[Cloud Architect] 3. Business Objectives
Lesson Outline
- Uptime
- Downtime
- RTO
- RPO
- Disaster Recovery
Lesson Objectives
You will be able to:
- Calculate availability in terms of up and down time
- Set reasonable business metrics for RTO and RPO
- Make determinations on what types of DR plans a company needs
- Implement a DR plan
In this lesson, you will examine Business Objectives including uptime, RTO, RPO and Disaster Recovery.
You will learn about these topics and how they apply to the applications that you design and build. A solid understanding of these topics will allow you to fully understand the metrics that your company is committing to and use this understanding to inform your design decisions.
Meeting Different Business Objectives
As you learn these concepts, it is important to gauge how much effort and cost will be involved in meeting different business objectives.
Communicating these numbers will help keep the whole company centered around common and achievable goals.
Setting unrealistic or unachievable goals can quickly lead to poor morale and missed deadlines.
Before committing to a business objective, ensure that you have an idea of how to build, run, monitor and maintain a system that can achieve the desired metrics, and make sure that the rest of the business understands the resource that will be required to do so.
In this fashion, it is key to get all parts of the company to work together to set these goals. These goals are so critical to success and potentially costly to achieve that they often must be set at the highest levels of the company.
Uptime
Uptime is a measure of how much time an application or service is available and running normally. Uptime is often measured as a percentage, usually in the "number of 9s" vernacular. For example, "4 9s" refers to a service being available for 99.99% of a time period.
Services that offer Service Level Agreements (SLAs) typically start at 99% and get more stringent from there. 99.9% is a common SLA. The more "9s" an SLA offers, the more difficult and costly it is to achieve.
You must ask yourself how much effort you are willing to put in and how much your company is willing to pay before proceeding into the territory of 4 9s or beyond.
Uptime Calculation
Allowed downtime = (30 days 24 hours 60 minutes) - (30 days 24 hours 60 minutes * SLA percentage)
99% uptime = 7.3 hours of allowed downtime in a month
99.9% uptime = 0.72 hour of allowed downtime in a month
Downtime
Downtime is the opposite of uptime, but its definition (especially in a contract) is something to carefully consider. Once a contract is signed, it can be very difficult to renegotiate. Even as your products become more complex, your contracts likely stay the same.
Excused downtime is a wise thing to include in your SLA. This defines special time where you can have downtime that will not impact your SLA. Scheduling a daily, weekly or monthly recurring time period where you can perform maintenance makes meeting an SLA drastically easier.
Another good thing to include is a clause to allow for degraded performance. This allows non-essential portions of your platform to be down without counting against your SLA. If there are components of your system that are "nice to haves," consider degrading gracefully and excluding these from your SLA.
Also if you are using third-party service which out of you control, you can choose a thrid-party who provide it SLA.
Then in your contract, you can specify that you only use third parties with a minimum SLA threshold, but that you. are not responsible for the third party downtime.... Well, at least you can try... Customers might not agree with that.

Make sure you cover that case in your agreement either.
Downtime Exceptions
Scheduled Maintenance
Agreed upon time where your platform may be down without counting toward your SLA.
Degraded Service
Not all services or feature of your application may be critical. You may be able to deem certain parts of your application non-critical and allow your service to gracefully degrade if these features are not available.
Force Majeure
Some things cannot be avoided or planned for. Natural disasters or pandemics may trigger certain exclusions in your SLA.
Calculating Availability
Write up an SLA for your platform that breaks down acceptable amounts of downtime for your application and for third party services separately. Also define periods of excused downtime and caveats for reduced functionality of non-critical components.
ABC Company Hosted Applications
ABC Company shall provide general platform uptime of 99.9%. This shall exclude a regular maintenance window from 1am - 5am CST every Sunday, as well as windows from 1am - 5am on other days provided that ABC provides 24 hours of notice.
ABC Company Critical Third-Party Components
Some components of our system are beyond our control, and thus, we can only pass through the provided SLA of these vendors. We only work with vendors who provide an SLA of 99.9% or better for all critical services.
ABC Company Non-Critical Components
Those components deemed non-critical (listed below) are subject to a 95% uptime SLA. These components are not core to our offering, but provide certain "nice to have" functionality. In cases where these services are not available, our platform shall continue to operate and provide core functionality as normal.
Recovery Time Objective (RTO)
Recover Time Objective (RTO) is the maximum time your platform or service can be unavailable. If your platform is offline from noon until 5:00pm and you have a 4 hour RTO, then you have failed to maintain your RTO.
When setting an RTO, be sure to consider the many items that go into meeting an RTO. What are the things that you will need to have in place to achieve your RTO?
If your RTO is less than 72 hours, you will need to have folks available on the weekend to fix your system.
If it is less than 8 hours, you will need people available in the middle of the night.
Not only will you need people available at these off-hour times, but they will need to have a wide range of knowledge on your systems, access to the systems, and the trust of the company to make critical changes on their own.


Recovery Time Objective (RTO)
When determining what type of RTO you can support, there are many factors to take into consideration. By not accounting for components that impact your RTO, you put your ability to meet the obligation at risk.
Let's consider the situation where a database runs out of disk space in the middle of the night. Some of the items to consider are:
- Problem happens
- An amount of time passes before an alert triggers
- Alert triggers on-all staff
- On-call staff may need to get out of bed, get to a computer, log in, log onto VPN
- On-call staff starts diagnosing the issue
- Root cause is discovered
- Remediation started
- Issue fixed
Estimate how much time each of the above is likely to take. Use that data to create a timeline of the incident. What is the RTO of this incident?
Example Answer:
Recovery Time Objective (RTO)
- 00:00 - Problem happens (0 minutes)
- 00:05 - An amount of time passes before an alert triggers (5 minutes)
- 00:06 - Alert triggers on-all staff (1 minute)
- 00:16 - On-call staff may need to get out of bed, get to computer, log in, log onto VPN (10 minutes)
- 00:26 - On-call staff starts diagnosing issue (10 minutes)
- 00:41 - Root cause is discovered (15 minutes)
- 00:46 - Remediation started (5 minutes)
- 00:56 - Remediation completed (10 minutes)
Total time: 56 minutes
An RTO of one hour for this incident would be reasonable.
My Answer:
Problem happens
An amount of time passes before an alert triggers + 1 min
Alert triggers on-all staff. + 1min
On-call staff may need to get out of bed, get to a computer, log in, log onto VPN. + 30min
On-call staff starts diagnosing the issue + 30 min
Root cause is discovered + 60 min
Remediation started + 20min
around 2 hours and 30 mins
Recovery Point Objective (RPO)
Recovery Point Objective (RPO) is the maximum amount of time that your system can lose data for.
RPO is not tied to whether your system is available, it is a measure of the window of time that you may lose data in.
If you take a database snapshot at midnight every day and you have a data corruption issue at 7:00am requiring you to restore from backup, you have a 7 hour RPO.
It may take you until 8:00am to restore service, but as long as your data loss stops at 7:00am, that is when your RPO window closes.
Disaster Recovey
RTO and RPO numbers apply to localized outages, but when setting your RTO and RPO, you must take into account worst case scenarios. The term Disaster Recover is used to describe a more widespread failure. In AWS, if you normally run your services in one region, a large enough failure to make you move your system to another region would be a Disaster Recovery (DR) event.
Disaster Recovery usually involves the wholesale moving of your platform from one place to another. Outside of AWS, you might have to move to a backup data center. Inside AWS, you can move to a different region. Disaster recovery is not something you can do after an incident occurs to take down your primary region. If you have not prepared in advance, you will have no choice but to wait for that region to recover.
To be prepared ahead of time, consider all of the things you will need to restart your platform in a new home. What saved state do you need, what application software, what configuration information. Even your documentation cannot live solely in your primary region. All of these things must be considered ahead of time and replicated to your DR region.
What do you need?
- Database backups
- Server images
- Your code
- Server configurations (and instance types)
- Any other data repositories
- Network configurations
- Documentation
- IP whitelisting

- Make a checklist: what to do, how to do, step by step
- It should be clear enough, for any person can do so by following the steps
- Language should be clear, with figures
- Practice DR again and again, for example, every 3 months... to make sure Docuements is up to date
- Don't cheat, follow docuementation instead of going back to check existing configuration.
Types of DR plans
- Cold standby
- Pilot light
- Warm standby
- Hot standby
https://www.cnblogs.com/Answer1215/p/15156783.html
Disaster Recovery In AWS
In AWS this typically means moving your service between regions. If you are not running active/active applications, you will need to prepare and plan in order to be able to bring up your platform in another AWS region.
Some services such as DynamoDB provide simple options for this. Services like CloudFront also have features such as Origin Groups that allow for automatic failover between AWS regions.
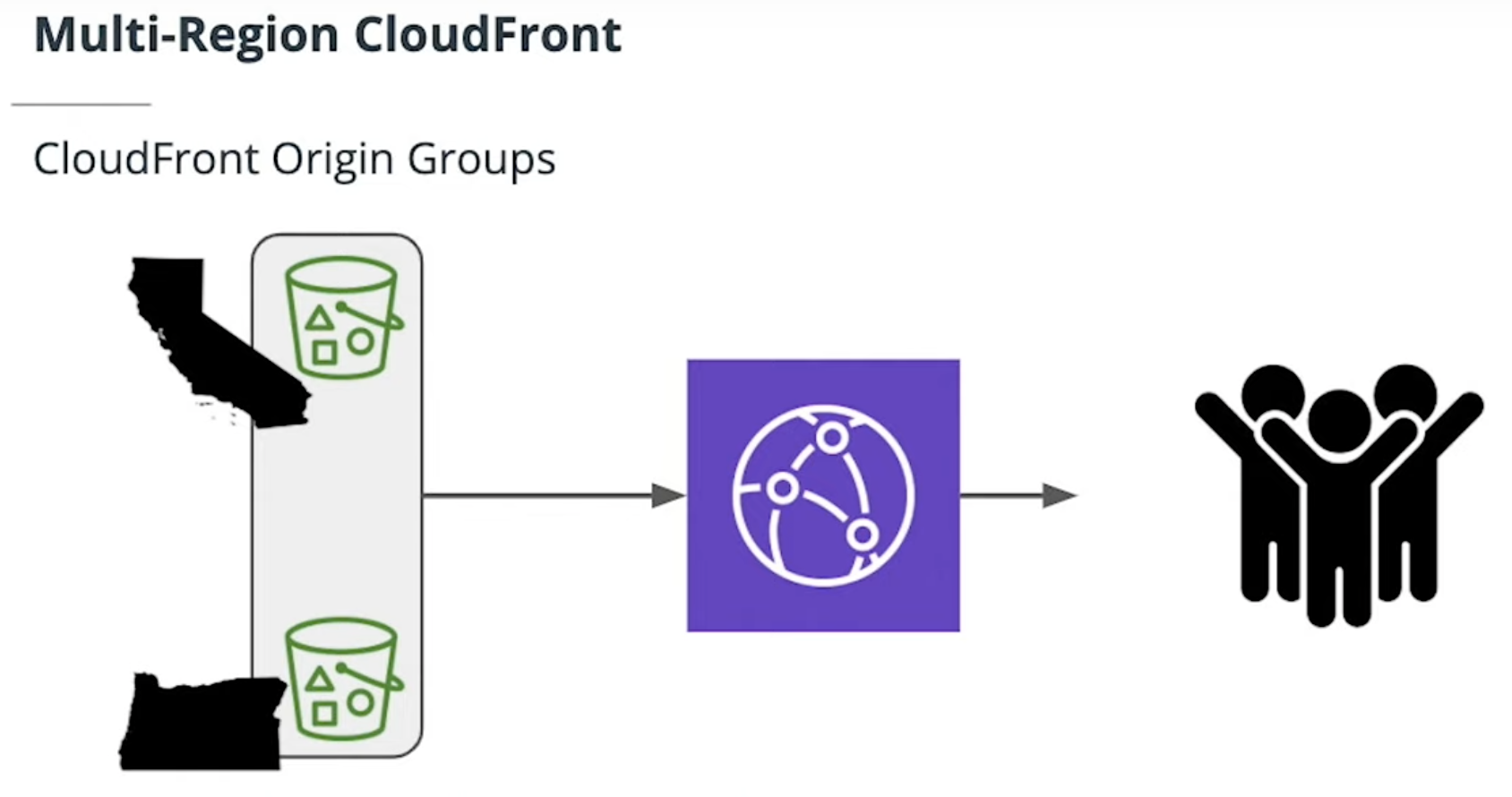
An origin group includes two origins (a primary origin and a second origin to failover to) and a failover criteria that you specify.
You create an origin group to support origin failover in CloudFront.
When you create or update a distribution, you can specifiy the origin group instead of a single origin, and CloudFront will failover from the primary origin to the second origin under the failover conditions that you've chosen.
https://docs.aws.amazon.com/cloudfront/latest/APIReference/API_OriginGroup.html

Global tables build on the global Amazon DynamoDB footprint to provide you with a fully managed, multi-region, and multi-active database that delivers fast, local, read and write performance for massively scaled, global applications. Global tables replicate your DynamoDB tables automatically across your choice of AWS Regions.
Global tables eliminate the difficult work of replicating data between Regions and resolving update conflicts, enabling you to focus on your application's business logic. In addition, global tables enable your applications to stay highly available even in the unlikely event of isolation or degradation of an entire Region.
https://aws.amazon.com/dynamodb/global-tables/
Lesson Objectives
You will be able to:
- Calculate availability in terms of up and down time
- Set reasonable business metrics for RTO and RPO
- Make determinations on what types of DR plans a company needs
- Implement a DR plan
Business objectives are a great conduit to have prioritization and cost discussions with the other functions of a business. Keeping communication open and setting reasonable, realistic goals is vital. AWS has all of the tools you will need to meet these objectives, but there will still be a cost in terms of time, money and resources.
Glossary
- Force Majeure: Term describing an event or circumstance that is completely unavoidable.
- IP whitelisting: Allowing specific IP addresses only to access some resource.
- Pilot light: Old appliances such as furnaces or water heaters had a small flame that was always burning that was used to ignite a larger flame when needed.
- Regulated industries: Industries where the government sets strict rules and guidelines for data storage or operational practices.
- Uptime: The time where you application is available and correctly functioning.
- Downtime: The time where your application is not available service it's critical functions during normal business hours.
- RTO: Recovery Time Objective, or the time that your application can be down for a given incident.
- RPO: Recover Point Objective, or a measure of how long of a period that data can be lost.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号