Transfer learning
大佬总结:
http://transferlearning.xyz/
博客部分摘录:
https://blog.csdn.net/qq_31511955/article/details/82220268
1.概念:
domain(域)和task(任务),
source(源)和target(目标),
然后给它们进行自由组合。
domain:包括两部分:1.feature space(特征空间);2.probability(概率)。
所以当我们说domain不同的时候,就得分两种情况。可能是feature space不同,也可能是feature space一样但probability不同。
task:包括两部分:1. label space(标记空间);2.objective predictive function(目标预测函数)。同理,当我们说task不同的时候,就得分两种情况。可能是label space不同,也可能是label space一样但function不同。 source和target就不用说了,前者是用于训练模型的域/任务,后者是要用前者的模型对自己的数据进行预测/分类/聚类等机器学习任务的域/任务。
- 迁移学习的分类
3.1. 从问题角度来看
(1)迁移什么? 哪一部分知识可以被迁移?
(2)怎么迁移? 那当然就是训练出适合的模型啦。
(3)什么时候需要用到迁移学习?
当source domain和target domain没什么关系或者太不相同的时候,迁移效果可能就不那么好了,甚至可能会比不迁移的时候表现要更差,这个就叫做negative transfer了。 可以看到,迁移学习的能力也是有限的,所以我们需要关注迁移学习的边界在哪里,比如用conditional Kolmogorov complexity去衡量tasks之间的相关性。
作者指出,现在很多工作都关注前两个问题,但实际上第三个问题是很重要的,因为你在那捣腾半天最后发现其实迁移了还不如不迁移,那不是白费心思嘛。所以作者认为这个问题应当被重视,比如说可以在迁移之前先看看source和domain之间的transferability(可迁移性)。
3.2. 从迁移场景来看
(1)Homogeneous TL(同构学习):source domain和target domain的feature space相同。
(2)Heterogeneous TL(异构学习):source domain和target domain的feature space不同。
3.3. 从迁移场景来看
(1)Inductive TL(归纳式迁移学习)
source和target的domain可能一样或不一样,task不一样;target domain的labeled数据可得,source domain不一定可得。
所以呢,根据source domain的labeled数据可以再细分为两类:
multitask learning(多任务学习):source domain的labeled数据可得。
self-taught learning(自学习):source domain的labeled数据不可得。
(2)Transductive TL(直推式迁移学习)
source和target的task一样,domain不一样;source domain的labeled数据可得,target domain的不可得。
注意我们提过,domain不一样意味着两种可能:feature space不一样,或者feature space一样而probability不一样。
而后一种情况和domain adaptation(域适配)息息相关。
这里也可以根据domain和task的个数分为两个情况:
Domain Adaptation(域适配):不同的domains+single task
Sample Selection Bias(样本选择偏差)/Covariance Shift(协方差转变):single domain+single task
(3)Unsupervised TL(无监督迁移学习)
source和target的domain和task都不一样;source domain和target domain的labeled数据都不可得。
综上,这几个方法差别主要是:
(1)source和domain之间,domain是否相同,task是否相同;
(2)source domain和target domain的labeled数据是否可以得到。
3.4. 从“迁移什么”来看
(1)Instance-based TL(样本迁移)
instance reweighting(样本重新调整权重)和importance sampling(重要性采样)是instance-based TL里主要用到的两项技术。
(2)Feature-representation-transfer(特征迁移) 找到一些好的有代表性的特征,通过特征变换把source domain和target domain的特征变换到同样的空间,使得这个空间中source domain和target domain的数据具有相同的分布,然后进行传统的机器学习就可以了。 特征变换这一块可以举个栗子,比如评论男生的时候,你会说”好帅!好有男人味!好有担当!“;评论女生的时候,你会说”好漂亮!好有女人味!好温柔!“可以看出共同的特征就是“好看”。把“好帅”映射到“好看”,把“好漂亮”映射到“好看”,“好看”便是它们的共同特征。 关于这一块,感觉这个文章讲的挺详细的,可以看看:迁移学习理论与应用
(3)Parameter-transfer(参数/模型迁移) 假设source tasks和target tasks之间共享一些参数,或者共享模型hyperparameters(超参数)的先验分布。这样把原来的模型迁移到新的domain时,也可以达到不错的精度。 下面这个项目感觉用到就是这个parameter-transfer:基于深度学习和迁移学习的识花实践。
(4)Relational-knowledge-transfer(关系迁移) 把相似的关系进行迁移,比如生物病毒传播到计算机病毒传播的迁移,比如师生关系到上司下属关系的迁移。
4.1. Inductive TL
(1)Instances TL
主要方法:TrAdaBoost(AdaBoost的拓展)
假设:source domain和target domain数据的feature和labels是一样的,但是分布不一样;部分source domain的数据会对target domain的学习有帮助,但有部分可能会不利于target domain的学习。 过程:大致就是不断地给好的source data赋予更高的权重,给不好的赋予更多的权重。
(2)Features TL
需要根据source domain的labeled data是否可得分为两类(回顾:Inductive TL是target domain的labeled data可得,但是source domain的未必可得): Supervised Feature Construction(监督的特征构建) Unsupervised Feature Construction(非监督的特征构建) 大致过程:通过减少model error,找出低维的有代表性的特征
(3)Parameters TL 主要方法:MT-IVM(基于Gaussian Processes)
大致过程(注意这里讲述的不是上面提到的那个主要方法的过程,而是另一个方法的过程):假设source和target的参数都可以分为两部分,一部分是source/target特有的参数,一部分是它们共同有的参数。把这两个参数丢到改进了的SVM问题中,把参数训练出来就好了。
(4)Relational TL 注意和上面三种方法不同的是,这个方法是在relational domains里进行的,这个domain里的数据不是iid(独立同分布)的,所以它不需要假设每个domain里的数据都必须iid。 主要方法:statistical relational learning(SRL,统计关系学习)
4.2. Transductive TL
回顾一下,Transductive TL是source domain的label可得,target domain的label不可得。但是要注意!为了得到target data的边际分布,在training的时候是需要一些unlabeled的target data的。
(1)Instances TL 主要方法:Importance sampling。 大致过程:我们的目标是最小化target domain里的expected risk(期望风险),但是target domain里没有labeled数据可用,所以我们必须替换成source domain里的数据,通过一些方法可以把它替换成source domain里的数据再乘以一个权重,只要把这个权重算出来就好。
(2)Feature Representations TL 主要方法:Structural Correspondence Learning(SCL) 大致过程:定义一些pivot features(就是共同特征),然后把每一个pivot feature都当成是一个新的label vector,通过公式把权重学习出来,然后对权重进行SVD分解,最后在argumented feature vector上使用传统的判别式算法即可。这里argumented feature vector包括这些新的features和所有原来的feature。(我还没有详细看这一块儿,所以先直译了) 难点:如何寻找好的pivot feature、domain之间的依赖性。
4.3. Unsupervised TL
(1)Feature Representations TL 主要方法:涉及两个 Self-taught clustering(STC),主要用于transfer clustering(迁移聚类)。目标就是希望通过source domain里大量的unlabeled data对少量的target domain里的unlabeled data进行聚类。 TDA方法,这个主要用于解决transfer dimensionality reduction(迁移降维)问题
- 存在不足
(1)当然就是negative transfer的问题啦,比如怎么定义transferability,怎么衡量domain之间或task之间的相关性。
(2)目前的TL算法主要都是想要提高feature space相同probability不同时的表现的,记得我前面说过的domain不同或者task不同都有两种情况,一种是space不同,一种是space相同probability不同吗?这里说的就是目前TL算法主要致力于提高的都是概率不同的。但是很多时候我们其实也想要对feature space不同的domain和task进行迁移。这个就是3.2提到的heterogeneous TL(异构学习)问题。
(3)现在的TL主要都是应用到小且波动不大的数据集中(例如传感器数据、文本分类、图片分类等),以后要考虑如何用到更广泛的数据场景中。
其他:
https://www.cnblogs.com/yejintianming00/p/9338679.html
https://www.jiqizhixin.com/graph/technologies/a5deb948-06e3-4875-acdb-35c268734006
https://www.baidu.com/link?url=6SXxCAyNSRDwN0BxGRKSr6XamYlrgBSX4dg1NlWfub7NwluB_ZPsi1V51JaIFBwoJjiPL_KAuO0Z6rucLepJe_&wd=&eqid=a0b9750400191e3d000000035d6d05ba
补:基于映射的深度迁移学习
基于映射的深度迁移学习是指将源域和目标域中的实例映射到新的数据空间。在这个新的数据空间中,来自两个域的实例都相似且适用于联合深度神经网络。
它基于假设:「尽管两个原始域之间存在差异,但它们在精心设计的新数据空间中可能更为相似。」基于映射的深度迁移学习的示意图如图 3 所示:
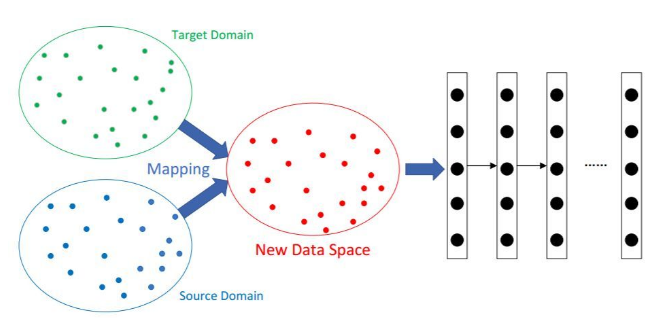
图 3:基于映射的深度迁移学习的示意图。来自源域和目标域的实例同时以更相似的方式映射到新数据空间。将新数据空间中的所有实例视为神经网络的训练集。 由 [18] 引入的迁移成分分析(TCA)和基于 TCA 的方法 [29] 已被广泛用于传统迁移学习的许多应用中。一个自然的想法是将 TCA 方法扩展到深度神经网络。 [23] 通过引入适应层和额外的域混淆损失来扩展 MMD 用以比较深度神经网络中的分布,以学习具有语义意义和域不变性的表示。该工作中使用的 MMD 距离定义为:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号