非均衡
2019年11月5日 天气晴
给自己的忠告:不要试图去逃避,那些以前自以为躲过的坑,在后面的路上默默埋好了伏笔,所以该跳就跳,反正躲不过的。
西瓜书:类别不平衡问题是指分类任务中不同类别的训练样例数目差别很大的情况。(本书假定正例少,反例多)
几率y/(1-y)反映了正例可能性和反例可能性之比值。分类器决策规则为:
若 y/(1-y)>1则预测为正例。(式3.46)
当训练集中正反比例的数目不同时,令m+表示正例数目,m-表示反例数目,则观测几率是m+/m- .
通常假设训练集是真实样本总体的无偏采样,因此观测几率就代表了真实几率,于是,只要分类器的预测几率高于观测几率就应该判定为正例,即
若 y/(1-y) > m+/m- 则预测为正例。
类别不平衡学习的一个基本策略---再缩放(rescaling):
y' / (1-y')=y/(1-y) * (m-/m+) (式3.48)
现在技术上有三种做法:
第一类是直接对训练集里的反类样例进行欠采样(undersampling),即去除一些反例使得正反例数目接近,然后再进行学习;
第一类是直接对训练集里的正类样例进行过采样(oversampling),即增加一些正例使得正、反例数目接近,然后再进行学习;
第三类是直接基于原始训练集进行学习,但是在用训练好的分类器进行预测时,将式子嵌入到其决策过程中,称为阈值移动(threshold-moving)
参考链接:https://yq.aliyun.com/articles/584909
摘要:CNN对训练集样本不平衡问题很敏感。(论文链接:http%3A//www.diva-portal.org/smash/get/diva2%3A811111/FULLTEXT01.pdf)
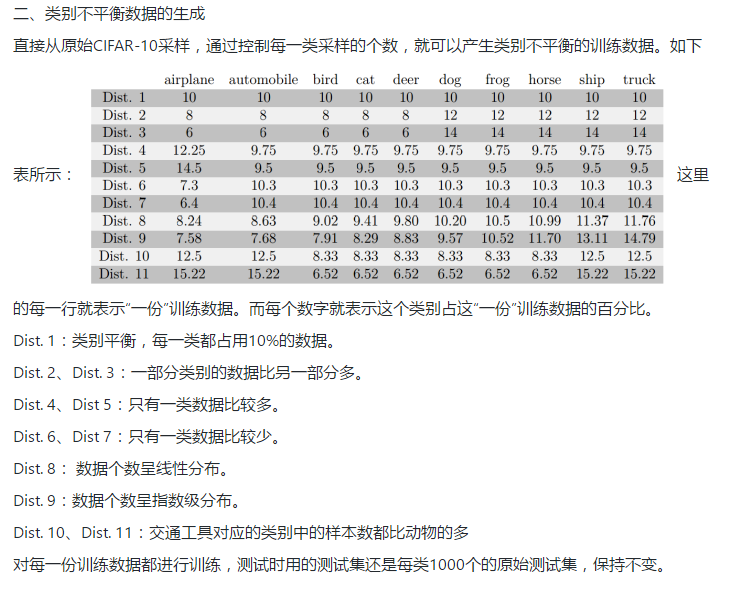
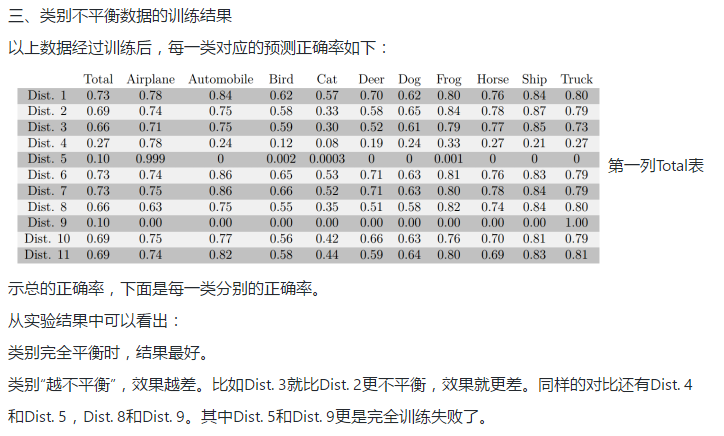
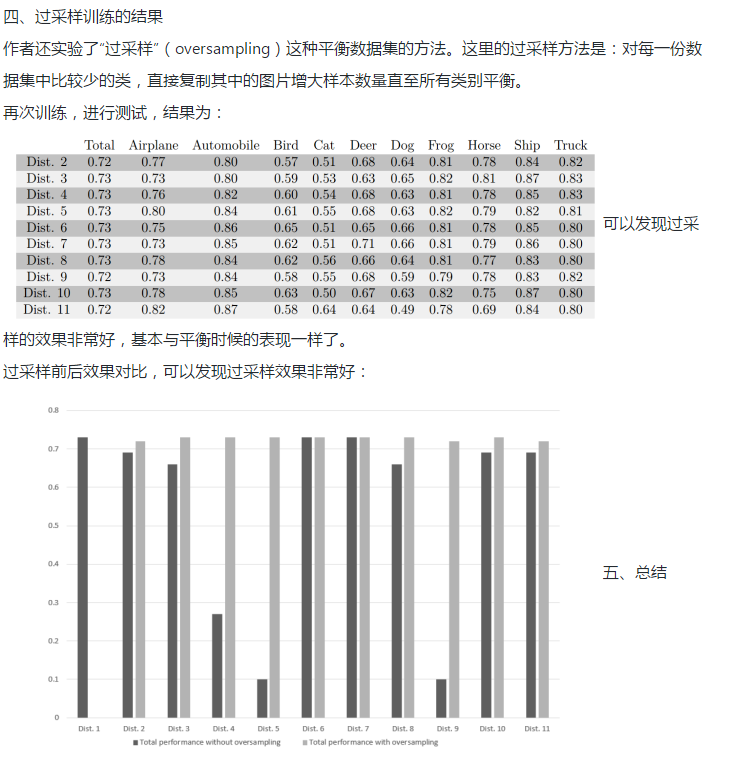
CNN确实对训练样本中类别不平衡的问题很敏感。平衡的类别往往能获得最佳的表现,而不平衡的类别往往使模型的效果下降。如果训练样本不平衡,可以使用过采样平衡
样本之后再训练。这确实是一个“经验主义”的结论,但多少给我们平常训练CNN模型带来一些启发和帮助。
如何解决数据不平衡问题?(https://www.baidu.com/link?
url=dG930Wgj8gRWERgRMXzzoM8EKfvzNpMH9s51FFnU7YAbq_74cjVeYwX0FKhOmD6eu4RgzlCAPPAOqz71y7db5q&wd=&eqid=db752a8c000016ac000000055dc0df00
)


其他方法:https://www.jianshu.com/p/e83a3ce2c837
https://blog.csdn.net/ericcchen/article/details/80102987
https://blog.csdn.net/Tcorpion/article/details/78175269
CNN调参:利用损失函数权重处理不平衡数据集
https://blog.csdn.net/Cxiazaiyu/article/details/81876142
通过class_weighting依次设置不同类别的权重。 但是权重的设置很有讲究,并非给小的物体设置权重越大越好,否则神经网络会把(低权重的)大物体也识别成(高权重的)小物体。比如给交通灯过高的权重,让神经网络把路也识别成了交通灯。如果设置class_weighting从零训练,等训练好后发现权重设置不合理导致训练结果不满意,又要重新设置权重,训练成本高。
可以通过如下训练技巧调整:
首先不加权重,让神经网络可以比较准确地识别主要物体。 再设置几组不同的class_weighting进行finetune,比较选取能够获得最好结果的权重。
非均衡分类问题评价指标:
非均衡分类问题是指在分类器训练时正例数目和反例数目不相等(相差很大)。该问题在错分正例和反例的代价不同时也存在。本文提供几种度量分类器性能的方法
1 预测准确率
预测准确率指的是预测正确的样本占所有测试样本的比率
2正确率与召回率
正确率指的是预测为正例且预测正确的样本占预测为正例的样本的比率 召回率指的是预测为正例且预测正确的样本占真正正例的样本的比率
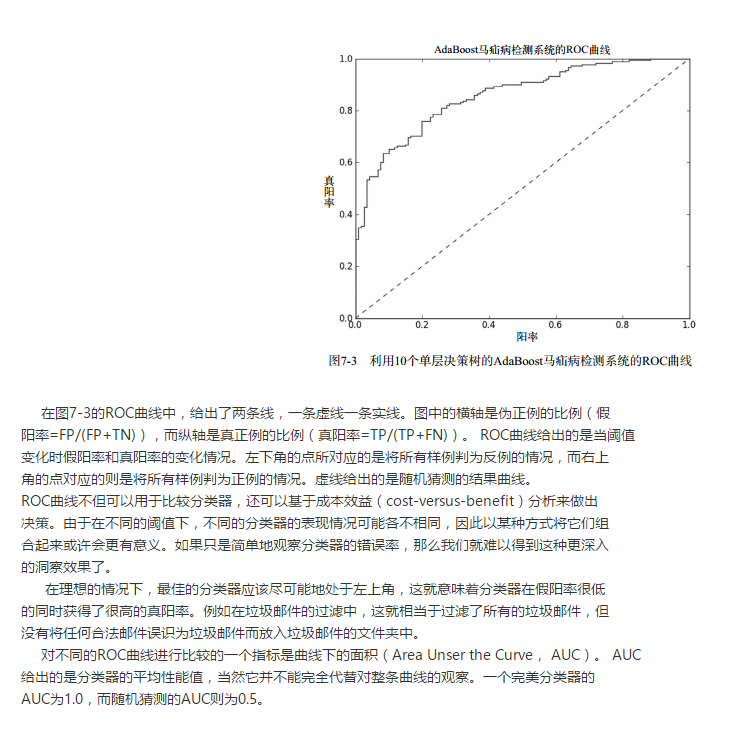
3 ROC曲线
另一个用于度量分类中的非均衡性的工具是ROC曲线(ROC curve), ROC代表接收者操作特 征(receiver operating characteristic),它最早在二战期间由电气工程师构建雷达系统时使用过。 图7-3给出了一条ROC曲线的例子。
八大策略:
https://blog.csdn.net/coder_oyang/article/details/48009493
非均衡分类问题:
https://www.baidu.com/link?url=LDQnrAsD_2oAhlZ8XIRTDUtb9v9TZar8geIoahAxhldXkNajE4adONpQ8_90NM4MxAQ64YF6apVYSjH88f4RK4ken5USHeYGuytNAMxCPHu&wd=&eqid=84c6b31300003bbf000000055dc0e091
https://www.cnblogs.com/tonglin0325/p/6198283.html
https://blog.csdn.net/crj0926/article/details/101310043

 浙公网安备 33010602011771号
浙公网安备 33010602011771号