
多层神经网络python实现
引言:神经网络在线教程有很多,如Andrew NG的deep leaning课程或者Michael Nielsen的在线教程《neural networks and deep learning》都讲述的很详细,只要认真听课,很好上手的。
循序渐进构建L层神经网络:
1.初始化参数
1)初始化两层神经网络参数,模型结构LINEAR -> RELU ——> LINEAR -> SIGMOID
def initialize_parameters(n_x, n_h, n_y): """ Argument: n_x -- size of the input layer n_h -- size of the hidden layer n_y -- size of the output layer Returns: parameters -- python dictionary containing your parameters: W1 -- weight matrix of shape (n_h, n_x) b1 -- bias vector of shape (n_h, 1) W2 -- weight matrix of shape (n_y, n_h) b2 -- bias vector of shape (n_y, 1) """ np.random.seed(1) W1 = np.random.randn(n_h, n_x) * 0.01 b1 = np.zeros(shape=(n_h, 1)) W2 = np.random.randn(n_y, n_h) * 0.01 b2 = np.zeros(shape=(n_y, 1)) assert(W1.shape == (n_h, n_x)) assert(b1.shape == (n_h, 1)) assert(W2.shape == (n_y, n_h)) assert(b2.shape == (n_y, 1)) parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2} return parameters
2)递归初始化L层神经网络参数,模型结构[LINEAR -> RELU] *(L-1) -——> LINEAR -> SIGMOID
def initialize_parameters_deep(layer_dims): """ Arguments: layer_dims -- python array (list) containing the dimensions of each layer in our network Returns: parameters -- python dictionary containing your parameters "W1", "b1", ..., "WL", "bL": Wl -- weight matrix of shape (layer_dims[l], layer_dims[l-1]) bl -- bias vector of shape (layer_dims[l], 1) """ np.random.seed(3) parameters = {} L = len(layer_dims) # number of layers in the network for l in range(1, L): parameters['W' + str(l)] = np.random.randn(layer_dims[l], layer_dims[l - 1]) * 0.01 parameters['b' + str(l)] = np.zeros((layer_dims[l], 1)) assert(parameters['W' + str(l)].shape == (layer_dims[l], layer_dims[l - 1])) assert(parameters['b' + str(l)].shape == (layer_dims[l], 1)) return parameters
2.L层模型前向传播
1)线性前向传播公式:
def linear_forward(A, W, b): """ Implement the linear part of a layer's forward propagation. Arguments: A -- activations from previous layer (or input data): (size of previous layer, number of examples) W -- weights matrix: numpy array of shape (size of current layer, size of previous layer) b -- bias vector, numpy array of shape (size of the current layer, 1) Returns: Z -- the input of the activation function, also called pre-activation parameter cache -- a python dictionary containing "A", "W" and "b" ; stored for computing the backward pass efficiently """ Z = np.dot(W, A) + b assert(Z.shape == (W.shape[0], A.shape[1])) cache = (A, W, b) return Z, cache
2)激活函数前向传播
def linear_activation_forward(A_prev, W, b, activation): """ Implement the forward propagation for the LINEAR->ACTIVATION layer Arguments: A_prev -- activations from previous layer (or input data): (size of previous layer, number of examples) W -- weights matrix: numpy array of shape (size of current layer, size of previous layer) b -- bias vector, numpy array of shape (size of the current layer, 1) activation -- the activation to be used in this layer, stored as a text string: "sigmoid" or "relu" Returns: A -- the output of the activation function, also called the post-activation value cache -- a python dictionary containing "linear_cache" and "activation_cache"; stored for computing the backward pass efficiently """ if activation == "sigmoid": # Inputs: "A_prev, W, b". Outputs: "A, activation_cache". Z, linear_cache = linear_forward(A_prev, W, b) A, activation_cache = sigmoid(Z) elif activation == "relu": # Inputs: "A_prev, W, b". Outputs: "A, activation_cache". Z, linear_cache = linear_forward(A_prev, W, b) A, activation_cache = relu(Z) assert (A.shape == (W.shape[0], A_prev.shape[1])) cache = (linear_cache, activation_cache) return A, cache
3)L层模型前向传播:
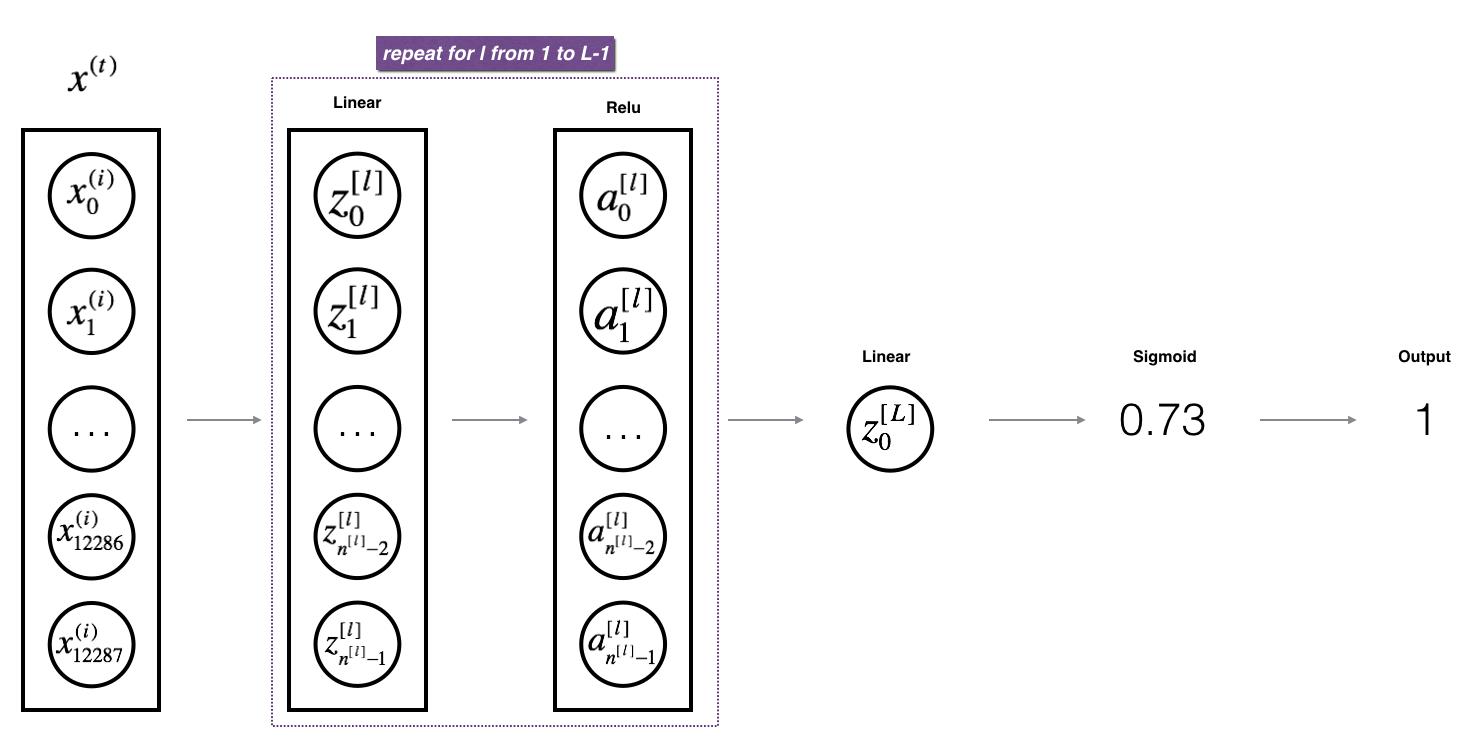
其中, ,实现过程:
def L_model_forward(X, parameters): """ Implement forward propagation for the [LINEAR->RELU]*(L-1)->LINEAR->SIGMOID computation Arguments: X -- data, numpy array of shape (input size, number of examples) parameters -- output of initialize_parameters_deep() Returns: AL -- last post-activation value caches -- list of caches containing: every cache of linear_relu_forward() (there are L-1 of them, indexed from 0 to L-2) the cache of linear_sigmoid_forward() (there is one, indexed L-1) """ caches = [] A = X L = len(parameters) // 2 # number of layers in the neural network # Implement [LINEAR -> RELU]*(L-1). Add "cache" to the "caches" list. for l in range(1, L): A_prev = A A, cache = linear_activation_forward(A_prev, parameters['W' + str(l)], parameters['b' + str(l)], activation='relu') caches.append(cache) # Implement LINEAR -> SIGMOID. Add "cache" to the "caches" list. AL, cache = linear_activation_forward(A, parameters['W' + str(L)], parameters['b' + str(L)], activation='sigmoid') caches.append(cache) assert(AL.shape == (1, X.shape[1])) return AL, caches
3.交叉熵损失函数
def compute_cost(AL, Y): """ Implement the cost function defined by equation (7). Arguments: AL -- probability vector corresponding to your label predictions, shape (1, number of examples) Y -- true "label" vector (for example: containing 0 if non-cat, 1 if cat), shape (1, number of examples) Returns: cost -- cross-entropy cost """ m = Y.shape[1] # Compute loss from aL and y. cost = (-1 / m) * np.sum(np.multiply(Y, np.log(AL)) + np.multiply(1 - Y, np.log(1 - AL))) cost = np.squeeze(cost) # To make sure your cost's shape is what we expect (e.g. this turns [[17]] into 17). assert(cost.shape == ()) return cost
4.L-层反向传导实现
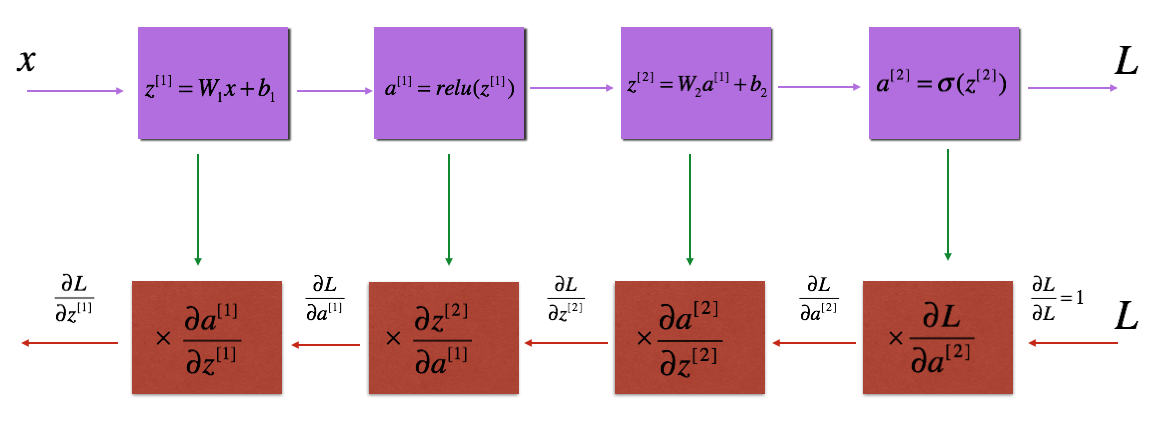
在 中,
中,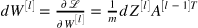 ;
; ;
1)线性反向传播:
def linear_backward(dZ, cache): """ Implement the linear portion of backward propagation for a single layer (layer l) Arguments: dZ -- Gradient of the cost with respect to the linear output (of current layer l) cache -- tuple of values (A_prev, W, b) coming from the forward propagation in the current layer Returns: dA_prev -- Gradient of the cost with respect to the activation (of the previous layer l-1), same shape as A_prev dW -- Gradient of the cost with respect to W (current layer l), same shape as W db -- Gradient of the cost with respect to b (current layer l), same shape as b """ A_prev, W, b = cache m = A_prev.shape[1] dW = np.dot(dZ, cache[0].T) / m db = np.squeeze(np.sum(dZ, axis=1, keepdims=True)) / m dA_prev = np.dot(cache[1].T, dZ) assert (dA_prev.shape == A_prev.shape) assert (dW.shape == W.shape) assert (isinstance(db, float)) return dA_prev, dW, db
2)激活函数反向传导:
def linear_activation_backward(dA, cache, activation): """ Implement the backward propagation for the LINEAR->ACTIVATION layer. Arguments: dA -- post-activation gradient for current layer l cache -- tuple of values (linear_cache, activation_cache) we store for computing backward propagation efficiently activation -- the activation to be used in this layer, stored as a text string: "sigmoid" or "relu" Returns: dA_prev -- Gradient of the cost with respect to the activation (of the previous layer l-1), same shape as A_prev dW -- Gradient of the cost with respect to W (current layer l), same shape as W db -- Gradient of the cost with respect to b (current layer l), same shape as b """ linear_cache, activation_cache = cache if activation == "relu": dZ = relu_backward(dA, activation_cache) elif activation == "sigmoid": dZ = sigmoid_backward(dA, activation_cache) # Shorten the code dA_prev, dW, db = linear_backward(dZ, linear_cache) return dA_prev, dW, db
3)L层模型反向传播:
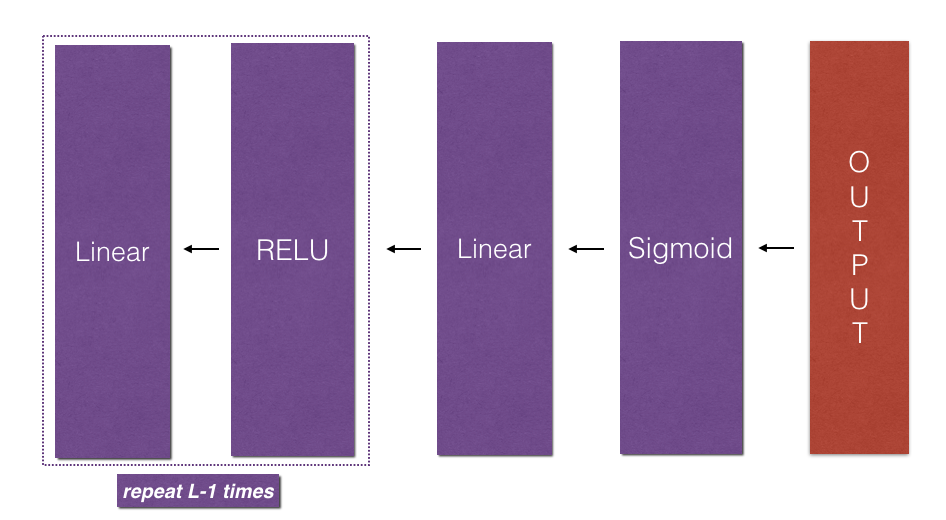
def L_model_backward(AL, Y, caches): """ Implement the backward propagation for the [LINEAR->RELU] * (L-1) -> LINEAR -> SIGMOID group Arguments: AL -- probability vector, output of the forward propagation (L_model_forward()) Y -- true "label" vector (containing 0 if non-cat, 1 if cat) caches -- list of caches containing: every cache of linear_activation_forward() with "relu" (it's caches[l], for l in range(L-1) i.e l = 0...L-2) the cache of linear_activation_forward() with "sigmoid" (it's caches[L-1]) Returns: grads -- A dictionary with the gradients grads["dA" + str(l)] = ... grads["dW" + str(l)] = ... grads["db" + str(l)] = ... """ grads = {} L = len(caches) # the number of layers m = AL.shape[1] Y = Y.reshape(AL.shape) # after this line, Y is the same shape as AL # Initializing the backpropagation dAL = dAL = - (np.divide(Y, AL) - np.divide(1 - Y, 1 - AL)) # Lth layer (SIGMOID -> LINEAR) gradients. Inputs: "AL, Y, caches". Outputs: "grads["dAL"], grads["dWL"], grads["dbL"] current_cache = caches[-1] grads["dA" + str(L)], grads["dW" + str(L)], grads["db" + str(L)] = linear_backward(sigmoid_backward(dAL,current_cache[1]), current_cache[0]) for l in reversed(range(L-1)): # lth layer: (RELU -> LINEAR) gradients. # Inputs: "grads["dA" + str(l + 2)], caches". Outputs: "grads["dA" + str(l + 1)] , grads["dW" + str(l + 1)] , grads["db" + str(l + 1)] current_cache = caches[l] dA_prev_temp, dW_temp, db_temp = linear_backward(sigmoid_backward(dAL, caches[1]), caches[0]) grads["dA" + str(l + 1)] = dA_prev_temp grads["dW" + str(l + 1)] = dW_temp grads["db" + str(l + 1)] = db_temp return grads
5.更新参数
def update_parameters(parameters, grads, learning_rate): """ Update parameters using gradient descent Arguments: parameters -- python dictionary containing your parameters grads -- python dictionary containing your gradients, output of L_model_backward Returns: parameters -- python dictionary containing your updated parameters parameters["W" + str(l)] = ... parameters["b" + str(l)] = ... """ L = len(parameters) // 2 # number of layers in the neural network # Update rule for each parameter. Use a for loop. for l in range(L): parameters["W" + str(l + 1)] = parameters["W" + str(l + 1)] - learning_rate * grads["dW" + str(l + 1)] parameters["b" + str(l + 1)] = parameters["b" + str(l + 1)] - learning_rate * grads["db" + str(l + 1)] return parameters

 浙公网安备 33010602011771号
浙公网安备 33010602011771号