


AI金融:利用LSTM预测股票每日最高价
第一部分:从RNN到LSTM
1、什么是RNN
RNN全称循环神经网络(Recurrent Neural Networks),是用来处理序列数据的。在传统的神经网络模型中,从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多关于时间序列的问题却无能无力。例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。RNN之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面时刻的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出,如下图所示:
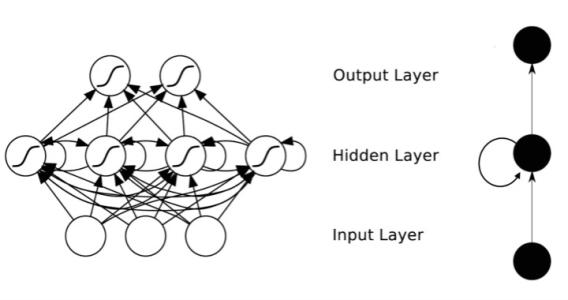
传统的神经网络中,数据从输入层输入,在隐藏层加工,从输出层输出。RNN不同的就是在隐藏层的加工方法不一样,后一个节点不仅受输入层输入的影响,还包受上一个节点的影响。
展开来就是这个样子:图中的xt−1,xt, xt+1代表不同时刻的输入,每个x都具有input layer的n维特征,依次进入循环神经网络以后,隐藏层输出st受到上一时刻st−1的隐藏层输出以及此刻输入层输入xt
的两方面影响。

缺点:RNN利用内部的记忆来处理任意时序的输入序列,并且在其处理单元之间既有内部的反馈连接又有前馈连接,这使得RNN可以更加容易处理不分段的文本等。但是由于RNN只能对部分序列进行记忆,所以在长序列上表现远不如短序列,造成了一旦序列过长便使得准确率下降的结果。
2、什么是LSTM
长短记忆神经网络——通常称作LSTM,是一种特殊的RNN,能够学习长的依赖关系。 他们由Hochreiter&Schmidhuber引入,并被许多人进行了改进和普及。他们在各种各样的问题上工作的非常好,现在被广泛使用。
LSTM是为了避免长依赖问题而精心设计的。 记住较长的历史信息实际上是他们的默认行为,而不是他们努力学习的东西。
所有循环神经网络都具有神经网络的重复模块链的形式。 在标准的RNN中,该重复模块将具有非常简单的结构,例如单个tanh层。

LSTM也拥有这种链状结构,但是重复模块则拥有不同的结构。与神经网络的简单的一层相比,LSTM拥有四层,这四层以特殊的方式进行交互。

LSTM背后的核心理念
LSTM的关键是细胞状态,表示细胞状态的这条线水平的穿过图的顶部。
细胞的状态类似于输送带,细胞的状态在整个链上运行,只有一些小的线性操作作用其上,信息很容易保持不变的流过整个链。
门(Gate)是一种可选地让信息通过的方式。 它由一个Sigmoid神经网络层和一个点乘法运算组成。

Sigmoid神经网络层输出0和1之间的数字,这个数字描述每个组件有多少信息可以通过, 0表示不通过任何信息,1表示全部通过
LSTM有三个门,用于保护和控制细胞的状态。
一步步的拆解LSTM
LSTM的第一步是决定我们要从细胞状态中丢弃什么信息。 该决定由被称为“忘记门”的Sigmoid层实现。它查看ht-1(前一个输出)和xt(当前输入),并为单元格状态Ct-1(上一个状态)中的每个数字输出0和1之间的数字。1代表完全保留,而0代表彻底删除。
让我们回到语言模型的例子,试图根据以前的语料来预测下一个单词。 在这样的问题中,细胞状态可能包括当前主题的性别,从而决定使用正确的代词。 当我们看到一个新主题时,我们想要忘记旧主题的性别。

下一步是决定我们要在细胞状态中存储什么信息。 这部分分为两步。 首先,称为“输入门层”的Sigmoid层决定了我们将更新哪些值。 接下来一个tanh层创建候选向量Ct,该向量将会被加到细胞的状态中。 在下一步中,我们将结合这两个向量来创建更新值。
在我们的语言模型的例子中,我们希望将新主题的性别添加到单元格状态,以替换我们忘记的旧对象。

现在是时候去更新上一个状态值Ct−1了,将其更新为Ct。签名的步骤以及决定了应该做什么,我们只需实际执行即可。
我们将上一个状态值乘以ft,以此表达期待忘记的部分。之后我们将得到的值加上 it∗C̃ t。这个得到的是新的候选值, 按照我们决定更新每个状态值的多少来衡量.
在语言模型的例子中,对应着实际删除关于旧主题性别的信息,并添加新信息,正如在之前的步骤中描述的那样。

最后,我们需要决定我们要输出什么。 此输出将基于我们的细胞状态,但将是一个过滤版本。 首先,我们运行一个sigmoid层,它决定了我们要输出的细胞状态的哪些部分。 然后,我们将单元格状态通过tanh(将值规范化到-1和1之间),并将其乘以Sigmoid门的输出,至此我们只输出了我们决定的那些部分。
对于语言模型的例子,由于只看到一个主题,考虑到后面可能出现的词,它可能需要输出与动词相关的信息。 例如,它可能会输出主题是单数还是复数,以便我们知道动词应该如何组合在一起。

3、股票预测实战1
在对理论有理解的基础上,我们使用LSTM对股票每日最高价进行预测。在本例中,仅使用一维特征。
数据格式如下:
本例取每日最高价作为输入特征[x],后一天的最高价最为标签[y]
步骤一、导入数据:

import pandas as pd import numpy as np import matplotlib.pyplot as plt import tensorflow f=open('stock_dataset.csv') df=pd.read_csv(f) #读入股票数据 data=np.array(df['最高价']) #获取最高价序列 data=data[::-1] #反转,使数据按照日期先后顺序排列 #以折线图展示data plt.figure() plt.plot(data) plt.show() normalize_data=(data-np.mean(data))/np.std(data) #标准化 normalize_data=normalize_data[:,np.newaxis] #增加维度 #———————————————————形成训练集————————————————————— #设置常量 time_step=20 #时间步 rnn_unit=10 #hidden layer units batch_size=60 #每一批次训练多少个样例 input_size=1 #输入层维度 output_size=1 #输出层维度 lr=0.0006 #学习率 train_x,train_y=[],[] #训练集 for i in range(len(normalize_data)-time_step-1): x=normalize_data[i:i+time_step] y=normalize_data[i+1:i+time_step+1] train_x.append(x.tolist()) train_y.append(y.tolist())
出来的train_x就是像这个样子:
1 2 3 | [[[-1.59618],……中间还有18个……, [-1.56340]] …… [[-1.59202] [-1.58244]]] |
是一个shape为[-1,time_step,input__size]的矩阵
步骤二、定义神经网络变量
X=tf.placeholder(tf.float32, [None,time_step,input_size]) #每批次输入网络的tensor Y=tf.placeholder(tf.float32, [None,time_step,output_size]) #每批次tensor对应的标签 #输入层、输出层权重、偏置 weights={ 'in':tf.Variable(tf.random_normal([input_size,rnn_unit])), 'out':tf.Variable(tf.random_normal([rnn_unit,1])) } biases={ 'in':tf.Variable(tf.constant(0.1,shape=[rnn_unit,])), 'out':tf.Variable(tf.constant(0.1,shape=[1,])) }
步骤三、定义lstm网络
def lstm(batch): #参数:输入网络批次数目 w_in=weights['in'] b_in=biases['in'] input=tf.reshape(X,[-1,input_size]) #需要将tensor转成2维进行计算,计算后的结果作为隐藏层的输入 input_rnn=tf.matmul(input,w_in)+b_in input_rnn=tf.reshape(input_rnn,[-1,time_step,rnn_unit]) #将tensor转成3维,作为lstm cell的输入 cell=tf.nn.rnn_cell.BasicLSTMCell(rnn_unit) init_state=cell.zero_state(batch,dtype=tf.float32) output_rnn,final_states=tf.nn.dynamic_rnn(cell, input_rnn,initial_state=init_state, dtype=tf.float32) #output_rnn是记录lstm每个输出节点的结果,final_states是最后一个cell的结果 output=tf.reshape(output_rnn,[-1,rnn_unit]) #作为输出层的输入 w_out=weights['out'] b_out=biases['out'] pred=tf.matmul(output,w_out)+b_out return pred,final_states
步骤四、训练模型
def train_lstm(): global batch_size pred,_=rnn(batch_size) #损失函数 loss=tf.reduce_mean(tf.square(tf.reshape(pred,[-1])-tf.reshape(Y, [-1]))) train_op=tf.train.AdamOptimizer(lr).minimize(loss) saver=tf.train.Saver(tf.global_variables()) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) #重复训练10000次 for i in range(10000): step=0 start=0 end=start+batch_size while(end<len(train_x)): _,loss_=sess.run([train_op,loss],feed_dict={X:train_x[start:end],Y:train_y[start:end]}) start+=batch_size end=start+batch_size #每10步保存一次参数 if step%10==0: print(i,step,loss_) print("保存模型:",saver.save(sess,'stock.model')) step+=1
步骤五、预测模型
def prediction(): pred,_=lstm(1) #预测时只输入[1,time_step,input_size]的测试数据 saver=tf.train.Saver(tf.global_variables()) with tf.Session() as sess: #参数恢复 module_file = tf.train.latest_checkpoint(base_path+'module2/') saver.restore(sess, module_file) #取训练集最后一行为测试样本。shape=[1,time_step,input_size] prev_seq=train_x[-1] predict=[] #得到之后100个预测结果 for i in range(100): next_seq=sess.run(pred,feed_dict={X:[prev_seq]}) predict.append(next_seq[-1]) #每次得到最后一个时间步的预测结果,与之前的数据加在一起,形成新的测试样本 prev_seq=np.vstack((prev_seq[1:],next_seq[-1])) #以折线图表示结果 plt.figure() plt.plot(list(range(len(normalize_data))), normalize_data, color='b') plt.plot(list(range(len(normalize_data), len(normalize_data) + len(predict))), predict, color='r') plt.show()
例子中只有把最高价作为特征,去预测之后的最高价趋势,下一讲会增加输入的特征维度,把最低价、开盘价、收盘价、交易额等作为输入的特征对之后的最高价进行预测。
最终运行结果显示:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架