[AWS WhitePaper] AWS Storage Services
S3
Usage Patterns
S3 doesn't suit for following usecases:
- POSIX-compliant file system: should use EFS. POSIX -- refer to Linux or Unix files
- Structured data with query: should use RDS, DynamoDB, CloudSearch
- Rapidly changing data
- Archival data
- Dynamic website hosting
Performance
Amazon S3 Transfer Acceleration
Amazon S3 Transfer Acceleration enables fast, easy, and secure transfer of files over long distances between your client and your Amazon S3 bucket. It leverages Amazon CloudFront globally distributed edge locations to route traffic to your Amazon S3 bucket over an Amazon-optimized network path. To get started with Amazon S3 Transfer Acceleration you:
1. must enable it on an Amazon S3 bucket
2. modify your Amazon S3 PUT and GET requests to use the s3- accelerate endpoint domain name (<bucketname>.s3-accelerate.amazonaws.com).
The Amazon S3 bucket can still be accessed using the regular endpoint. Some customers have measured performance improvements in excess of 500 percent when performing intercontinental uploads.
Interfaces
S3 Notifications can be issued to SNS topics, SQS, and Lambda.
Cost Model
Amazon S3 Standard has three pricing components:
1. Storage per GB per month
2. data transfer in or out per GB per month
3. requests per thousand requests per month
There are Data Transfer IN and OUT fees if you enable Amazon S3 Transfer Acceleration on a bucket and the transfer performance is faster than regular Amazon S3 transfer.
If we determine that Transfer Acceleration is NOT likely to be faster than a regular Amazon S3 transfer of the same object to the same destination, we will NOT charge for that use of Transfer Acceleration for that transfer, and may bypass the Transfer Acceleration system for that upload.
Glacier
Usage Patterns

Performance
Typically complete in 3 to 5 hours for terieval job
You can improve the upload experience for larger archives by using multipart upload for archives up to about 40 TB (the single archive limit).
You can even perform range retrievals on archives stored in Amazon Glacier by specifying a range or portion Amazon Web Services.
Scalability and Elasticity
A single archive is limited to 40 TB in size, but there is no limit to the total amount of data you can store in the service
Security
Amazon Glacier allows you to lock vaults where long-term records retention is mandated by regulations or compliance rules.
You can set compliance controls on individual Amazon Glacier vaults and enforce these by using lockable policies.
For example, you might specify controls such as “undeletable records” or “timebased data retention” in a Vault Lock policy and then lock the policy from future edits.
After it’s locked, the policy becomes immutable, and Amazon Glacier enforces the prescribed controls to help achieve your compliance objectives.
Interfaces
Sending notifiction through SNS.
You simply set one or more lifecycle rules for an Amazon S3 bucket, defining what objects should be transitioned to Amazon Glacier and when. You can specify an absolute or relative time period (including 0 days) after which the specified Amazon S3 objects should be transitioned to Amazon Glacier.
- Standard-Infrequent Access Storage Class. Once you selected this check box, specify the number of days after which your backup will be moved to a Standard-IA storage class . This value cannot be less than 30 days due to the Amazon AWS lifecycle policy.
- One Zone-Infrequent Access Storage Class. Once you selected this check box, specify the number of days after which your backup will be moved to a One Zone-Infrequent Access storage class. The default value is 30 days.
- Glacier Storage Class. Once you selected this option, specify the number of days after which to move your data to long-term storage under a Glacier storage class. Specifying a zero value will make your data be immediately archived to Glacier. This option only available if the transition to Standard-IA storage class is not required. When choosing to use Standard-IA storage class using the previous option in this dialog, the number of days specified for a transition to Glacier should exceed the number of days for Standard-IA transition by 30 days.
Note that when using Amazon Glacier as a storage class in Amazon S3 you use the Amazon S3 API, and when using “native” Amazon Glacier you use the Amazon Glacier API.
For example, objects archived to Amazon Glacier using Amazon S3 lifecycle policies can only be listed and retrieved by using the Amazon S3 API or the Amazon S3 console.
You can’t see them as archives in an Amazon Glacier vault.
Cost Model
1. Storage per GB per month
2. Data transfer out per GB per month
3. Requests per thousand UPLOAD and RETRIEVAL requests per month
EFS


Performance
There are two different performance modes available for Amazon EFS:
- General Purpose
- Max I/O
if your overall Amazon EFS workload will exceed 7,000 file operations per second per file system, we recommend the files system use Max I/O performance mode.
If your application can handle asynchronous writes to your file system, and you’re able to trade off consistency for speed, enabling asynchronous writes may improve performance.
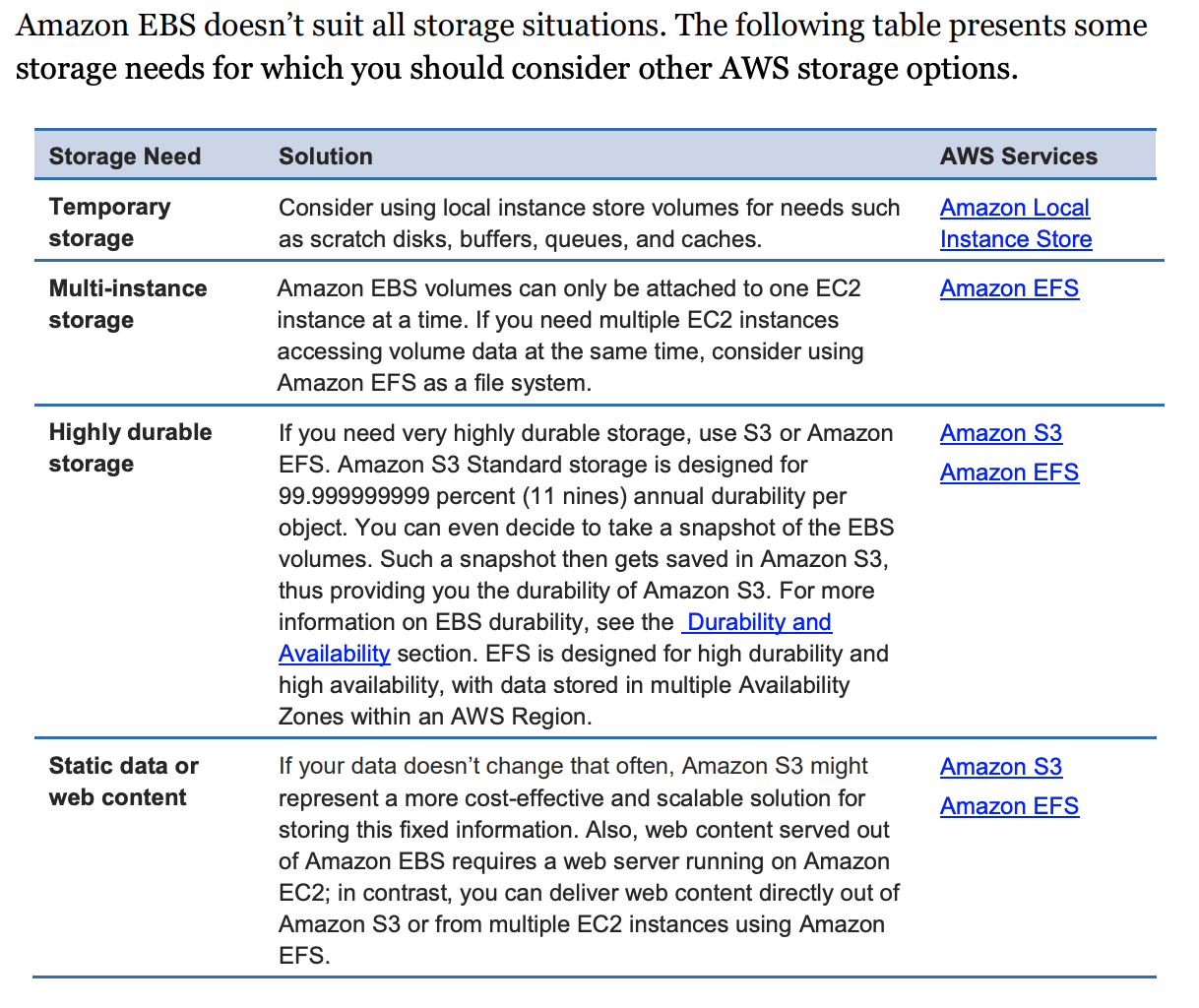
EBS
- solid-state drive (SSD)-backed storage for transactional workloads such as databases and boot volumes (performance depends primarily on IOPS)
- hard disk drive (HDD)-backed storage for throughput-intensive workloads such as big data, data warehouse, and log processing (performance depends primarily on MB/s).
Performance
- SSD-backed storage volumes offer great price/performance characteristics for random small block workloads, such as transactional applications
- HDD-backed storage volumes offer the best price/performance characteristics for large block sequential workloads
- st1 & sc1 can not be used as a boot volumes
EC2 instances (m4, c4, x1, and p2) are EBS-optimized by default. EBS-optimized instances deliver dedicated throughput between Amazon EC2 and Amazon EBS, with speeds between 500 Mbps and 10,000 Mbps depending on the instance type.
Durability and Availability
- EBS snapshots are incremental, point-in-time backups, containing only the data blocks changed since the last snapshot
- To maximize both durability and availability of Amazon EBS data, you should create snapshots of your EBS volumes frequently.
- Because an EBS volume is created in a particular Availability Zone, the volume will be unavailable if the Availability Zone itself is unavailable. A snapshot of a volume, however, is available across all of the Availability Zones within a Region, and you can use a snapshot to create one or more new EBS volumes in any Availability Zone in the region.
- EBS snapshots can also be copied from one Region to another, and can easily be shared with other user accounts.
- Thus, EBS snapshots provide an easy-to-use disk clone or disk image mechanism for backup, sharing, and disaster recovery.
Scalability and Elasticity
Resize a EBS volume:
- Detach the original EBS volume
- Create a snapshot of the orginal EBS volume's data in Amamzon S3.
- Create a new EBS volume from the snapshot but specify a larger size than the orginal volume
- Attach the new, larger volume to your EC2 instance in place of the original
- Delete the original EBS volume.
AWS Storage Gateway
With gateway-cached volumes, you can use Amazon S3 to hold your primary data, while retaining some portion of it locally in a cache for frequently accessed data.
Gateway-stored volumes store your primary data locally, while asynchronously backing up that data to AWS. These volumes provide your on-premises applications with low-latency access to their entire datasets, while providing durable, off-site backups.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号