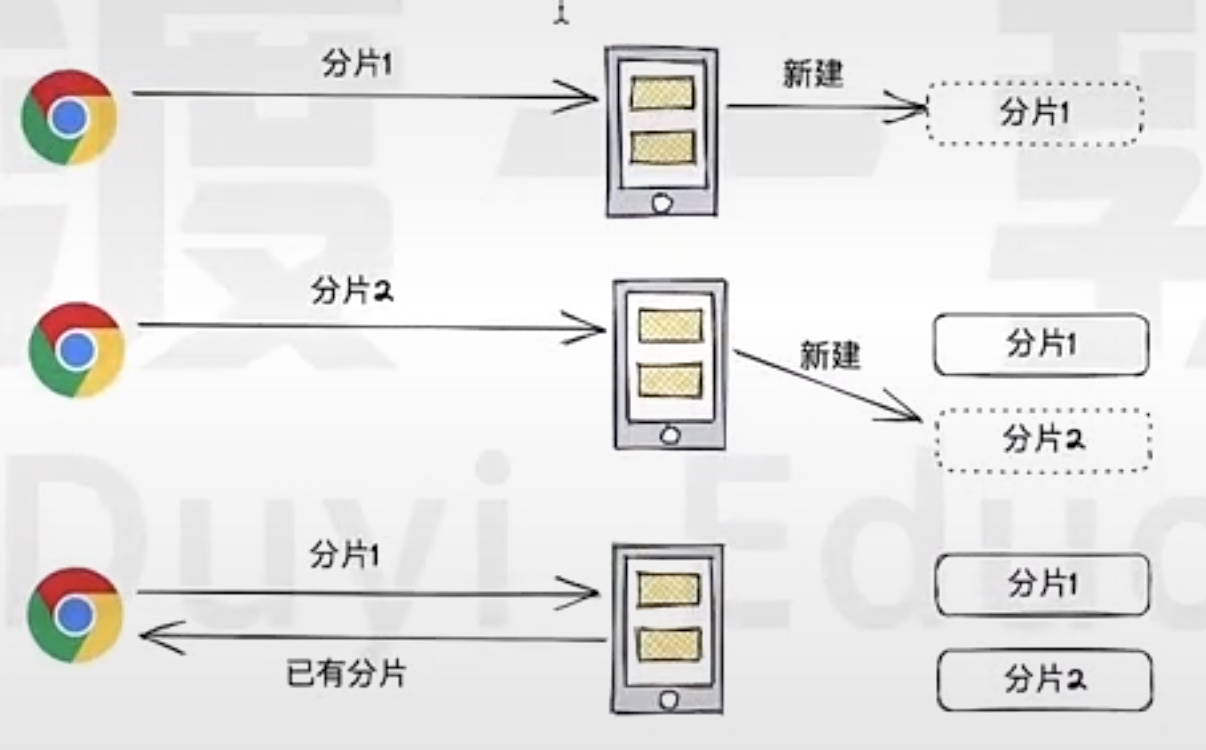
How can the server identify which chunks are identical?
First, we need a precise definition of "identical": chunks are identical if their file content is the same.
However, directly performing a binary comparison of file content is computationally expensive. Instead, we can use a content-based hash for comparison. By calculating the hash value of the chunk's content, the server can efficiently determine whether a chunk matches one previously uploaded.
A hash is an algorithm that converts data of any length into a fixed-length value. Common hash algorithms include MD5 and SHA-1.
In this case, we'll use MD5 for hash computation and utilize the third-party library SparkMD5 to perform the calculations.
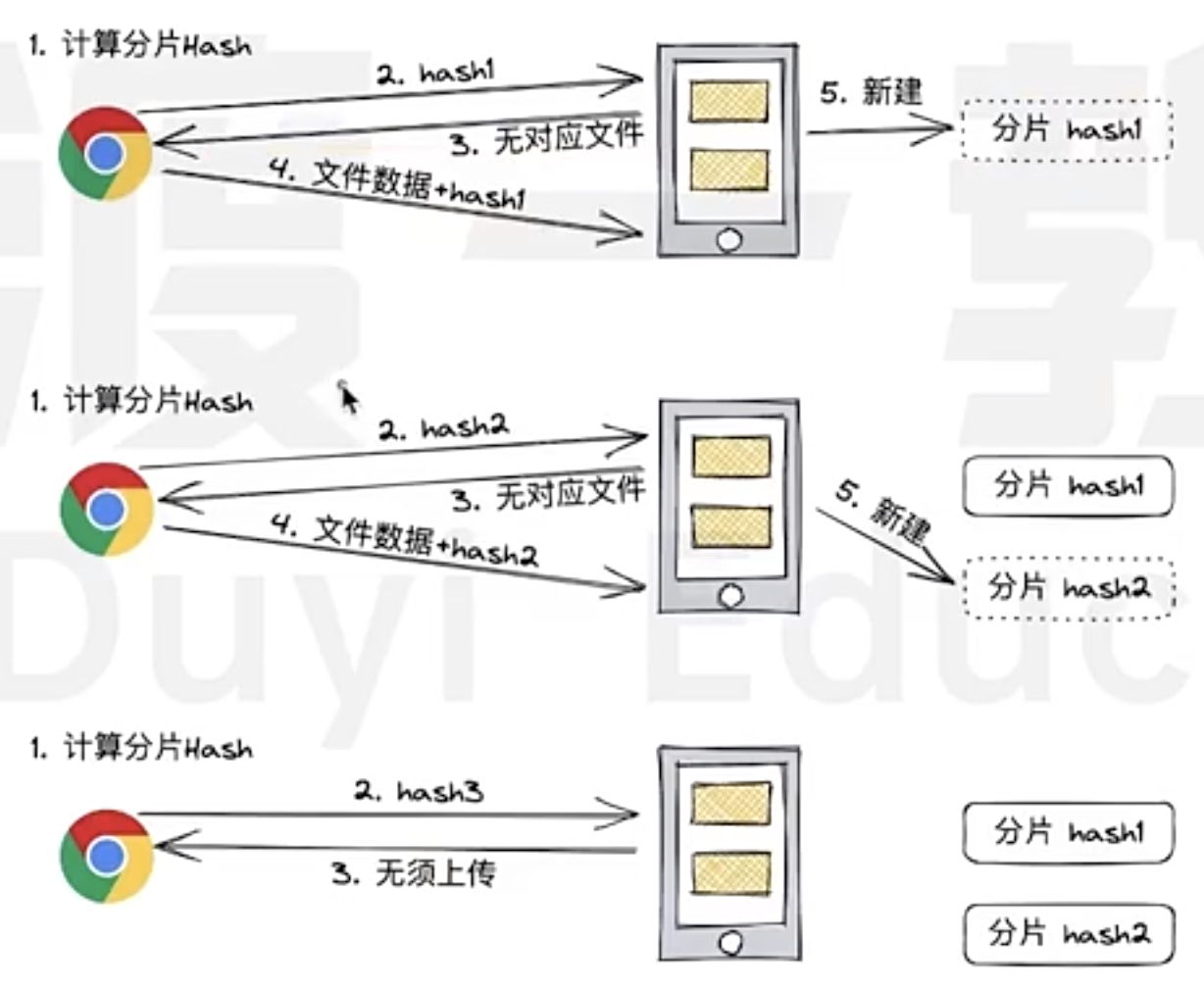
- Frontend caluclates the hash for each chunk, eg
chunk1 - Send the hash to BFF to check whether the hash has been uploaded or not
- If BFF response the hash was not uploaded
- Then Frontend send the chunk data and hash to BFF
- BFF save the chunked file
- Send file path, hah to the Backend to save into database
If in step 2, BFF found the hash already been uploaded, then no need to upload the chunk file again.
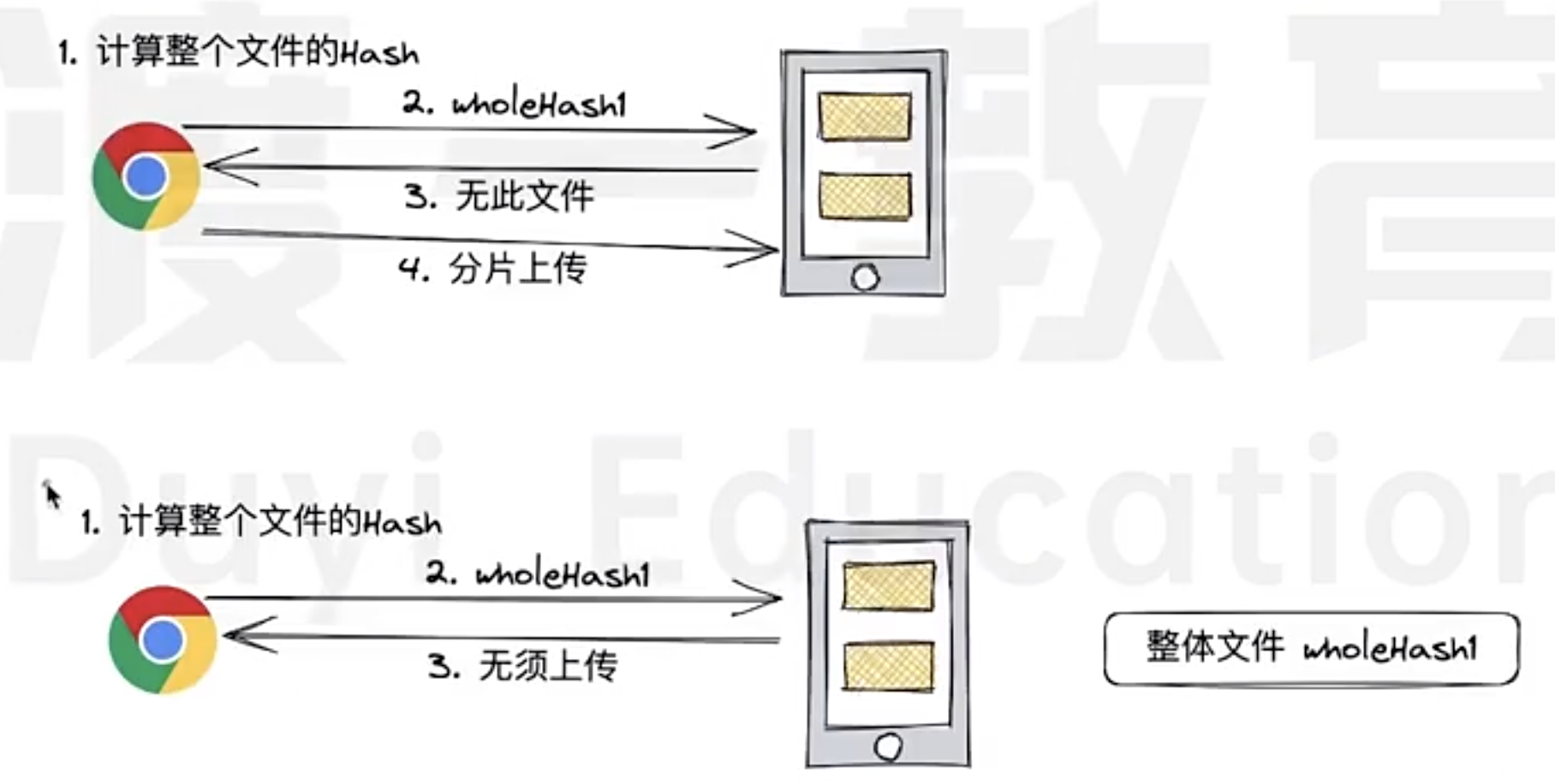
This approach applies not only to individual chunks but also to the entire file. By computing the hash for the entire file, the system can determine whether a file has already been uploaded, further optimizing the process and avoiding redundant uploads.
How to chunk the file in Frontend?
It is simple, using slicemethod directly
file.slice(0, CHUNK_SIZE) // Blob
Clearly, the client needs to handle two important tasks:
- Chunk the file and calculate the hash value for each chunk.
- Compute the hash value of the entire file based on the hash values of all chunks.
However, hash calculation is a CPU-intensive operation. If not handled properly, it can block the main thread for an extended period, leading to performance issues.
The following picture shows the currently design flow
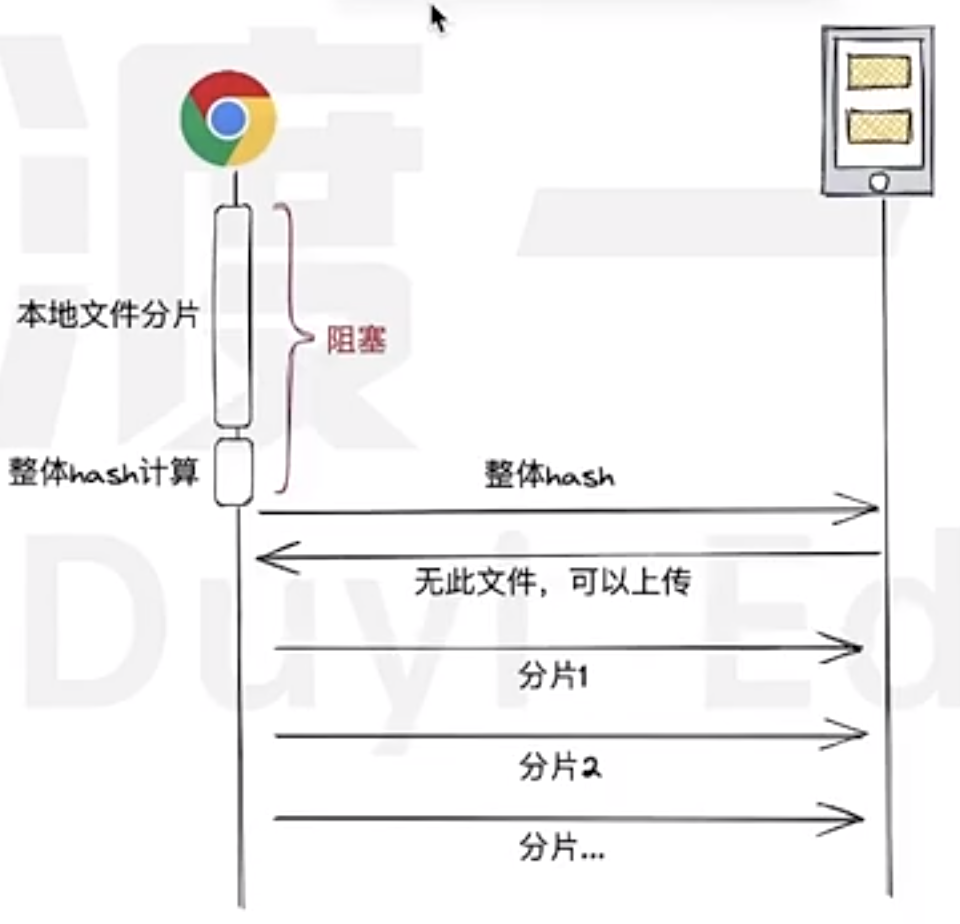
As we can see, there will be a long blocking period for Frontend to calculate hash for each chunked files, then also need to calculate the whole hash after getting each chunked hash.
To address this issue, we can make a bold assumption for large file uploads: the majority of file uploads are new files.
With this assumption:
- We don’t need to wait for the entire file hash to be calculated before starting the upload. Instead, we can upload chunks immediately.
- Chunk processing and upload can be handled using multi-threading and asynchronous operations to maximize efficiency and avoid blocking the main thread.
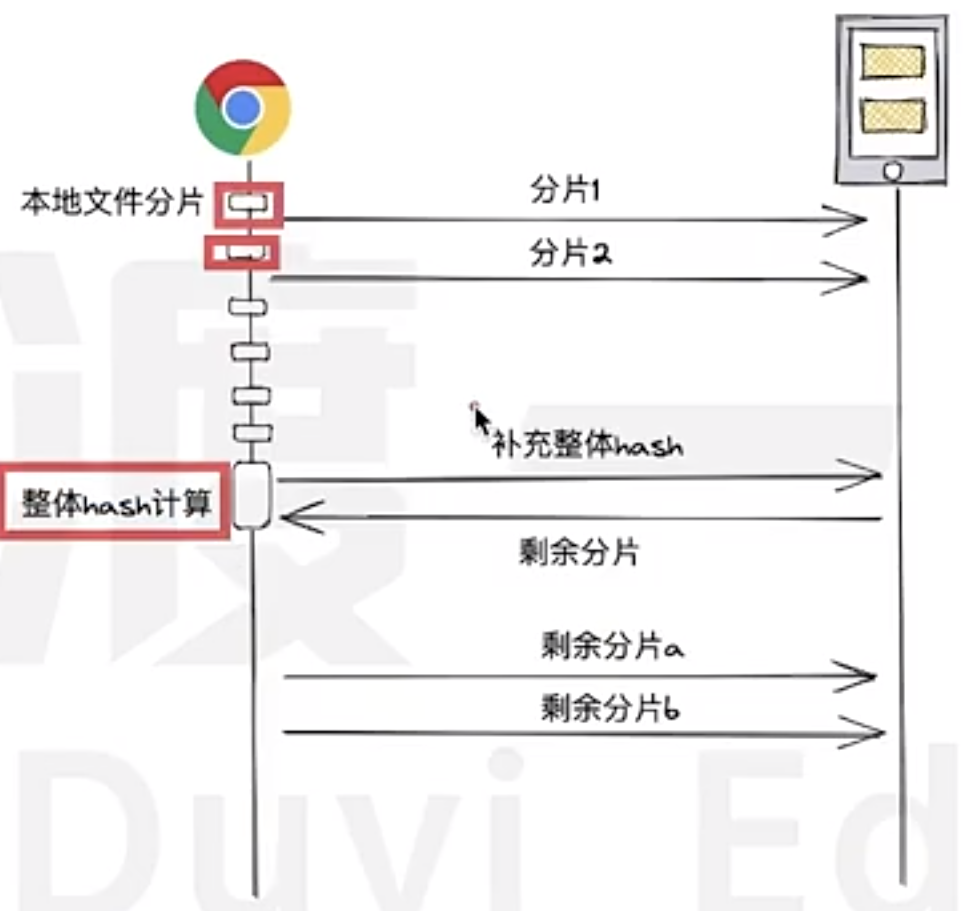
The benefits of this approach are:
-
No page blocking, and upload can start immediately without waiting for the overall hash calculation. Compared to traditional solutions, this significantly reduces the total upload time for new files and eliminates page blocking.
-
For existing file uploads, some redundant requests may occur, but these requests only transmit hash values rather than actual file data. As a result, the impact on network bandwidth and server resources is minimal. Considering that existing file uploads are relatively rare, the overall impact is negligible.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号