
TF基础3
批标准化
批标准化(batch normalization,BN)是为了克服神经网络层数加深导致难以训练而诞生的。深度神经网络随着深度加深,收敛会越来越慢,会导致梯度弥散问题(vanishing gradient problem)。
统计机器学习有一个ICS理论,这是一个经典假设:源域和目标域的数据分布是一致的。
解决思路是根据训练样本和目标样本的比例对训练样本做一个矫正。
方法
批标准化一般用在非线性映射(激活函数)之前,对x=Wu+b做规范化,使结果(输出信号各个维度)的均值为0,方差为1,让每一层的输入有一个稳定的分布会有利于网络的训练。
优点:加快收敛速度,容易跳出局部最小值,一定程度上缓解过拟合。
示例
对每层的Wx_plus_b进行批标准化,这个步骤放在激活函数之前:
#计算的均值和方差,其中axes=[0]表示想要标准化的维度
fc_mean,fc_var=tf.nn.moments(Wx_plus_b,axes=[0],)
scale=tf.Variable(tf.ones([out_size]))
shift=tf.Variable(tf.zeros([out_size]))
epsilon=0.001
Wx_plus_b=tf.nn.batch_normalization(Wx_plus_b,fc_mean,fc_var,shift,scale,epsilon)
#也就是在做:
#Wx_plus_b=(Wx_plus_b-fc_mean)/tf.sqrt(fc_var+0.001)
#Wx_plus_b=Wx_plus_b*scale+shift
神经元函数及优化方法
激活函数
激活函数(activation function)运行时激活神经网络中某一部分神经元,将激活信息向后传入下一层的神经网络。
激活函数不会改变输入数据的维度,即输入和输出维度一样。
TF有以下激活函数:
平滑非线性的激活函数:sigmoid、tanh、elu,softplus和softsign,即tf.nn.softplus()等等
连续但是不是处处可微的函数:relu、relu6、crelu和relu_x,即tf.nn.relu()等等
随机正则化函数dropout:tf.nn.dropout(),防止过拟合,用来舍弃某些神经元
relu是目前最受欢迎的激活函数。
a=tf.constant([-1.0,2.0])
with tf.Session() as sess:
b=tf.nn.relu(a)
print(sess.run(b))
[ 0. 2.]
dropout函数:一个神经元将以概率keep_pro决定是否被抑制;如果被抑制,该神经元的输出就是0,如果不被抑制,那么该神经元的输出值将被放大到原来的1/keep_pro倍。
a=tf.constant([[-1.0,2.0,3.0,4.0]])
with tf.Session() as sess:
b=tf.nn.dropout(a,0.5,noise_shape=[1,4])
print(sess.run(b))
b = tf.nn.dropout(a, 0.5, noise_shape=[1, 1])
print(sess.run(b))
[[-0. 4. 6. 8.]]
[[-2. 4. 6. 8.]]
小结:
当输入数据特征相差明显时,用tanh的效果会很好。
当输入数据特征相差不明显时,用sigmoid的效果会很好。
现在大部分卷积神经网络采用relu作为激活函数,其他的有用tanh,尤其在NLP上。
卷积函数
卷积函数是构建神经网络的重要支架。
以下分别说明:
1.计算N维卷积的和的函数tf.nn.convolution()
tf.nn.convolution(input,filter,padding,strides=None,dilation_rate=None,name=None,data_format=None)
2.对一个四维的输入数据input和四维的卷积核filter进行操作,然后对输入数据进行一个二维的卷积操作,最后得到卷积之后的结果。
tf.nn.conv2d(input,filter, strides, padding, use_cudnn_on_gpu=None, name=None)
input:为一个Tensor,数据类型必须是float32或者float64;
filter:为一个tensor,数据类型必须是与input输入的数据类型相同;
strides:一个长度是4的一维整数类型数组,每一维度对应的是input中每一维的对应移动步数;如strides[1]对应input[1]的移动步数;
padding:一个字符串,取值为SAME或者VALID;‘SAME'适用于全尺寸操作,即输入数据维度和输出数据维度相同;'VALID'适用于部分窗口;
use_cudnn_on_gpu:一个可选布尔值,默认情况下是True;
name:为这个操作取一个名字;
import tensorflow as tf
import os
import numpy as np
input_data= tf.Variable(np.random.rand(10,9,9,3),dtype=np.float32)
filter_data=tf.Variable(np.random.rand(2,2,3,4),dtype=np.float32)
y = tf.nn.conv2d(input_data,filter_data,strides=[1,3,3,1],padding='SAME')
print('输入的结果为:', y)
输入的结果为: Tensor("Conv2D:0", shape=(10, 3, 3, 4), dtype=float32)
3.函数tf.nn.depthwise_conv2d(input, filter, strides, padding, name=None,data_format=None)
input的数据维度[batch,in_height,in_weight,in_channels]
filter的维度[filter_height, filter_width,in_channel, channel_multiplierl]
在通道in_channels上面的卷积深度是3,
将不同的卷积核独立地应用在in_channels的每条通道上,
然后将所有的结果进行汇总,输出通道的总数,in_channel*channel_multiplier
4.函数tf.nn.separable_conv2d(input, depthwise_filter, pointwise_filter, strides, padding, name=None,data_format=None)
利用几个分离的卷积核去做卷积。
depthwise_filter:为一个张量,数据维度是四维[filter_height, filter_width, in_channels, channel_multiplier]
pointwise_filter:一个四维的张量,数据维度是四维[1,1,channel_multipliter*in_channels,out_channels]。
pointwise_filter是在depthwise_filter卷积之后的混合卷积;
strides:一个长度是4的一维整数类型数组,每一个维度对应的是input中每一维的对应移动步数
5)函数tf.nn.atrous_conv2d(value, filters, rate, padding, name=None)计算Atrous卷积,称为扩张卷积
(6)函数tf.nn.conv2d_transpose(value, filter, output_shape,strides, padding='SAME',data_format='NHWC',name=None)为conv2d的转置。
(7)函数tf.nn.conv1d(value, filters, stride, padding , use_cudnn_on_gpu=None,data_format=None,name=None)与二维卷积类似
该函数用来计算给定三维的输入和过滤器的情况下的一维卷积。
输入为三维,[batch, in_width, in_channels]
卷积核的维度为三维,少了一维filter_heigth,如[filter_width,in_channels, out_channels].
stride是一个正整数,代表卷积核向右移动每一步的长度。
(8)函数tf.nn.conv3d(input, filter, strides, padding, name=None)与二维卷积类似。
用来计算给定五维的输入和过滤器的情况下的三维卷积
与二维卷积相对比:
input的shape中多了一维in_depth,形状为[batch, in_depth, in_height, in_width, in_channels]
filter的shape中多了一维filter_depth,[filter_depth, filter_height, in_channel,channel_multiplierl]构成卷积核大小
strides的shape中多了一维strides_depth, [strides_batch, strides_depth, strides_height, strides_width, strides_channel]
(9)函数tf.nn.conv3d_tranpose(value, filter, output_shape, strides, padding='SAME',name=None)与二维反卷积类似。
池化函数
在神经网络中,池化函数一般跟在卷积函数的下一层。池化分为最大池化和平均池化两种。每个池化操作的窗口大小由ksize指定,并根据步长stride决定移动步长。
(1).tf.nn.avg_pool(value,ksize,strides,padding,data_format='NHWC',name=None) 计算池化区域中元素的平均值
def avg_pool(value, ksize, strides, padding, data_format='NHWC', name=None)
value:是一个四维的张量,数据维度是[batch, height, width, channels]
ksize:是一个长度不小于4的整型数组,每一位上的值对应于输入数据张量中每一维的窗口对应值
strides:一个长度不小于4的整型数组,该参数指定滑动窗口在输入数据张量每一维上的步长
padding:一个字符串, 取值为SAME或者VALID
data_format:'NHWC'代表输入张量维度的顺序,N为个数,H为高度,W为宽度,C为通道数
name:为这个操作取一个名字;
(2)tf.nn.max_pool(value,ksize, strides, padding, data_format='NHWC', name=None)
计算池化区域中元素的最大值
(3).tf.nn.max_pool_with_argmax(input, ksize, strides, padding ,Targmax=None, name=None)
计算池化区域中元素的最大值和该最大值所在的位置
(4).tf.nn.avg_pool3d()和tf.nn.max_pool3d()
分别为在三维下的平均池化层和最大池化层
(5).tf.nn.fractional_avg_pool()和tf.nn.fractional_max_pool()
分别为在三维下的平均池化和最大池化
(6)tf.nn.pool()执行一个N维的池化操作
(https://www.sogou.com/link?url=DOb0bgH2eKh1ibpaMGjuy9i2Gol-5JTB43wDyFcvlbGHDDTl0xsUWrBn4VA8J3Sxh3Iic7Mnfz-YMEr0L5a9ww..)
分类函数
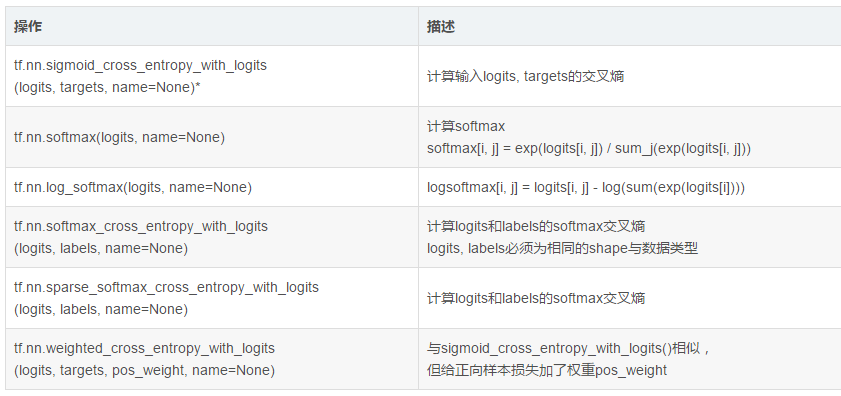
优化方法
重点有8个,如下:
tf.train.GradientDescentOptimizer()
tf.train.AdadeltaOptimizer()
tf.train.AdagradOptimizer()
tf.train.AdagradDAOptimizer()
tf.train.MomentumOptimizer()
tf.train.AdamOptimizer()
tf.train.FtrlOptimizer()
tf.train.RMSPropOptimizer()
(具体:https://blog.csdn.net/imfengyitong/article/details/70808544)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号