学习笔记(十一)——数据库的索引碎片、计划缓存、统计信息
1.索引碎片
数据库存储本身是无序的,建立了聚集索引,会按照聚集索引物理顺序存入硬盘。既键值的逻辑顺序决定了表中相应行的物理顺序
而且在大多数的情况下,数据库写入频率远低于读取频率,索引的存在为了读取速度牺牲写入速度(页 为最小单位 8kb,区 物理连续的页(8页)的集合)
其内部碎片 数据库页内部产生的碎片,外部反之。
查询碎片情况:
- dbcc showcontig:四部分对象名,【索引名】|【索引id】
- dbcc showcontig:当前库对象id,【索引名】|【索引id】
- sys.dm_db_index_physical_stats:数据库id,对象id,索引id,分区id,扫描模式 ‘
实例:
显示数据库里所有索引的碎片信息
SET NOCOUNT ON
USE pubs
DBCC SHOWCONTIG WITH ALL_INDEXES
GO
显示指定表的所有索引的碎片信息
SET NOCOUNT ONUSE pubs
DBCC SHOWCONTIG (authors) WITH ALL_INDEXES
GO
显示指定索引的碎片信息
SET NOCOUNT ON
USE pubs
DBCC SHOWCONTIG (authors,aunmind)
GO
2.计划缓存
平时所写的SQL语句本质只是获取数据的逻辑,而不是获取数据的物理路径。当我们写的SQL语句传到SQL Server的时候,查询分析器会将语句依次进行解析(Parse)、绑定(Bind)、查询优化(Optimization,有时候也被称为简化)、执行(Execution)。除去执行步骤外,前三个步骤之后就生成了执行计划,也就是SQL Server按照该计划获取物理数据方式,最后执行步骤按照执行计划执行查询从而获得结果。但查询优化器不是本篇的重点,本篇文章主要讲述查询优化器在生成执行计划之后,缓存执行计划的相关机制以及常见问题。
1: SELECT * 2: FROM A INNER JOIN B ON a.a=b.b 3: INNER JOIN C ON c.c=a.a
实例:
通过动态管理视图和函数,查看当前缓存的所有执行计划 SELECT/*PlanCache*/ ISNULL(QS.execution_count,0) AS ExecutionCount ,CP.usecounts AS LookupCount ,CP.objtype AS ObjectType ,ST.text AS Sql ,QP.query_plan AS QueryPlan FROM sys.dm_exec_cached_plans AS CP LEFT JOIN sys.dm_exec_query_stats AS QS ON CP.plan_handle=QS.plan_handle CROSS APPLY sys.dm_exec_sql_text(CP.plan_handle) AS ST CROSS APPLY sys.dm_exec_query_plan(CP.plan_handle) AS QP WHERE ST.text NOT LIKE 'SELECT/*PlanCache*/%' ORDER BY QS.last_execution_time ASC;
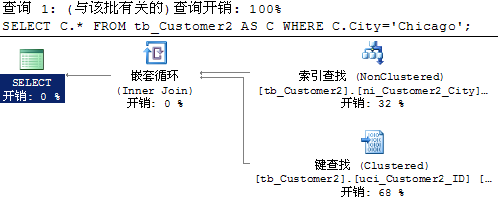
3.统计信息
Sqlserver 查询是基于开销查询的,在首次生成执行计划时,是基于多阶段的分析优化才确定出较好的执行计划。而这些开销的基数估计,是根据统计信息来确定的。统计信息其实就是对表的各个字段的总体数据进行分段分布,数据库默认都会自动维护。
表和视图都有统计信息,统计信息对象是根据索引或表列的列表创建的。当某列第一次最为条件查询时,将创建单列的统计信息。当创建索引时,将创建同名的统计信息。索引中,统计信息只统计首列,因此索引除了按首列排序存储数据外,其统计信息也是按首列计算统计的,所以索引设置时定义的第一列非常重要。每个统计信息对象都在包含一个或多个表列的列表上创建,并且包括显示值在第一列中的分布的直方图。
实例:
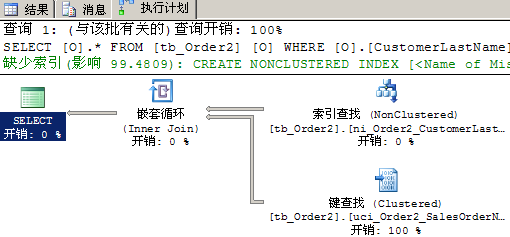
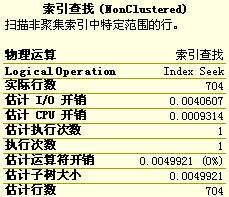
SELECT
O.*
FROM
tb_Order2 AS O
WHERE
O.CustomerLastName='Adams';

 浙公网安备 33010602011771号
浙公网安备 33010602011771号