
HASH H.CLEAR()的作用
已经用HASH 计算衍生变量好几天了,今天突然觉悟般的领会到hash 里面h.clear的作用。
有这样的一个数据(伪造):几千万条记录,report_id是每个人的唯一标识,每个人贷款多笔,querier是查询机构,query_reason是审批原因,还有等等数据;
需求是:计算每个人贷款审批机构查询次数、信用卡审批查询次数
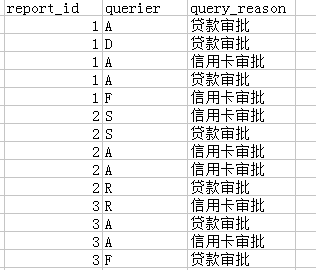
逻辑:最直接的思路是分组计算 SQL结合DATA步都可以实现,但是数据量比较大时,计算起来就比较慢了,如何使用HASH计算呢
首先建立一个索引
DATA A (INDEX=(REPORT_ID));
SET A;
RUN;
/*计算*/
DATA B;
SET A;
BY REPORT_ID;/*对应前面建立的索引*/
/*初始化hash*/
IF _N_=1 THEN DO;
DCL HASH H_Q(ORDERED:'YES');
DCL HITER HI_Q('H_Q');
H_Q.DEFINEKEY('QUERIER');/*以查询机构为key*/
H_Q.DEFINEDATA('LN','LND');
H_Q.DEFINEDONE();
CALL MISSING(LN,LND);
END;
/*对每个report_id计算每种机构的个数*/
IF H_Q.FIND() ^=0 THEN DO;
LN=0;
LND=0;
IF QUERY_REASON='贷款审批' THEN LN+1;
IF QUERY_REASON='信用卡审批' THEN LN+1;
H_Q.ADD();
END;
ELSE IF H_Q.FIND() =0 THEN DO;
IF QUERY_REASON='贷款审批' THEN LN+1;
IF QUERY_REASON='信用卡审批' THEN LN+1;
H_Q.REPLACE();
END;
/*取遍历的每个report_id的最后一条观测*/
IF LAST.REPORT_ID THEN DO;
LN_T=0;
LND_T=0;
/*遍历*/
RC=HI_Q.FIRST();
DO WHILE(RC=0);
IF LN>0 THEN LN_T+1;
IF LND>0 THEN LND_T+1;
RC=HI_Q.NEXT();
END;
H_Q.CLEAR();/*强调一下这里H_Q.CLEAR()的作用:*/
OUTPUT;
END;
/*强调一下这里H_Q.CLEAR()的作用:如果没有的话,计算出来的LN_T、LND_T是对不同的report_id累加的结果*/
/*理解的HASH的精华都在这里,这是比较简单的逻辑计算,当然还可以结合时间和其他变量简单快捷的计算很多的衍生变量*/
/*完美~*/

