

Fine-tuning Convolutional Neural Networks for Biomedical Image Analysis: Actively and Incrementally如何使用尽可能少的标注数据来训练一个效果有潜力的分类器
链接:https://www.zhihu.com/question/57523080/answer/236301363
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
今天我给大家介绍一下 CVPR 2017 关于医学图像处理的一篇比较有意思的文章,用的是 active learning 和 incremental learning 的方法。
今天分享的主要内容是,首先介绍一下这篇文章的 motivation,就是他为什么要做这个工作;然后介绍一下他是怎么去做的,以及在两种数据集上的应用;最后做一下简单的总结,说一下它的特点以及还有哪些需要改进的地方。

其实在机器学习,特别是深度学习方面,有一个很重要的前提是需要有足够量的标注数据。但是这种标注数据一般是需要人工去标注,有时候标注的成本还是挺高的,特别是在医学图像处理上面。因为医学图像处理需要一些 domain knowledge,就是说医生对这些病比较熟悉他才能标,我们一般人是很难标的。不像在自然图像上面,比如ImageNet上面的图片,就是一些人脸、场景还有实物,我们每个人都可以去标,这种成本低一点。医学图像的成本就会比较高,比如我右边举的例子,医学图像常见的两种方式就是X光和CT。X光其实一个人一般拍出来一张,标注成本大概在20到30块钱人民币一张;CT是横断面,拍完一个人大概有几百张图片,标注完的成本就会高一点,标注的时间也会比较长。
举个例子,比如标1000张,这个数据对 deep learning 来说数据量不算太大,X光需要2到3万人民币、3到4天才能标完;CT成本就会更长,而且时间成本也是一个很重要的问题。那要怎么解决深度学习在医学方面、特别是医学图像方面的这个难题呢?就要用尽量少的标注数据去训练一个 promising 的分类器,就是说一个比较好的分类器。
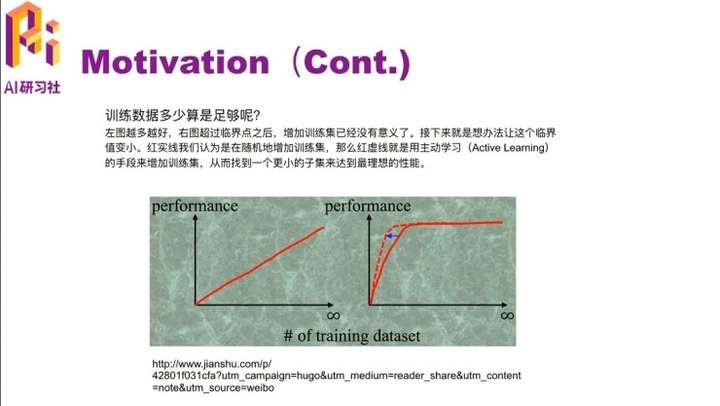
那我们就要考虑要多少训练数据才够训练一个 promising 的分类器呢?这里有个例子,比如左边这个图,这个模型的 performance 随着数据的增加是一个线性增长的过程,就是说数据越多,它的 performance 就越高。但在实际中,这种情况很少出现,一般情况下都是数据量达到一定程度,它的 performance就会达到一个瓶颈,就不会随着训练数据的增加而增加了。但是我们有时候想的是把这个临界点提前一点,让它发生在更小数据量的时候。比如右边这个图的红色虚线部分,用更小的数据达到了相同的 performance。这篇论文里就是介绍主动学习 active learning 的手段,找到一个小数据集达到大数据集一样的效果。

怎么样通过 active learning 的方式降低刚才右图里的临界点呢?就是要主动学习那些比较难的、容易分错的、信息量大的样本,然后把这样的样本标记起来。因为这些是比较难分的,容易分的可能几个样本就训练出来了,难分的就需要大量的数据,模型才能学出来。所以模型要先去学这些难的。
怎么去定义这个“难”呢?就是“难的”、“容易分错”、“信息量大”,其实说的是一个意思。这个“信息量大”用两个指标去衡量,entropy大和diversity高。entropy就是信息学中的“熵”,diversity就是多样性。这个数据里的多样性就代表了模型学出来的东西具有比较高的泛化能力。举个例子,对于二分类问题,如果预测值是在0.5附近,就说明entropy比较高,因为模型比较难分出来它是哪一类的,所以给了它一个0.5的概率。
用 active learning 去找那些比较难的样本去学习有这5个步骤
- 首先,把所有的未标注图片数据在大量自然图像中训练的网络,大家知道现在有很多常用的网络,从最初的LeNet、AlexNet、GoogLeNet、VGG、ResNet这样的网络中去测试一遍,得到预测值。 然后挑出来那些最难的、信息量大的样本去标注
- 用这些刚刚标注了的样本去训练深度学习网络,得到一个网络N
- 把剩下没有标签的图像用N过一遍,得到预测值,挑一遍那些最难的,用人工去给它标注
- 把刚刚标注了的样本和原来已经标好的样本一起,也就是整个标注集拿来继续训练这个网络
- 重复3到4这个步骤,直到当前的分类器可以对选出来的比较难的图像很好的分类了。
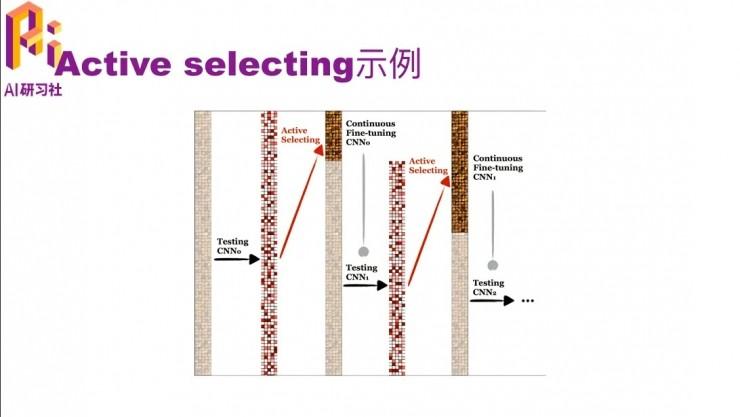
刚才的文字讲解可能不是很直观,我们用一个图来看一下。这个图从左到右看,一开始灰蒙蒙的意思是都还没有标注,然后用一个pre-trained model去预测一遍都是哪个类。这样每个数据上都有一个概率,可以根据这个概率去选择它是不是难分的那个数据,就得到了中间这个图,上面那一段是比较难的,然后我们把它标注出来。然后用一个 continuous fine-tune 的 CNN,就是在原来的模型上再做一次 fine-tune,因为有了一些标注数据了嘛,就可以继续 fine-tune了。 fine-tune后的模型对未标注的数据又有了一个预测的值,再根据这些预测值与找哪些是难标的,把它们标上。然后把这些标注的数据和之前就标注好的数据一起,再做一次 continuous fine-tune,就得到 CNN2了。然后依次类推,直到把所有的数据都标完了,或者是在没有标完的时候模型的效果就已经很好了,因为把其中难的数据都已经标完了。

刚才提到了两个指标来判定一个数据是不是难分的数据。entropy比较直观,预测结果在0.5左右就认为它是比较难分的;但diversity这个值不是很好刻画,就通过 data augmentation数据增强的方式来设计指标,就是说从一个图像设计出一系列它的变形。这些变形就可以是靠翻转、旋转、平移操作等等,一个变成了好几个甚至十几个,增加了它的多样性。然后对这些所有的变形去预测它们的分类结果,如果结果不统一的话,就说明这副图像的diversity比较强,那么这张图像就是比较难分的,是hard sample;反之就是比较好分的,那么就不去做它的增强了。然后对所有增强以后的数据的预测值应当是一致的,因为它们代表的是同一个东西,但是也有一些例外,如果是像我刚才说的那样的简单的数据增强。
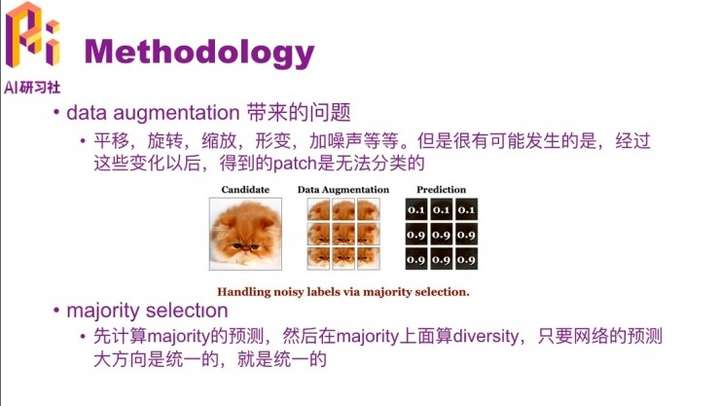
这就会产生一个问题,原始的图像,比如左边这只小猫,经过平移、旋转、缩放等一些操作以后得到9张图,每张图都是它的变形。然后我们用CNN对这9张图求是一只猫的概率,可以看到上面三个图的概率比较低,就是判断不出来是一只猫,我们直观的去看,像老鼠、狗、兔子都有可能。本来这是一个简单的例子,很容易识别出来这是一只猫,但是增强了以后反而让模型不确定了。这种情况是需要避免的。
所以这种时候做一个 majority selection,就是一个少数服从多数的方式,因为多数都识别出来它是一只猫了。这就是看它的倾向性,用里面的6个预测值为0.9的数据,上面三个预测值为0.1的就不作为增强后的结果了。这样网络预测的大方向就是统一的了。

这篇文章的创新点除了active learning之外,它在学习的时候也不是从batch开始,而是sequential learning。它在开始的时候效果就不会特别好,因为完全没有标注数据,它是从一个ImageNet数据库训练出的模型直接拿到medical的应用里来预测,效果应该不会太好。然后随着标注数据的增加,active learning的效果就会慢慢体现出来。这里是在每一次fine-tune的时候,都是在当前的模型基础上的进一步fine-tune,而不是都从原始的pre-train的model做fine-tune,这样就对上一次的模型参数有一点记忆性,是连续的学习。这种思路就跟学术上常见的sequntial learning和online learning是类似的。但是有一个缺点就是,fine-tune的参数不太好控制,有一些超参数,比如learning rate还有一些其它的,其实是需要随着模型的变化而变化的,而且比较容易一开始就掉入local minimal,因为一开始的时候标注数据不是很多,模型有可能学到一个不好的结果。那么这就是一个open的问题,可以从好几个方面去解决,不过解决方法这篇文章中并没有提。

这个方法在机器学习方面是比较通用的,就是找那些难分的数据去做sequntial的fine-tune。这篇论文里主要是用在了医学图像上面,用两个例子实验了结果,一个是结肠镜的视频帧分类,看看有没有病变、瘤之类的。结论是只用了5%的样本就达到了最好的效果,因为其实因为是连续的视频帧,通常都是差不多的,前后的帧都是类似的,不需要每一帧都去标注。另一个例子也是类似的,肺栓塞检测,检测+分类的问题,只用1000个样本就可以做到用2200个随机样本一样的效果。

这个作者我也了解一些,他是在 ASU 的PhD学生,然后现在在梅奥,美国一个非常著名的私立医院梅奥医院做实习,就跟需要做标注的医生打交道比较多。这相当于就是一个从现实需求得出来的一个研究课题。
总结下来,这篇文章有几个比较好的亮点。
- 从标注数据来说,从一个完全未标注的数据集开始,刚开始的时候不需要标注数据,最终以比较少量的数据达到很好的效果;
- 然后,从sequntial fine-tune的方式,而不是重新训练;
- 选择样本的时候,是通过候选样本的一致性,选择有哪些样本是值得标注的;
- 自动处理噪音,就是刚才举的猫的那个例子,数据增强的时候带来的噪音,通过少数服从多数的方式把那些噪音去掉了;
- 在每个候选集只选少量的patches计算熵和KL距离,KL距离就是描述diversity的指标,这样减少了计算量。传统的深度学习的时候会需要在训练之前就做数据增强,每个样本都是同等的;这篇文章里面有一些数据增强不仅没有起到好的作用,反而带来了噪音,就需要做一些处理;而且还有一些数据根本不需要增强,这样就减少了噪音,而且节省了计算。

Q&A
Q:为什么开始的时候 active learning 没有比random selection好?
A:其实不一定,有时候是没有办法保证谁好。active learning在一开始的时候是没有标注数据的,相当于这时候它不知道哪些数据是hard的,在这个医学数据集上并没有受到过训练。这时候跟 random selection 就一样了,正在迁移原来 ImageNet 图像的学习效果。random selection 则有可能直接选出来 hard的那些结果,所以有可能比刚开始的active selecting要好一点,但这不是每次都是 random selection 好。就是不能保证到底是哪一个更好。

