
[AWS] ElasticSearch, Sync data between DynamoDB and ElasticSearch by using DyanmoDB Stream
Full-Text Search
- Find images by names
- What this usually means
- Support search by any field
- Tolerate typos
- Support highlight
- Rank search result
So when we upload a image, we save the information into DynamoDB already.
Now if we want to support full-text search, we also need to save the data into ElasticSearch.
Which means we will have two databases. And we need to keep both database in sync! Sounds simple but actually NOT AT ALL!
- Command and Query Responsibillity Segregation (CQRS)
- Command means a write operation
- Command means a write operation
- Query means a read operation
- Command means a write operation
Decouple DynamoDB Updates
- Ideally
- Decouple updating both datastores
- We should have a stream of updates from DynamoDB
- Asynchronously execute each update
- Why is this better?
- User is decoupled from the updating ElasticSearch operation
- ElasticSearch will be updated eventally when DynamoDB finish udpating
- Worst case scenario, Elasticsearch is updated a bit later.
Solution
- Kinesis
- DynamoDB Stream
Kinesis
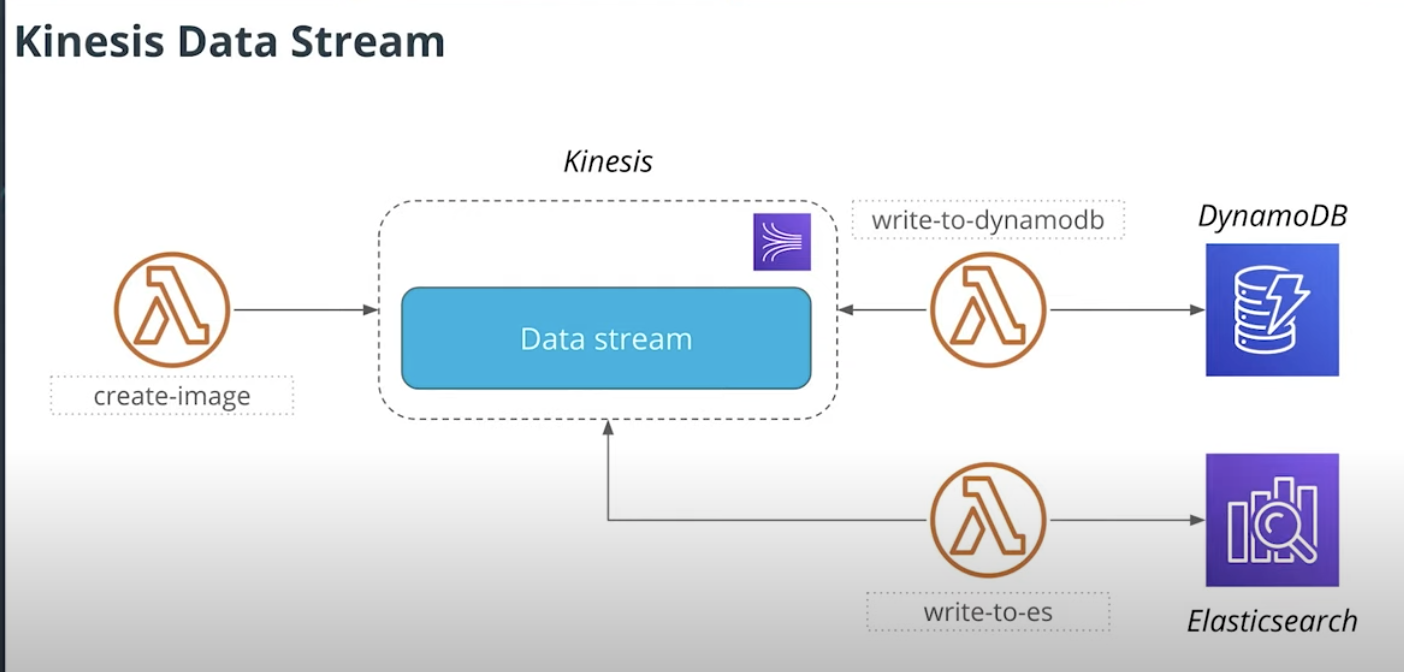
When image uploaded, will write to Kinesis stream.
- Then one `write-to-dynamodb` lambda function will read from stream and add record to DynamoDB
- Another lambda function`write-to-es` will also read from Kinesis stream and write record to Elasticsearch
DynamoDB Stream
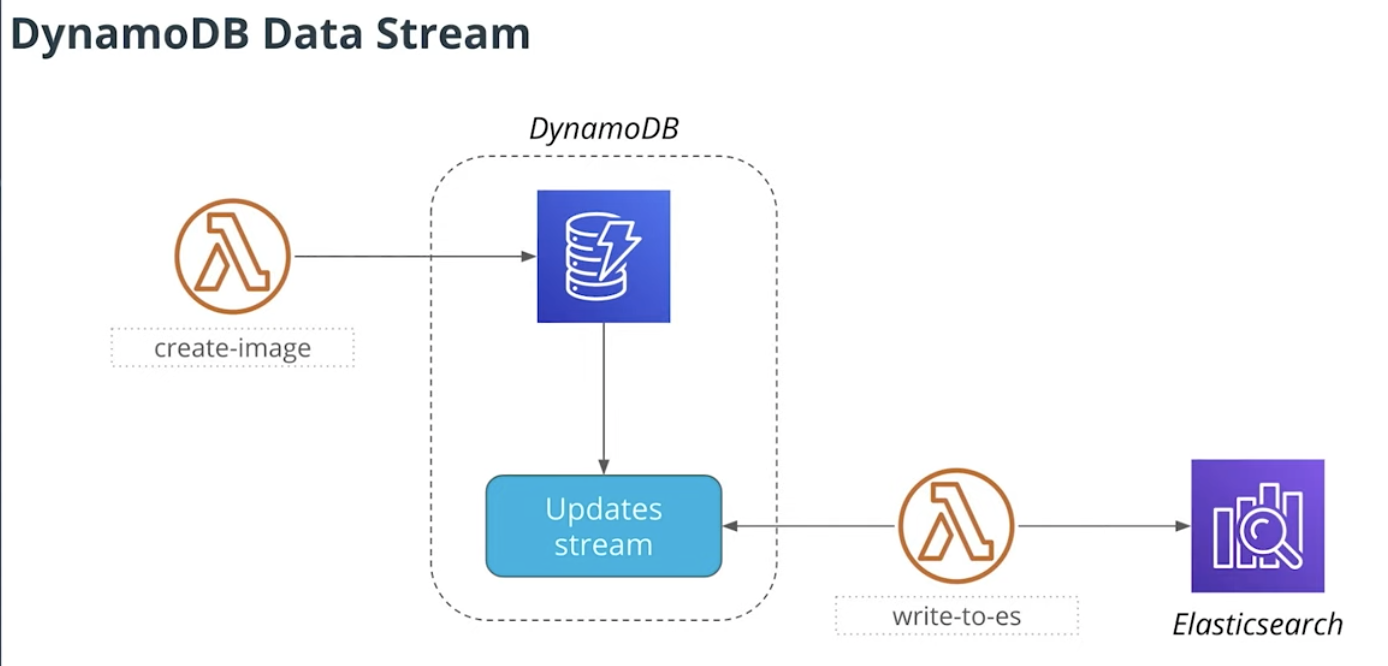
When we write data to DynamoDB
- We will config DynamoDB Stream
- and `write-to-es` lambda function will read from the DynamoDB Stream
- Then write data to ElasticSearch
Scaling a Data Stream
A data stream is split into shards, and every shard stores a subset of data. Different shards can spread across multiple hosts, which allows to scale up a data stream.
Every record that is added to a data stream has key and data, A key of a data record is used to decide what shard it will be written to. All items with the same key will be written to the same shard and will be available in the same order they were added to a stream.
A single stream is splited into multiple parts, each part is called a shard
The way a shard is selected: Every record has a key, key is hased, those hased key is used to select a shard.

How to Enable Stream
In serverless.yml: resources


DynamoDB JSON

Elasticsearch
You can read more about Elasticsearch in the official documentation.
You can download and run Elasticsearch yourself, or use one of the managed Elasticsearch solutions. AWS provides a managed Elasticsearch service that we will use in this course, but there are other companies like Elastic that provide similar service.
Here is how to create an Elasticsearch client:
import * as elasticsearch from 'elasticsearch'
import * as httpAwsEs from 'http-aws-es'
const esHost = process.env.ES_ENDPOINT
const es = new elasticsearch.Client({
hosts: [ esHost ],
connectionClass: httpAwsEs
})
Here is how to store a document in Elasticsearch
await es.index({
index: 'images-index',
type: 'images',
id: 'id', // Document ID
body: { // Document to store
title: 'title',
imageUrl: 'https://example.com/image.png'
}
})
Kibana Access
AWS provides multiple ways to restrict access to a Kibana dashboard. One option to restrict access to Kibana would be to use Amazon Cognito, a service for authentication, authorization, and user management.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号