Transformer —— attention is all you need
https://www.cnblogs.com/rucwxb/p/10277217.html
Transformer —— attention is all you need
Transformer模型是2018年5月提出的,可以替代传统RNN和CNN的一种新的架构,用来实现机器翻译,论文名称是attention is all you need。无论是RNN还是CNN,在处理NLP任务时都有缺陷。CNN是其先天的卷积操作不很适合序列化的文本,RNN是其没有并行化,很容易超出内存限制(比如50tokens长度的句子就会占据很大的内存)。
下面左图是transformer模型一个结构,分成左边Nx框框的encoder和右边Nx框框的decoder,相较于RNN+attention常见的encoder-decoder之间的attention(上边的一个橙色框),还多出encoder和decoder内部的self-attention(下边的两个橙色框)。每个attention都有multi-head特征。最后,通过position encoding加入没考虑过的位置信息。 下面从multi-head attention,self-attention, position encoding几个角度介绍。
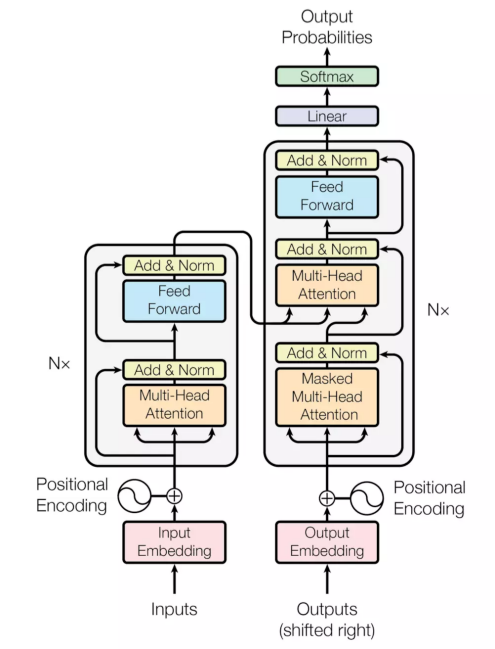
multi-head attention:
将一个词的vector切分成h个维度,求attention相似度时每个h维度计算。由于单词映射在高维空间作为向量形式,每一维空间都可以学到不同的特征,相邻空间所学结果更相似,相较于全体空间放到一起对应更加合理。比如对于vector-size=512的词向量,取h=8,每64个空间做一个attention,学到结果更细化。
self-attention:
每个词位的词都可以无视方向和距离,有机会直接和句子中的每个词encoding。比如上面右图这个句子,每个单词和同句其他单词之间都有一条边作为联系,边的颜色越深表明联系越强,而一般意义模糊的词语所连的边都比较深。比如:law,application,missing,opinion。。。
position encoding:
因为transformer既没有RNN的recurrence也没有CNN的convolution,但序列顺序信息很重要,比如你欠我100万明天要还和我欠你100万明天要还的含义截然不同。。。 transformer计算token的位置信息这里使用正弦波↓,类似模拟信号传播周期性变化。这样的循环函数可以一定程度上增加模型的泛化能力。
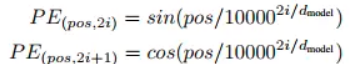
但BERT直接训练一个position embedding来保留位置信息,每个位置随机初始化一个向量,加入模型训练,最后就得到一个包含位置信息的embedding(简单粗暴。。),最后这个position embedding和word embedding的结合方式上,BERT选择直接拼接。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号