

Python-OpenCV快速教程
一、Mat生成图片
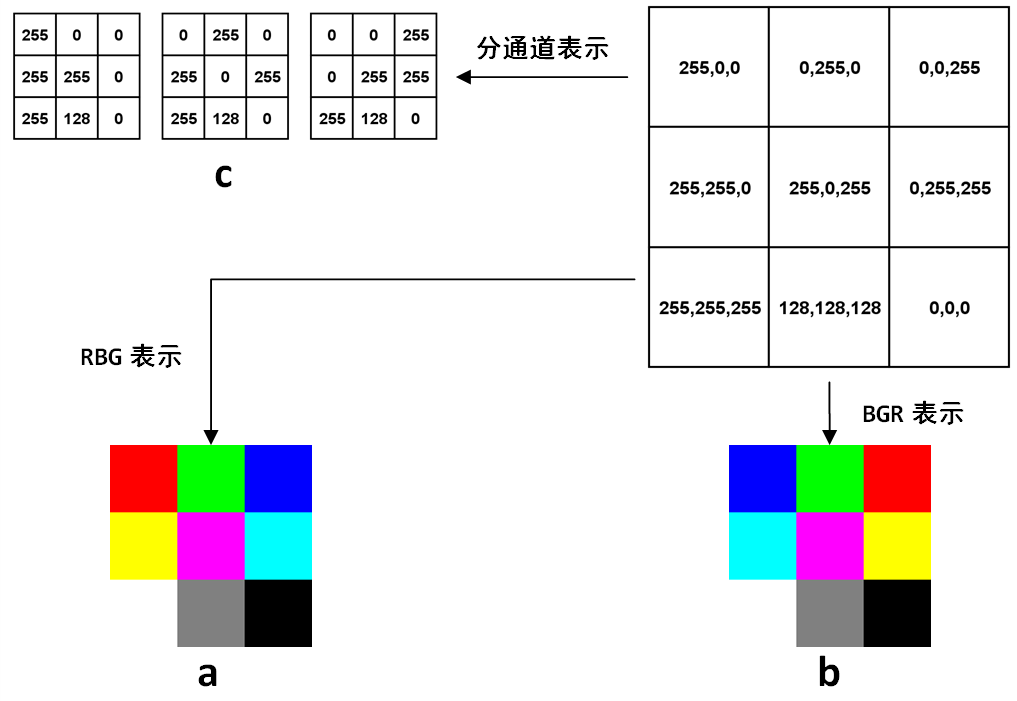
面的简单代码就可以生成两种表示方式下,图6-1中矩阵的对应的图像,生成图像后,放大看就能体会到区别:
import numpy as np
import cv2
import matplotlib.pyplot as plt
# 图6-1中的矩阵
img = np.array([
[[255, 0, 0], [0, 255, 0], [0, 0, 255]],
[[255, 255, 0], [255, 0, 255], [0, 255, 255]],
[[255, 255, 255], [128, 128, 128], [0, 0, 0]],
], dtype=np.uint8)
# 用matplotlib存储
plt.imsave('img_pyplot.jpg', img)
# 用OpenCV存储
cv2.imwrite('img_cv2.jpg', img)
不管是RGB还是BGR,都是高度×宽度×通道数,H×W×C的表达方式,而在深度学习中,因为要对不同通道应用卷积,所以用的是另一种方式:C×H×W,就是把每个通道都单独表达成一个二维矩阵,如图所示。
二、基本图像处理
1、存取图像
读图像用cv2.imread(),可以按照不同模式读取,一般最常用到的是读取单通道灰度图,或者直接默认读取多通道。存图像用cv2.imwrite(),注意存的时候是没有单通道这一说的,根据保存文件名的后缀和当前的array维度,OpenCV自动判断存的通道,另外压缩格式还可以指定存储质量,来看代码例子:
import cv2
# 读取一张400x600分辨率的图像
color_img = cv2.imread('test_400x600.jpg')
print(color_img.shape)
# 直接读取单通道
gray_img = cv2.imread('test_400x600.jpg', cv2.IMREAD_GRAYSCALE)
print(gray_img.shape)
# 把单通道图片保存后,再读取,仍然是3通道,相当于把单通道值复制到3个通道保存
cv2.imwrite('test_grayscale.jpg', gray_img)
reload_grayscale = cv2.imread('test_grayscale.jpg')
print(reload_grayscale.shape)
# cv2.IMWRITE_JPEG_QUALITY指定jpg质量,范围0到100,默认95,越高画质越好,文件越大
cv2.imwrite('test_imwrite.jpg', color_img, (cv2.IMWRITE_JPEG_QUALITY, 80))
# cv2.IMWRITE_PNG_COMPRESSION指定png质量,范围0到9,默认3,越高文件越小,画质越差
cv2.imwrite('test_imwrite.png', color_img, (cv2.IMWRITE_PNG_COMPRESSION, 5))
2、缩放,裁剪和补边
缩放通过cv2.resize()实现,裁剪则是利用array自身的下标截取实现,此外OpenCV还可以给图像补边,这样能对一幅图像的形状和感兴趣区域实现各种操作。下面的例子中读取一幅400×600分辨率的图片,并执行一些基础的操作:
import cv2 # 读取一张四川大录古藏寨的照片 img = cv2.imread('tiger_tibet_village.jpg') # 缩放成200x200的方形图像 img_200x200 = cv2.resize(img, (200, 200)) # 不直接指定缩放后大小,通过fx和fy指定缩放比例,0.5则长宽都为原来一半 # 等效于img_200x300 = cv2.resize(img, (300, 200)),注意指定大小的格式是(宽度,高度) # 插值方法默认是cv2.INTER_LINEAR,这里指定为最近邻插值 img_200x300 = cv2.resize(img, (0, 0), fx=0.5, fy=0.5, interpolation=cv2.INTER_NEAREST) # 在上张图片的基础上,上下各贴50像素的黑边,生成300x300的图像 img_300x300 = cv2.copyMakeBorder(img, 50, 50, 0, 0, cv2.BORDER_CONSTANT, value=(0, 0, 0)) # 对照片中树的部分进行剪裁 patch_tree = img[20:150, -180:-50] cv2.imwrite('cropped_tree.jpg', patch_tree) cv2.imwrite('resized_200x200.jpg', img_200x200) cv2.imwrite('resized_200x300.jpg', img_200x300) cv2.imwrite('bordered_300x300.jpg', img_300x300)
注意:
//裁剪的时候,x,y是反的,正确的是rect=image[y0:yo+h0,x0:x0+w0]
这些处理的效果见图6-2。
3、色调,明暗,直方图和Gamma曲线
除了区域,图像本身的属性操作也非常多,比如可以通过HSV空间对色调和明暗进行调节。HSV空间是由美国的图形学专家A. R. Smith提出的一种颜色空间,HSV分别是色调(Hue),饱和度(Saturation)和明度(Value)。在HSV空间中进行调节就避免了直接在RGB空间中调节是还需要考虑三个通道的相关性。OpenCV中H的取值是[0, 180),其他两个通道的取值都是[0, 256),下面例子接着上面例子代码,通过HSV空间对图像进行调整:
# 通过cv2.cvtColor把图像从BGR转换到HSV img_hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV) # H空间中,绿色比黄色的值高一点,所以给每个像素+15,黄色的树叶就会变绿 turn_green_hsv = img_hsv.copy() turn_green_hsv[:, :, 0] = (turn_green_hsv[:, :, 0]+15) % 180 turn_green_img = cv2.cvtColor(turn_green_hsv, cv2.COLOR_HSV2BGR) cv2.imwrite('turn_green.jpg', turn_green_img) # 减小饱和度会让图像损失鲜艳,变得更灰 colorless_hsv = img_hsv.copy() colorless_hsv[:, :, 1] = 0.5 * colorless_hsv[:, :, 1] colorless_img = cv2.cvtColor(colorless_hsv, cv2.COLOR_HSV2BGR) cv2.imwrite('colorless.jpg', colorless_img) # 减小明度为原来一半 darker_hsv = img_hsv.copy() darker_hsv[:, :, 2] = 0.5 * darker_hsv[:, :, 2] darker_img = cv2.cvtColor(darker_hsv, cv2.COLOR_HSV2BGR) cv2.imwrite('darker.jpg', darker_img)
无论是HSV还是RGB,我们都较难一眼就对像素中值的分布有细致的了解,这时候就需要直方图。如果直方图中的成分过于靠近0或者255,可能就出现了暗部细节不足或者亮部细节丢失的情况。比如图6-2中,背景里的暗部细节是非常弱的。这个时候,一个常用方法是考虑用Gamma变换来提升暗部细节。Gamma变换是矫正相机直接成像和人眼感受图像差别的一种常用手段,简单来说就是通过非线性变换让图像从对曝光强度的线性响应变得更接近人眼感受到的响应。具体的定义和实现,还是接着上面代码中读取的图片,执行计算直方图和Gamma变换的代码如下:
import numpy as np # 分通道计算每个通道的直方图 hist_b = cv2.calcHist([img], [0], None, [256], [0, 256]) hist_g = cv2.calcHist([img], [1], None, [256], [0, 256]) hist_r = cv2.calcHist([img], [2], None, [256], [0, 256]) # 定义Gamma矫正的函数 def gamma_trans(img, gamma): # 具体做法是先归一化到1,然后gamma作为指数值求出新的像素值再还原 gamma_table = [np.power(x/255.0, gamma)*255.0 for x in range(256)] gamma_table = np.round(np.array(gamma_table)).astype(np.uint8) # 实现这个映射用的是OpenCV的查表函数 return cv2.LUT(img, gamma_table) # 执行Gamma矫正,小于1的值让暗部细节大量提升,同时亮部细节少量提升 img_corrected = gamma_trans(img, 0.5) cv2.imwrite('gamma_corrected.jpg', img_corrected) # 分通道计算Gamma矫正后的直方图 hist_b_corrected = cv2.calcHist([img_corrected], [0], None, [256], [0, 256]) hist_g_corrected = cv2.calcHist([img_corrected], [1], None, [256], [0, 256]) hist_r_corrected = cv2.calcHist([img_corrected], [2], None, [256], [0, 256]) # 将直方图进行可视化 import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D fig = plt.figure() pix_hists = [ [hist_b, hist_g, hist_r], [hist_b_corrected, hist_g_corrected, hist_r_corrected] ] pix_vals = range(256) for sub_plt, pix_hist in zip([121, 122], pix_hists): ax = fig.add_subplot(sub_plt, projection='3d') for c, z, channel_hist in zip(['b', 'g', 'r'], [20, 10, 0], pix_hist): cs = [c] * 256 ax.bar(pix_vals, channel_hist, zs=z, zdir='y', color=cs, alpha=0.618, edgecolor='none', lw=0) ax.set_xlabel('Pixel Values') ax.set_xlim([0, 256]) ax.set_ylabel('Channels') ax.set_zlabel('Counts') plt.show()
上面三段代码的结果统一放在下图中:

可以看到,Gamma变换后的暗部细节比起原图清楚了很多,并且从直方图来看,像素值也从集中在0附近变得散开了一些。
三、 图像的仿射变换
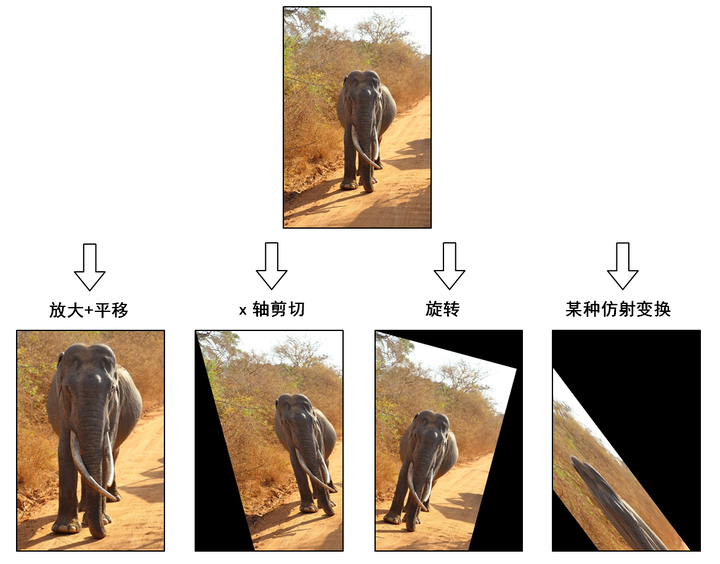
图像的仿射变换涉及到图像的形状位置角度的变化,是深度学习预处理中常到的功能,在此简单回顾一下。仿射变换具体到图像中的应用,主要是对图像的缩放,旋转,剪切,翻转和平移的组合。在OpenCV中,仿射变换的矩阵是一个2×3的矩阵,其中左边的2×2子矩阵是线性变换矩阵,右边的2×1的两项是平移项:
对于图像上的任一位置(x,y),仿射变换执行的是如下的操作:
需要注意的是,对于图像而言,宽度方向是x,高度方向是y,坐标的顺序和图像像素对应下标一致。所以原点的位置不是左下角而是右上角,y的方向也不是向上,而是向下。在OpenCV中实现仿射变换是通过仿射变换矩阵和cv2.warpAffine()这个函数,还是通过代码来理解一下,例子中图片的分辨率为600×400:
代码实现的操作示意在下图中:
import cv2 import numpy as np # 读取一张斯里兰卡拍摄的大象照片 img = cv2.imread('lanka_safari.jpg') # 沿着横纵轴放大1.6倍,然后平移(-150,-240),最后沿原图大小截取,等效于裁剪并放大 M_crop_elephant = np.array([ [1.6, 0, -150], [0, 1.6, -240] ], dtype=np.float32) img_elephant = cv2.warpAffine(img, M_crop_elephant, (400, 600)) cv2.imwrite('lanka_elephant.jpg', img_elephant) # x轴的剪切变换,角度15° theta = 15 * np.pi / 180 M_shear = np.array([ [1, np.tan(theta), 0], [0, 1, 0] ], dtype=np.float32) img_sheared = cv2.warpAffine(img, M_shear, (400, 600)) cv2.imwrite('lanka_safari_sheared.jpg', img_sheared) # 顺时针旋转,角度15° M_rotate = np.array([ [np.cos(theta), -np.sin(theta), 0], [np.sin(theta), np.cos(theta), 0] ], dtype=np.float32) img_rotated = cv2.warpAffine(img, M_rotate, (400, 600)) cv2.imwrite('lanka_safari_rotated.jpg', img_rotated) # 某种变换,具体旋转+缩放+旋转组合可以通过SVD分解理解 M = np.array([ [1, 1.5, -400], [0.5, 2, -100] ], dtype=np.float32) img_transformed = cv2.warpAffine(img, M, (400, 600)) cv2.imwrite('lanka_safari_transformed.jpg', img_transformed)
四、 基本绘图
OpenCV提供了各种绘图的函数,可以在画面上绘制线段,圆,矩形和多边形等,还可以在图像上指定位置打印文字,比如下面例子:
import numpy as np
import cv2
# 定义一块宽600,高400的画布,初始化为白色
canvas = np.zeros((400, 600, 3), dtype=np.uint8) + 255
# 画一条纵向的正中央的黑色分界线
cv2.line(canvas, (300, 0), (300, 399), (0, 0, 0), 2)
# 画一条右半部份画面以150为界的横向分界线
cv2.line(canvas, (300, 149), (599, 149), (0, 0, 0), 2)
# 左半部分的右下角画个红色的圆
cv2.circle(canvas, (200, 300), 75, (0, 0, 255), 5)
# 左半部分的左下角画个蓝色的矩形
cv2.rectangle(canvas, (20, 240), (100, 360), (255, 0, 0), thickness=3)
# 定义两个三角形,并执行内部绿色填充
triangles = np.array([
[(200, 240), (145, 333), (255, 333)],
[(60, 180), (20, 237), (100, 237)]])
cv2.fillPoly(canvas, triangles, (0, 255, 0))
# 画一个黄色五角星
# 第一步通过旋转角度的办法求出五个顶点
phi = 4 * np.pi / 5
rotations = [[[np.cos(i * phi), -np.sin(i * phi)], [i * np.sin(phi), np.cos(i * phi)]] for i in range(1, 5)]
pentagram = np.array([[[[0, -1]] + [np.dot(m, (0, -1)) for m in rotations]]], dtype=np.float)
# 定义缩放倍数和平移向量把五角星画在左半部分画面的上方
pentagram = np.round(pentagram * 80 + np.array([160, 120])).astype(np.int)
# 将5个顶点作为多边形顶点连线,得到五角星
cv2.polylines(canvas, pentagram, True, (0, 255, 255), 9)
# 按像素为间隔从左至右在画面右半部份的上方画出HSV空间的色调连续变化
for x in range(302, 600):
color_pixel = np.array([[[round(180*float(x-302)/298), 255, 255]]], dtype=np.uint8)
line_color = [int(c) for c in cv2.cvtColor(color_pixel, cv2.COLOR_HSV2BGR)[0][0]]
cv2.line(canvas, (x, 0), (x, 147), line_color)
# 如果定义圆的线宽大于半斤,则等效于画圆点,随机在画面右下角的框内生成坐标
np.random.seed(42)
n_pts = 30
pts_x = np.random.randint(310, 590, n_pts)
pts_y = np.random.randint(160, 390, n_pts)
pts = zip(pts_x, pts_y)
# 画出每个点,颜色随机
for pt in pts:
pt_color = [int(c) for c in np.random.randint(0, 255, 3)]
cv2.circle(canvas, pt, 3, pt_color, 5)
# 在左半部分最上方打印文字
cv2.putText(canvas,
'Python-OpenCV Drawing Example',
(5, 15),
cv2.FONT_HERSHEY_SIMPLEX,
0.5,
(0, 0, 0),
1)
cv2.imshow('Example of basic drawing functions', canvas)
cv2.waitKey()