大数据相关技术汇总了解
一、clickhouse详解
一 clickhouse-简介
ClickHouse是俄罗斯的Yandex于2016年开源的一个用于联机分析(OLAP:Online Analytical Processing)的列式数据库管理系统(DBMS:Database Management System) , 主要用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告。 ClickHouse的全称是Click Stream,Data WareHouse,简称ClickHouse
ClickHouse是一个完全的列式分布式数据库管理系统(DBMS),允许在运行时创建表和数据库,加载数据和运行查询,而无需重新配置和重新启动服务器,支持线性扩展,简单方便,高可靠性,容错。它在大数据领域没有走 Hadoop 生态,而是采用 Local attached storage 作为存储,这样整个 IO 可能就没有 Hadoop 那一套的局限。它的系统在生产环境中可以应用到比较大的规模,因为它的线性扩展能力和可靠性保障能够原生支持 shard + replication 这种解决方案。它还提供了一些 SQL 直接接口,有比较丰富的原生 client。
1 优点
-
灵活的MPP架构,支持线性扩展,简单方便,高可靠性
-
多服务器分布式处理数据 ,完备的DBMS系统
-
底层数据列式存储,支持压缩,优化数据存储,优化索引数据 优化底层存储
-
容错跑分快:比Vertica快5倍,比Hive快279倍,比MySQL快800倍,其可处理的数据级别已达到10亿级别
-
功能多:支持数据统计分析各种场景,支持类SQL查询,异地复制部署
-
海量数据存储,分布式运算,快速闪电的性能,几乎实时的数据分析 ,友好的SQL语法,出色的函数支持
2 缺点
- 不支持事务,不支持真正的删除/更新 (批量)
- 不支持高并发,官方建议qps为100,可以通过修改配置文件增加连接数,但是在服务器足够好的情况下
- 不支持二级索引
- 不擅长多表join 大宽表
- 元数据管理需要人为干预
- 尽量做1000条以上批量的写入,避免逐行insert或小批量的insert,update,delete操作
3 应用场景
- 1.绝大多数请求都是用于读访问的, 要求实时返回结果
- 2.数据需要以大批次(大于1000行)进行更新,而不是单行更新;或者根本没有更新操作
- 3.数据只是添加到数据库,没有必要修改
- 4.读取数据时,会从数据库中提取出大量的行,但只用到一小部分列
- 5.表很“宽”,即表中包含大量的列
- 6.查询频率相对较低(通常每台服务器每秒查询数百次或更少)
- 7.对于简单查询,允许大约50毫秒的延迟
- 8.列的值是比较小的数值和短字符串(例如,每个URL只有60个字节)
- 9.在处理单个查询时需要高吞吐量(每台服务器每秒高达数十亿行)
- 10.不需要事务
- 11.数据一致性要求较低 [原子性 持久性 一致性 隔离性]
- 12.每次查询中只会查询一个大表。除了一个大表,其余都是小表
- 13.查询结果显著小于数据源。即数据有过滤或聚合。返回结果不超过单个服务器内存大小
4 核心概念
1) 数据分片
数据分片是将数据进行横向切分,这是一种在面对海量数据的场 景下,解决存储和查询瓶颈的有效手段,是一种分治思想的体现。
ClickHouse支持分片,而分片则依赖集群。每个集群由1到多个分片组成,而每个分片则对应了ClickHouse的1个服务节点。分片的数量
上限 取决于节点数量(1个分片只能对应1个服务节点)。ClickHouse并不像其他分布式系统那样,拥有高度自动化的分片功能。
ClickHouse提供了本地表(Local Table)与分布式表(Distributed Table)的概念。一张本地表等同于一份数据的分片。而分布式表本
身不存储任何数据,它是本地表的访问代理,其作用类似分库中间件。借助分布式表,能够代理访问多个数据分片,从而实现分布式查
询。这种设计类似数据库的分库和分表,十分灵活。例如在业务系统上线的初期,数据体量并不高,此时数据表并不需要多个分片。所以
使用单个节点的本地表(单个数据分片)即可满足业务需求,待到业务增长、数据量增大的时候,再通过新增数据分片的方式分流数据,
并通过分布式表实现分布式查询。这就好比一辆手动挡赛车,它将所有的选择权都交到了使用者的手中!
2) 列式存储
1)如前所述,分析场景中往往需要读大量行但是少数几个列。在行存模式下,数据按行连续存储,所有列的数据都存储在一个bloCK中,不参与计算的列在IO时也要全部读出,读取操作被严重放大。而列存模式下,只需要读取参与计算的列即可,极大的减低了IO cost,加速了查询。
2)同一列中的数据属于同一类型,压缩效果显著。列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。
3)更高的压缩比意味着更小的data size,从磁盘中读取相应数据耗时更短。
4)自由的压缩算法选择。不同列的数据具有不同的数据类型,适用的压缩算法也就不尽相同。可以针对不同列类型,选择最合适的压缩算法。
5)高压缩比,意味着同等大小的内存能够存放更多数据,系统cache效果更好。
官方数据显示,通过使用列存,在某些分析场景下,能够获得100倍甚至更高的加速效应。
3) 向量化
ClickHouse不仅将数据按列存储,而且按列进行计算。传统OLTP数据库通常采用按行计算,原因是事务处理中以点查为主,SQL计算量小,实现这些技术的收益不够明显。但是在分析场景下,单个SQL所涉及计算量可能极大,将每行作为一个基本单元进行处理会带来严重的性能损耗:
1)对每一行数据都要调用相应的函数,函数调用开销占比高;
2)存储层按列存储数据,在内存中也按列组织,但是计算层按行处理,无法充分利用CPU cache的预读能力,造成CPU Cache miss严重;
3)按行处理,无法利用高效的SIMD指令;
ClickHouse实现了向量执行引擎(Vectorized execution engine),对内存中的列式数据,一个batch调用一次SIMD指令(而非每一行调用一次),不仅减少了函数调用次数、降低了cache miss,而且可以充分发挥SIMD指令的并行能力,大幅缩短了计算耗时。向量执行引擎,通常能够带来数倍的性能提升。
(SIMD全称Single Instruction Multiple Data,单指令多数据流,能够复制多个操作数,并把它们打包在大型寄存器的一组指令集。以同步方式,在同一时间内执行同一条指令。)
-
表
上层数据的视图展示概念 ,包括表的基本结构和数据 -
分区
ClickHouse支持PARTITION BY子句,在建表时可以指定按照任意合法表达式进行数据分区操作,比如通过toYYYYMM()将数据按月进行分区、toMonday()将数据按照周几进行分区、对Enum类型的列直接每种取值作为一个分区等。数据以分区的形式统一管理和维护一批数据! -
副本
数据存储副本,在集群模式下实现高可用 , 简单理解就是相同的数据备份,在CK中通过复制集,我们实现保障了数据可靠性外,也通过多副本的方式,增加了CK查询的并发能力。这里一般有2种方式:(1)基于ZooKeeper的表复制方式;(2)基于Cluster的复制方式。由于我们推荐的数据写入方式本地表写入,禁止分布式表写入,所以我们的复制表只考虑ZooKeeper的表复制方案。 -
引擎 必须指定引擎
不同的引擎决定了表数据的存储特点,位置和表数据的操作行为:
-
决定表存储在哪里以及以何种方式存储
-
支持哪些查询以及如何支持
-
并发数据访问
-
索引的使用
-
是否可以执行多线程请求
-
数据是否存储副本
-
并发操作 insert into tb_x select * from tb_x ;
表引擎决定了数据在文件系统中的存储方式,常用的也是官方推荐的存储引擎是MergeTree系列,如果需要数据副本的话可以使用ReplicatedMergeTree系列,相当于MergeTree的副本版本。读取集群数据需要使用分布式表引擎Distribute。
二、阿里云Tablestore数据源详解
表格存储Tablestore是构建在阿里云飞天分布式系统之上的NoSQL数据存储服务,Tablestore数据源为您提供读取和写入Tablestore双向通道的功能,本文为您介绍DataWorks的Tablestore数据同步的能力支持情况。
使用限制
-
Tablestore Reader和Writer插件实现了从Tablestore读取和写入数据,包含行模式、列模式两种数据读取与写入方式,可针对宽表与时序表进行数据读取与写入。
-
列模式:在Tablestore多版本模型下,表中的数据组织为*行* > *列* > *版本***三级的模式, 一行可以有任意列,列名并不是固定的,每一列可以含有多个版本,每个版本都有一个特定的时间戳(版本号)。列模式会将数据导出为(主键值,列名,时间戳,列值)的四元组格式,列模式下导入的数据也是(主键值,列名,时间戳,列值)的四元组格式。
-
行模式:该模式将用户每次更新的记录,抽取成行的形式导出,即(主键值,列值)的格式。
行模式下每一行数据对应TableStore表中的一条数据。写入行模式的数据包含主键列列值、普通列列值两部分。
-
-
Tablestore列由主键列primaryKey+普通列column组成,源端列顺序需要和Tablestore目的端主键列+普通列保持一致,否则会产生列映射错误。
-
Tablestore Reader会根据一张表中待读取的数据的范围,按照数据同步并发的数目N,将范围等分为N份Task。每个Task都会有一个Tablestore Reader线程来执行。
支持的字段类型
目前Tablestore Reader和Tablestore Writer支持所有Tablestore类型,其针对Tablestore类型的转换列表,如下所示。
| 类型分类 | Tablestore数据类型 |
|---|---|
| 整数类 | INTEGER |
| 浮点类 | DOUBLE |
| 字符串类 | STRING |
| 布尔类 | BOOLEAN |
| 二进制类 | BINARY |
- Tablestore本身不支持日期型类型。应用层通常使用Long保存时间的Unix TimeStamp。
- 您需要将INTEGER类型的数据,在脚本模式中配置为INT类型,DataWorks会将其转换为INTEGER类型。如果您直接配置为INTEGER类型,日志将会报错,导致任务无法顺利完成。
数据同步任务开发
Tablestore数据同步任务的配置入口和通用配置流程指导可参见下文的配置指导,详细的配置参数解释可在配置界面查看对应参数的文案提示。
创建数据源
在进行数据同步任务开发时,您需要在DataWorks上创建一个对应的数据源,操作流程请参见创建与管理数据源。
单表离线同步任务配置指导
- 操作流程请参见通过脚本模式配置离线同步任务。
- 脚本模式配置的全量参数和脚本Demo请参见下文的附录:Writer脚本Demo与参数说明。
三、Hive数据仓库
前言:
为什么要学习Hive?
Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。
hive是十分适合数据仓库的统计分析,处理一些大型数据集,比传统数据仓库更加高效快捷。
一、Hive的概述
1、什么是Hive?
Hive是基于Hadoop的数据仓库工具。可以用于存储在Hadoop集群中的HDFS文件数据集进行数据整理、特殊查询和分析处理。Hive提供了类似于关系型数据库SQL语言的HiveQL工具,通过HiveQL可以快速实现简单的MapReduce统计。
Hive的本质就是将HiveQL语句转换为MapReduce任务后运行,非常适合做数据仓库的数据分析。
2、Hive的应用场景
Hive构建在Hadoop文件系统之上,Hive不提供实时的查询和基于行级的数据更新操作,不适合需要低延迟的应用,如联机事务处理(On-line Transaction Processing,OLTP)相关应用。
Hive适用于联机分析处理(On-Line Analytical Processing,OLAP),应用场景如图所示:
3、Hive的特性
Hive作为数据仓库软件,使用类SQL的HiveQL语言实现数据查询,所有Hive数据均存储在Hadoop文件系统中,Hive具有以下特性。
1)使用HiveQL以类SQL查询的方式轻松访问数据,将HiveQL查询转换为MapReduce的任务在Hadoop集群上执行,完成ETL(Extract、Transform、Load,提取、转换、加载)、报表、数据分析等数据仓库任务。HiveQL内置大量UDF(User Defined Function)来操作时间、字符串和其他的数据挖掘工具,支持用户扩展UDF函数来完成内置函数无法实现的操作。
2)多种文件格式的元数据服务,包括TextFile、SequenceFile、RCFile和ORCFile,其中TextFile为默认格式,创建SequenceFile、RCFile和ORCFile格式的表需要先将文件数据导入到TextFile格式的表中,然后再把TextFile表的数据导入SequenceFile、RCFile和ORCFile表中。
3)直接访问HDFS文件或其他数据存储系统(如HBase)中的文件。 ·
4)支持MapReduce、Tez、Spark等多种计算引擎,可根据不同的数据处理场景选择合适的计算引擎。
5)支持HPL/SQL程序语言,HPL/SQL是一种混合异构的语言,可以理解几乎任何现有的过程性SQL语言(如Oracle PL/SQL、Transact-SQL)的语法和语义,有助于将传统数据仓库的业务逻辑迁移到Hadoop上,是在Hadoop中实现ETL流程的有效方式。
6)可以通过HiveLLAP(Live Long and Process)、Apache YARN和Apache Slider(动态YARN应用,可按需动态调整分布式应用程序的资源)进行秒级的查询检索。LLAP结合了持久查询服务器和优化的内存缓存,使Hive能够立即启动查询,避免不必要的磁盘开销,提供较佳的查询检索效率。
4、Hive与传统数据仓库的区别
Hive是用于查询分布式大型数据集的数据仓库,相比于传统数据仓库,在大数据的查询上有其独特的优势,但同时也牺牲了一部分性能,如下图:

背景信息
Hive是基于Hadoop的数据仓库工具,用于解决海量结构化日志的数据统计。Hive可以将结构化的数据文件映射为一张表,并提供SQL查询功能。Hive的本质是一个SQL解析引擎,其底层通过MapReduce实现数据分析,使用HDFS存储处理的数据,将HQL转化为MapReduce程序并在Yarn上运行。
Hive Reader插件通过访问HiveMetastore服务,获取您配置的数据表的元数据信息。您可以基于HDFS文件和Hive JDBC两种方式读取数据:
-
基于HDFS文件读取数据
Hive Reader插件通过访问HiveMetastore服务,解析出您配置的数据表的HDFS文件存储路径、文件格式、分隔符等信息后,再通过读取HDFS文件的方式读取Hive中的表数据。
-
基于Hive JDBC读取数据
Hive Reader插件通过Hive JDBC客户端连接HiveServier2服务读取数据。Hive Reader支持通过where条件过滤数据,并支持直接通过SQL读取数据。
Hive Writer插件通过访问Hive Metastore服务,解析出您配置的数据表的HDFS文件存储路径、文件格式和分隔符等信息。通过读取HDFS文件的方式,从Hive写出数据至HDFS。再通过Hive JDBC客户端执行LOAD DATA SQL语句,加载HDFS文件中的数据至Hive表。
Hive Writer底层的逻辑和HDFS Writer插件一致,您可以在Hive Writer插件参数中配置HDFS Writer相关的参数,配置的参数会透传给HDFS Writer插件。
四、Kafka基本原理
一、概念理解
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源 项目。
(1)产生背景
当今社会各种应用系统诸如商业、社交、搜索、浏览等像信息工厂一样不断的生产出各种信息,在大数据时代,我们面临如下几个挑战:
- 如何收集这些巨大的信息
- 如何分析它
- 如何及时做到如上两点
以上几个挑战形成了一个业务需求模型,即生产者生产(produce)各种信息,消费者消费(consume)(处理分析)这些信息,而在生产者与消费者之间,需要一个沟通两者的桥梁-消息系统。从一个微观层面来说,这种需求也可理解为不同的系统之间如何传递消息。
Kafka诞生
Kafka由 linked-in 开源
kafka-即是解决上述这类问题的一个框架,它实现了生产者和消费者之间的无缝连接。
kafka-高产出的分布式消息系统(A high-throughput distributed messaging system)
(2)Kafka的特性
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
(3)Kafka场景应用
- 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
- 消息系统:解耦和生产者和消费者、缓存消息等。
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
- 流式处理:比如spark streaming和storm
- 事件源
(4)Kafka一些重要设计思想
- Consumergroup:各个consumer可以组成一个组,每个消息只能被组中的一个consumer消费,如果一个消息可以被多个consumer消费的话,那么这些consumer必须在不同的组。
- 消息状态:在Kafka中,消息的状态被保存在consumer中,broker不会关心哪个消息被消费了被谁消费了,只记录一个offset值(指向partition中下一个要被消费的消息位置),这就意味着如果consumer处理不好的话,broker上的一个消息可能会被消费多次。
- 消息持久化:Kafka中会把消息持久化到本地文件系统中,并且保持极高的效率。
- 消息有效期:Kafka会长久保留其中的消息,以便consumer可以多次消费,当然其中很多细节是可配置的。
- 批量发送:Kafka支持以消息集合为单位进行批量发送,以提高push效率。
- push-and-pull :Kafka中的Producer和consumer采用的是push-and-pull模式,即Producer只管向broker push消息,consumer只管从broker pull消息,两者对消息的生产和消费是异步的。
- Kafka集群中broker之间的关系:不是主从关系,各个broker在集群中地位一样,我们可以随意的增加或删除任何一个broker节点。
- 负载均衡方面: Kafka提供了一个 metadata API来管理broker之间的负载(对Kafka0.8.x而言,对于0.7.x主要靠zookeeper来实现负载均衡)。
- 同步异步:Producer采用异步push方式,极大提高Kafka系统的吞吐率(可以通过参数控制是采用同步还是异步方式)。
- 分区机制partition:Kafka的broker端支持消息分区,Producer可以决定把消息发到哪个分区,在一个分区中消息的顺序就是Producer发送消息的顺序,一个主题中可以有多个分区,具体分区的数量是可配置的。分区的意义很重大,后面的内容会逐渐体现。
- 离线数据装载:Kafka由于对可拓展的数据持久化的支持,它也非常适合向Hadoop或者数据仓库中进行数据装载。
- 插件支持:现在不少活跃的社区已经开发出不少插件来拓展Kafka的功能,如用来配合Storm、Hadoop、flume相关的插件。
五、Elasticsearch
一.Elasticsearch介绍
Elasticsearch 是一个分布式、可扩展、实时的搜索与数据分析引擎。 它能从项目一开始就赋予你的数据以搜索、分析和探索的能力,这是通常没有预料到的。 它存在还因为原始数据如果只是躺在磁盘里面根本就毫无用处。
无论你是需要全文搜索,还是结构化数据的实时统计,或者两者结合,这本指南都能帮助你了解其中最基本的概念, 从最基本的操作开始学习 Elasticsearch。之后,我们还会逐渐开始探索更加高级的搜索技术,不断提升搜索体验来满足你的需求。
二.现有技术栈说明
在大多数应用中,多数实体或对象可以被序列化为包含键值对的 JSON 对象。 一个 键 可以是一个字段或字段的名称,一个 值 可以是一个字符串,一个数字,一个布尔值, 另一个对象,一些数组值,或一些其它特殊类型诸如表示日期的字符串,或代表一个地理位置的对象:
"name": "John Smith",
"age": 42,
"confirmed": true,
"join_date": "2014-06-01",
"home": {
"lat": 51.5,
"lon": 0.1
},
"accounts": [
{
"type": "facebook",
"id": "johnsmith"
},
{
"type": "twitter",
"id": "johnsmith"
}
]}
通常情况下,我们使用的术语 对象 和 文档 是可以互相替换的。不过,有一个区别: 一个对象仅仅是类似于 hash 、 hashmap 、字典或者关联数组的 JSON 对象,对象中也可以嵌套其他的对象。 对象可能包含了另外一些对象。在 Elasticsearch 中,术语 文档 有着特定的含义。它是指最顶层或者根对象, 这个根对象被序列化成 JSON 并存储到 Elasticsearch 中,指定了唯一 ID。
三.我们的架构方案分析
一个文档不仅仅包含它的数据 ,也包含 元数据 —— 有关 文档的信息。 三个必须的元数据元素如下:
_index:文档在哪存放
_type:文档表示的对象类别
_id:文档唯一标识
_index
一个 索引 应该是因共同的特性被分组到一起的文档集合。 例如,你可能存储所有的产品在索引 products 中,而存储所有销售的交易到索引 sales 中。 虽然也允许存储不相关的数据到一个索引中,但这通常看作是一个反模式的做法。
实际上,在 Elasticsearch 中,我们的数据是被存储和索引在 分片 中,而一个索引仅仅是逻辑上的命名空间, 这个命名空间由一个或者多个分片组合在一起。 然而,这是一个内部细节,我们的应用程序根本不应该关心分片,对于应用程序而言,只需知道文档位于一个 索引 内。 Elasticsearch 会处理所有的细节。
我们将在 索引管理 介绍如何自行创建和管理索引,但现在我们将让 Elasticsearch 帮我们创建索引。 所有需要我们做的就是选择一个索引名,这个名字必须小写,不能以下划线开头,不能包含逗号。我们用 website 作为索引名举例。
_type
数据可能在索引中只是松散的组合在一起,但是通常明确定义一些数据中的子分区是很有用的。 例如,所有的产品都放在一个索引中,但是你有许多不同的产品类别,比如 "electronics" 、 "kitchen" 和 "lawn-care"。
这些文档共享一种相同的(或非常相似)的模式:他们有一个标题、描述、产品代码和价格。他们只是正好属于“产品”下的一些子类。
Elasticsearch 公开了一个称为 types (类型)的特性,它允许您在索引中对数据进行逻辑分区。不同 types 的文档可能有不同的字段,但最好能够非常相似。 我们将在 类型和映射 中更多的讨论关于 types 的一些应用和限制。
一个 _type 命名可以是大写或者小写,但是不能以下划线或者句号开头,不应该包含逗号, 并且长度限制为256个字符. 我们使用 blog 作为类型名举例。
_id
ID 是一个字符串,当它和 _index 以及 _type 组合就可以唯一确定 Elasticsearch 中的一个文档。 当你创建一个新的文档,要么提供自己的 _id ,要么让 Elasticsearch 帮你生成。
六、阿里云大数据开发治理平台DataWorks
DataWorks基于MaxCompute、Hologres、EMR、AnalyticDB、CDP等大数据引擎,为数据仓库、数据湖、湖仓一体等解决方案提供统一的全链路大数据开发治理平台。从2009年起,DataWorks不断沉淀阿里巴巴大数据建设方法论,支撑数据中台建设,同时与数万名政务、央国企、金融、零售、互联网、能源、制造、工业等行业的客户携手,不断提升数据应用效率,助力产业数字化升级。
七、Hadoop 架构基础
1、Hadoop 是什么
- Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构。
- 主要解决,海量数据的存储和海量数据的分析计算问题。
- 广义上来说,Hadoop 通常是指一个更广泛的概念 —— Hadoop 生态圈。
2、Hadoop 三大发行版本
Apache、Cloudera、Hortonworks
Apache 版本最原始(最基础)的版本,对于入门学习最好。
Cloudera在大型互联网企业中用的较多。
① 2008 年成立的 Cloudera 是最早将 Hadoop 商用的公司,为合作伙伴提供 Hadoop 的商用解决方案,主要是包括支持、咨询服务、培训。
② 2009 年 Hadoop 的创始人 Doug Cutting 也加盟 Cloudera 公司。Cloudera 产品主要为 CDH,Cloudera Manager,Cloudera Support。
③ CDH 是Cloudera 的 Hadoop 发行版,完全开源,比 Apache Hadoop 在兼容性,安全性,稳定性上有所增强。
④ Cloudera Manager 是集群的软件分发及管理监控平台,可以在几个小时内部署好一个 Hadoop 集群,并对集群的节点及服务进行实时监控。Cloudera Support 即是对 Hadoop 的技术支持。
⑤ Cloudera 的标价为每年每个节点 4000 美元。Cloudera 开发并贡献了可实时处理大数据的 Impala 项目。
Hortonworks 文档较好。
① 2011 年成立的 Hortonworks 是雅虎与硅谷风投公司 Benchmark Capital 合资组建。
② 公司成立之初就吸纳了大约 25 名至 30 名专门研究Hadoop的雅虎工程师,上述工程师均在 2005 年开始协助雅虎开发 Hadoop,贡献了 Hadoop 80% 的代码。
③ 雅虎工程副总裁、雅虎 Hadoop 开发团队负责人 Eric Baldeschwieler 出任 Hortonworks 的首席执行官。
④ Hortonworks 的主打产品是 Hortonworks Data Platform(HDP),也同样是 100% 开源的产品,HDP 除常见的项目外还包括了 Ambari,一款开源的安装和管理系统。
⑤ HCatalog,一个元数据管理系统,HCatalog 现已集成到 Facebook 开源的 Hive 中。Hortonworks 的 Stinger 开创性的极大的优化了 Hive 项目。Hortonworks 为入门提供了一个非常好的,易于使用的沙盒。
⑥ Hortonworks 开发了很多增强特性并提交至核心主干,这使得 Apache Hadoop 能够在包括 Window Server 和 Windows Azure 在内的 microsoft Windows 平台上本地运行。定价以集群为基础,每10 个节点每年为 12500 美元。
Hadoop 的优势
高可靠性: Hadoop 底层维护多个数据副本,所以即使 Hadoop 某个计算元素或存储出现故障,也不会导致数据的丢失。
高扩展性: 在集群间分配任务数据,可方便的扩展数以千计的节点。
高效性: 在 MapReduce 的思想下,Hadoop 是并行工作的,以加快任务处理速度。
高容错性: 能够自动将失败的任务重新分配。
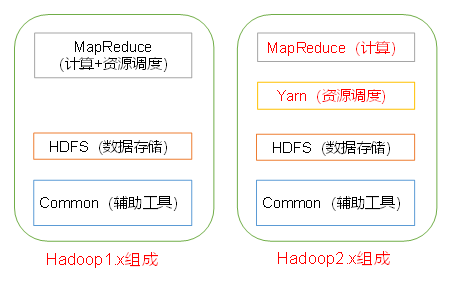
1.5 Hadoop 的组成
- Hadoop 1.x 和 hadoop 2.x 的区别
七、kibana
Kibana 是为 Elasticsearch设计的开源分析和可视化平台。你可以使用 Kibana 来搜索,查看存储在 Elasticsearch 索引中的数据并与之交互。你可以很容易实现高级的数据分析和可视化,以图表的形式展现出来。
使用前我们肯定需要先有Elasticsearch啦,安装使用Elasticsearch可以参考Elasticsearch构建全文搜索系统
特别需要注意的是,控制台可以非常方便的来调用es的api,强烈推荐使用
长这样

我们可以直接使用查询栏编写语句查询


控制台插件提供一个用户界面来和 Elasticsearch 的 REST API 交互。控制台有两个主要部分: editor ,用来编写提交给 Elasticsearch 的请求; response 面板,用来展示请求结果的响应。在页面顶部的文本框中输入 Elasticsearch 服务器的地址。默认地址是:“localhost:9200”。
点击左侧栏的[Dev Tools],可以看到如下界面,可以很方便地执行命令

# 查看所有节点
GET _cat/nodes
# 查看book索引数据
GET book/_search
{
"query": {
"match": {
"content": "chenqionghe"
}
}
}
# 添加一条数据
POST book/_doc
{
"page":8,
"content": "chenqionghe喜欢运动,绳命是如此的精彩,绳命是多么的辉煌"
}
# 更新数据
PUT book/_doc/iSAz4XABrERdg9Ao0QZI
{
"page":8,
"content":"chenqionghe喜欢运动,绳命是剁么的回晃;绳命是入刺的井猜"
}
# 删除数据
POST book/_delete_by_query
{
"query": {
"match": {
"page": 8
}
}
}
# 批量插入数据
POST book/_bulk
{ "index":{} }
{ "page":22 , "content": "Adversity, steeling will strengthen body.逆境磨练意志,锻炼增强体魄。"}
{ "index":{} }
{ "page":23 , "content": "Reading is to the mind, such as exercise is to the body.读书之于头脑,好比运动之于身体。"}
{ "index":{} }
{ "page":24 , "content": "Years make you old, anti-aging.岁月催人老,运动抗衰老。"}
{ "index":{} }
具体语法可自行搜索学习,后续会补充。
以上内容均来自互联网整理,如有侵权请联系博主删除。
