Embeding如何理解?
参考:
http://www.sohu.com/a/206922947_390227
https://zhuanlan.zhihu.com/p/27830489
https://www.jianshu.com/p/0bb00eed9c63
https://www.jianshu.com/p/2a76b7d3126b
https://blog.csdn.net/k284213498/article/details/83474972
嵌入(Embedding)
例如,想用将具有三个等级的输入变量表示为二维数据。使用嵌入层,底层自微分引擎(the underlaying automatic differentiation engines,例如Tensorflow或PyTorch)将具有三个等级的输入数据减少为二维数据。
嵌入式数据
输入数据需要用索引表示。这一点可以通过标签编码轻松实现。这是你的嵌入层的输入。
这里有一个简单的例子,在keras中使用嵌入层,点击链接,查看详情:https://github.com/krishnakalyan3/FastAI_Practice/blob/master/notebooks/RecSys.ipynb
最初,权重是随机初始化的,它们使用随机梯度下降得到优化,从而在二维空间中获得良好的数据表示。可以说,当我们有100个等级时,并且想要在50个维度中获得这个数据的表示时,这是一个非常有用的主意。
示例:
原始数据:
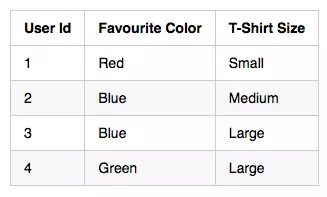
标签数据:

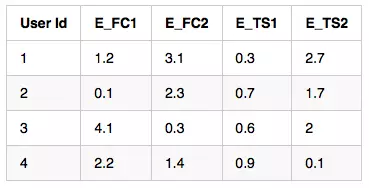
独热编码:

嵌入数据:
2.机器学习中的embedding原理及tensorflow 相关API的理解
embedding 算法主要用于处理稀疏特征,应用于NLP、推荐、广告等领域。所以word2vec 只是embbeding 思想的一个应用,而不是全部。
原文地址:https://gshtime.github.io/2018/06/01/tensorflow-embedding-lookup-sparse/
代码地址:git@github.com:gshtime/tensorflow-api.git
embedding原理
常见的特征降维方法主要有PCA、SVD等。
而embedding的主要目的也是对(稀疏)特征进行降维,它降维的方式可以类比为一个全连接层(没有激活函数),通过 embedding 层的权重矩阵计算来降低维度。
假设:
- feature_num : 原始特征数
- embedding_size: embedding之后的特征数
- [feature_num, embedding_size] 权重矩阵shape
- [m, feature_num] 输入矩阵shape,m为样本数
- [m, embedding_size] 输出矩阵shape,m为样本数
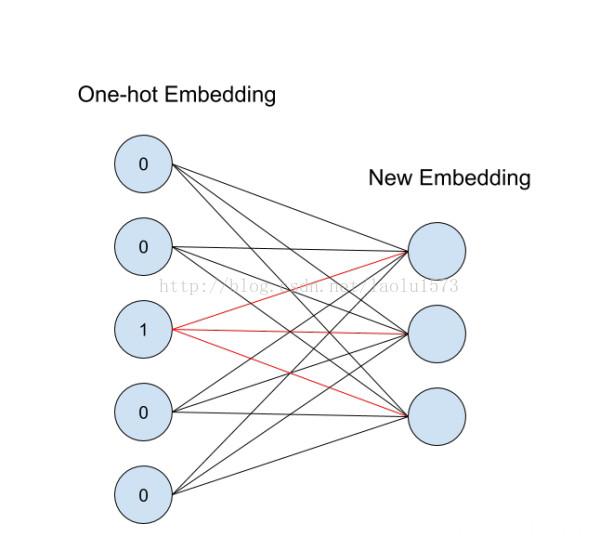
从id(索引)找到对应的 One-hot encoding ,然后红色的weight就直接对应了输出节点的值(注意这里没有 activation function),也就是对应的embedding向量。
3.Word Embedding的发展和原理简介
https://www.jianshu.com/p/2a76b7d3126b
可以将Word Embedding理解为一种映射,其过程是:将文本空间中的某个word,通过一定的方法,映射或者说嵌入(embedding)到另一个数值向量空间(之所以称之为embedding,是因为这种表示方法往往伴随着一种降维的意思。
1.2 Word Embedding的输入
Word Embedding的输入是原始文本中的一组不重叠的词汇,假设有句子:apple on a apple tree。那么为了便于处理,我们可以将这些词汇放置到一个dictionary里,例如:["apple", "on", "a", "tree"],这个dictionary就可以看作是Word Embedding的一个输入。
1.3 Word Embedding的输出
Word Embedding的输出就是每个word的向量表示。对于上文中的原始输入,假设使用最简单的one hot编码方式,那么每个word都对应了一种数值表示。例如,apple对应的vector就是[1, 0, 0, 0],a对应的vector就是[0, 0, 1, 0],各种机器学习应用可以基于这种word的数值表示来构建各自的模型。当然,这是一种最简单的映射方法,但却足以阐述Word Embedding的意义。下文将介绍常见的Word Embedding的方法和优缺点。
2 Word Embedding的类型
Word Embedding也是有流派的,主流有以下两种:
基于频率的Word Embedding(Frequency based embedding)
基于预测的Word Embedding(Prediction based embedding)
下面分别介绍之。
2.1 基于频率的Word Embedding
基于频率的Word Embedding又可细分为如下几种:
Count Vector
TF-IDF Vector
Co-Occurence Vector
其本质都是基于one-hot表示法的,以频率为主旨的加权方法改进。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号