
MapReduce 是一个并行计算框架。最初由Google提出来的,用于解决大规模数据(大于1T)的并行计算。
通俗来说:MpaReduce 是集合大规模的机器资源,对大数据进行并行计算的一种编程模型。
MapReduce 分为两个过程,Map(映射)和 Reduce(归纳)。这两个过程的思想来源于函数式编程和矢量编程语言。
Map(映射)过程对一批 key/value 数据进行处理,中间的处理过程由用户自定义,经过Map过程之后会生成一批新的key/value的数据。
例子1:
下面是一组数据:
001119910101+000
001119910102+001
001119910103+002
001119920101+003
001119920102-001
可以不用理会这串数据的实际意义,假设这串数据的解释是:
0011 占位符,无实际意义
9910101 年月日
+000 阴天
+001 多云
+002 晴朗
+003 万里无云
-001 小雨
合成一组Map:
(0,001119910101+000)
(1,001119910102+001).....
经过Map过程处理后:(假设这里的Map做的工作是 分解出某天的天气情况。)
处理后的新Map:
(19910101,000)
(19910102, 001)
...
(19920102,-001)
这个过程就是Map的过程。可以理解为对一批数据进行处理,生成一批我们想要的数据。
接下来就是reduce过程了。reduce过程是归纳,reduce的输入当然是map工程的输出。
输入:
(19910101,000)
(19910102, 001)
...
(19920102,-001)
经过reduce过程:(这里只是一个例子,实际过程对Map的输出会先聚合的在处理的。下面会用另外一个例子来说明。)
(0101,[000, 003])
(0102, [001, -001])
(0103, 002)
然后就可以利用这组数据画出历史上每年0101的天气变化图了。
例子2:
原数据:有1000万的网页文档,得到常用的3000个单词出现的次数。
假设分配 1W 台机器来处理map过程,那么就是每台机器处理 1k 个网页。100 台机器来处理reduce过程,每台reduce机器处理30个词。
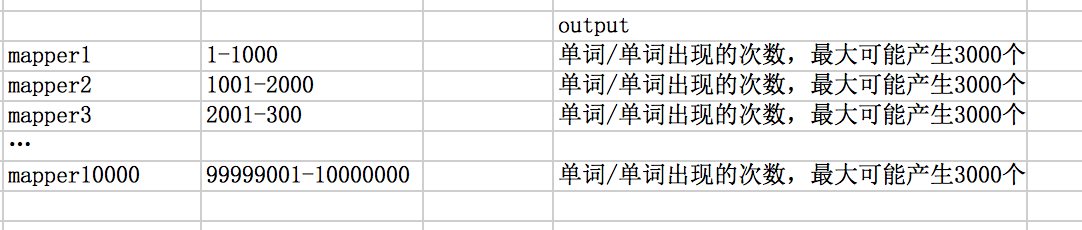
每台机器都会产生多个key/value, 1W 台机器会有互相重叠的 key/value。
然后在处理reduce的过程中,就会有一个隐形的集合过程,即把key相同的key/value发到同一台reduce上进行处理。
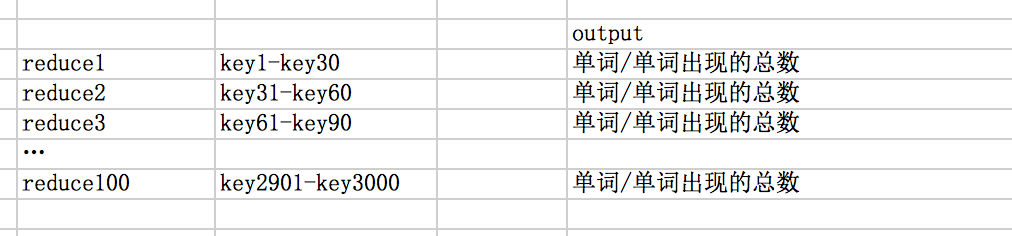
这就是MapReduce 处理 wordCount 的过程。
看了上面两个例子,我们再来看下MapReduce的处理过程图。图的最后会有一些解释。
图1:
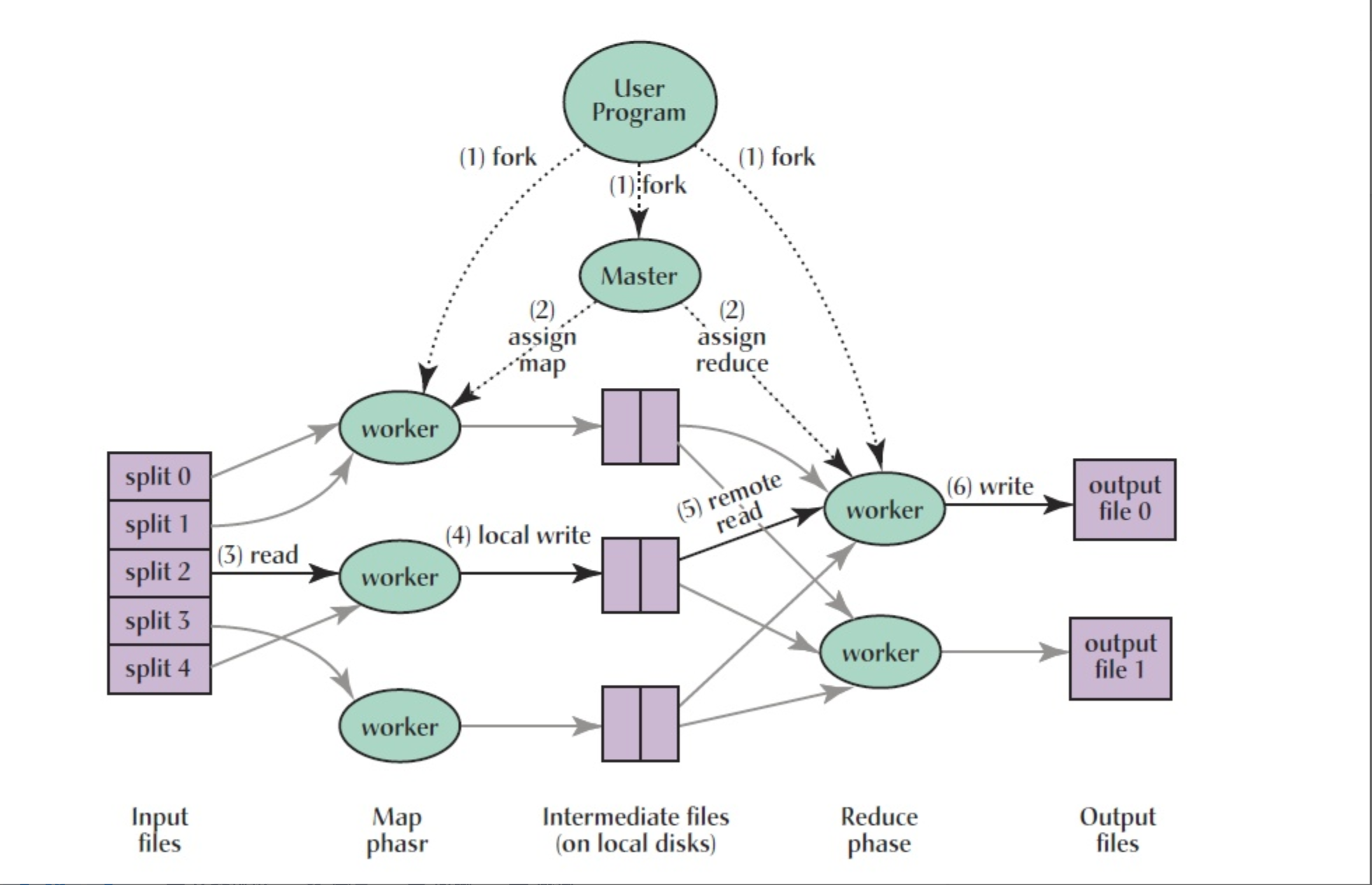
图2:
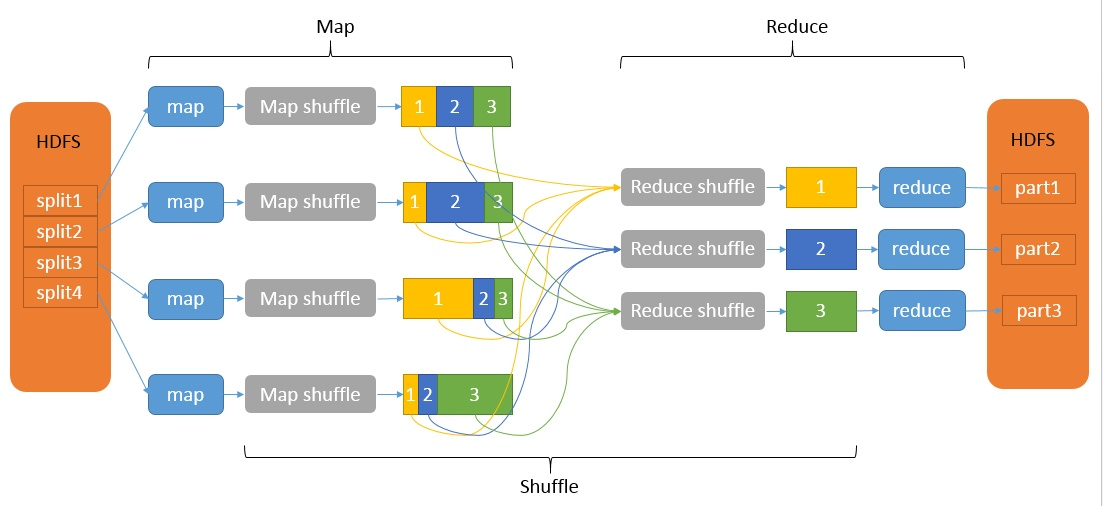
图3:
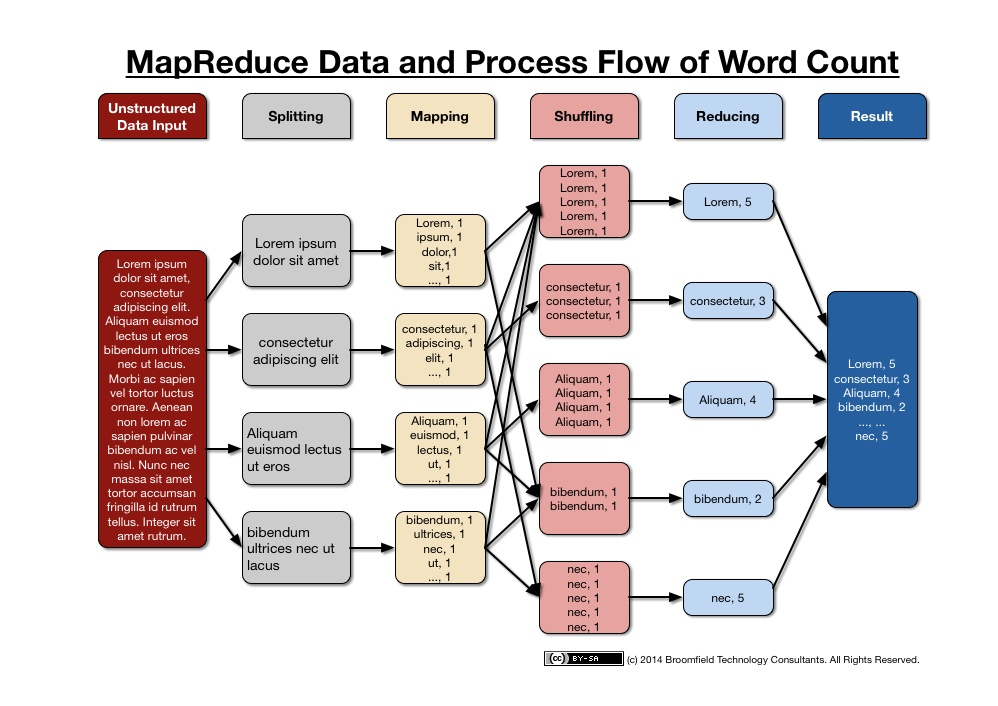
通过图可以看到,多了一个shuffle的调度过程。整个MapReduce的原理就是如上面所说,映射和归纳两个过程,中间的shuffle过程才是
最复杂的。需要考虑 任务时间、任务出错处理、网络通讯等。
参考文档:
https://zh.wikipedia.org/zh-hans/MapReduce
https://www.zhihu.com/question/23345991
https://zhuanlan.zhihu.com/p/35816725
https://blog.csdn.net/suifeng3051/article/details/41651851
https://mp.weixin.qq.com/s/1GZGyQzuN6RGFWu6JCfcyQ
https://wenku.baidu.com/view/1aa777fd04a1b0717fd5dd4a.html
https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/mapreduce-osdi04.pdf
http://hadoop.apache.org/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号