
(数据挖掘-入门-8)基于朴素贝叶斯的文本分类器
主要内容:
1、动机
2、基于朴素贝叶斯的文本分类器
3、python实现
一、动机
之前介绍的朴素贝叶斯分类器所使用的都是结构化的数据集,即每行代表一个样本,每列代表一个特征属性。
但在实际中,尤其是网页中,爬虫所采集到的数据都是非结构化的,如新闻、微博、帖子等,如果要对对这一类数据进行分类,应该怎么办呢?例如,新闻分类,微博情感分析等。
本文就介绍一种基于朴素贝叶斯的文本分类器。
二、基于朴素贝叶斯的文本分类器
目标:对非结构化的文本进行分类
首先,回顾一下朴素贝叶斯公式:

特征、特征处理:
对于结构化数据,公式中的D代表的是样本或一系列整理或抽象出来的特征或属性,
而在非结构化的数据中,只有文档和单词,文档对应样本,单词对应特征。
如果将单词作为特征,未免特征太多了,一篇文章有那么多单词,而且有些单词并不起什么作用,因此需要对特征即单词进行处理。
停用词:我们将一些常见的词,如the, a, I, is, that等,称为“停用词”,因为它们在很多文章都会出现,不具称为特征的代表性。
模型参数计算:
别忘了,朴素贝叶斯的假设前提:在已知类别下,所有特征是独立的。(在文本中,即不考虑单词之间的次序和相关性)
如何计算模型的参数,即已知类别时某文本的条件概率呢?(这里只是进行简单的统计而已,复杂一点的可以考虑TF-IDF作为单词特征,下面的公式已经做了平滑处理)
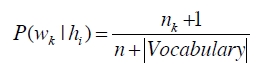
Wk:表示某个单词
hi: 表示某个类别
nk: 表示单词wk在类别hi中出现的次数
n:表示类别中的单词总数
vocabulary:表示类别中的单词数
分类:
来一篇新文章,如何判断它是属于哪一类呢?
如下公式,分别计算属于每一类的概率,然后取概率最大的作为其类别。
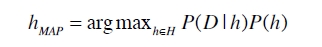
应用:
新闻分类、垃圾邮件分类、微博情感分析等等
三、python实现
数据集:
- zip file containing the 20 newsgroup corpus (22MB)
- The 20 Newsgroups data set website
- Review Polarity Dataset (divided into 10 buckets)
- The Movie Review Polarity Dataset Webpage
代码:
1、新闻分类


from __future__ import print_function import os, codecs, math class BayesText: def __init__(self, trainingdir, stopwordlist): """This class implements a naive Bayes approach to text classification trainingdir is the training data. Each subdirectory of trainingdir is titled with the name of the classification category -- those subdirectories in turn contain the text files for that category. The stopwordlist is a list of words (one per line) will be removed before any counting takes place. """ self.vocabulary = {} self.prob = {} self.totals = {} self.stopwords = {} f = open(stopwordlist) for line in f: self.stopwords[line.strip()] = 1 f.close() categories = os.listdir(trainingdir) #filter out files that are not directories self.categories = [filename for filename in categories if os.path.isdir(trainingdir + filename)] print("Counting ...") for category in self.categories: print(' ' + category) (self.prob[category], self.totals[category]) = self.train(trainingdir, category) # I am going to eliminate any word in the vocabulary # that doesn't occur at least 3 times toDelete = [] for word in self.vocabulary: if self.vocabulary[word] < 3: # mark word for deletion # can't delete now because you can't delete # from a list you are currently iterating over toDelete.append(word) # now delete for word in toDelete: del self.vocabulary[word] # now compute probabilities vocabLength = len(self.vocabulary) print("Computing probabilities:") for category in self.categories: print(' ' + category) denominator = self.totals[category] + vocabLength for word in self.vocabulary: if word in self.prob[category]: count = self.prob[category][word] else: count = 1 self.prob[category][word] = (float(count + 1) / denominator) print ("DONE TRAINING\n\n") def train(self, trainingdir, category): """counts word occurrences for a particular category""" currentdir = trainingdir + category files = os.listdir(currentdir) counts = {} total = 0 for file in files: #print(currentdir + '/' + file) f = codecs.open(currentdir + '/' + file, 'r', 'iso8859-1') for line in f: tokens = line.split() for token in tokens: # get rid of punctuation and lowercase token token = token.strip('\'".,?:-') token = token.lower() if token != '' and not token in self.stopwords: self.vocabulary.setdefault(token, 0) self.vocabulary[token] += 1 counts.setdefault(token, 0) counts[token] += 1 total += 1 f.close() return(counts, total) def classify(self, filename): results = {} for category in self.categories: results[category] = 0 f = codecs.open(filename, 'r', 'iso8859-1') for line in f: tokens = line.split() for token in tokens: #print(token) token = token.strip('\'".,?:-').lower() if token in self.vocabulary: for category in self.categories: if self.prob[category][token] == 0: print("%s %s" % (category, token)) results[category] += math.log( self.prob[category][token]) f.close() results = list(results.items()) results.sort(key=lambda tuple: tuple[1], reverse = True) # for debugging I can change this to give me the entire list return results[0][0] def testCategory(self, directory, category): files = os.listdir(directory) total = 0 correct = 0 for file in files: total += 1 result = self.classify(directory + file) if result == category: correct += 1 return (correct, total) def test(self, testdir): """Test all files in the test directory--that directory is organized into subdirectories--each subdir is a classification category""" categories = os.listdir(testdir) #filter out files that are not directories categories = [filename for filename in categories if os.path.isdir(testdir + filename)] correct = 0 total = 0 for category in categories: print(".", end="") (catCorrect, catTotal) = self.testCategory( testdir + category + '/', category) correct += catCorrect total += catTotal print("\n\nAccuracy is %f%% (%i test instances)" % ((float(correct) / total) * 100, total)) # change these to match your directory structure baseDirectory = "20news-bydate/" trainingDir = baseDirectory + "20news-bydate-train/" testDir = baseDirectory + "20news-bydate-test/" stoplistfile = "20news-bydate/stopwords0.txt" print("Reg stoplist 0 ") bT = BayesText(trainingDir, baseDirectory + "stopwords0.txt") print("Running Test ...") bT.test(testDir) print("\n\nReg stoplist 25 ") bT = BayesText(trainingDir, baseDirectory + "stopwords25.txt") print("Running Test ...") bT.test(testDir) print("\n\nReg stoplist 174 ") bT = BayesText(trainingDir, baseDirectory + "stopwords174.txt") print("Running Test ...") bT.test(testDir)
2、情感分析
from __future__ import print_function import os, codecs, math class BayesText: def __init__(self, trainingdir, stopwordlist, ignoreBucket): """This class implements a naive Bayes approach to text classification trainingdir is the training data. Each subdirectory of trainingdir is titled with the name of the classification category -- those subdirectories in turn contain the text files for that category. The stopwordlist is a list of words (one per line) will be removed before any counting takes place. """ self.vocabulary = {} self.prob = {} self.totals = {} self.stopwords = {} f = open(stopwordlist) for line in f: self.stopwords[line.strip()] = 1 f.close() categories = os.listdir(trainingdir) #filter out files that are not directories self.categories = [filename for filename in categories if os.path.isdir(trainingdir + filename)] print("Counting ...") for category in self.categories: #print(' ' + category) (self.prob[category], self.totals[category]) = self.train(trainingdir, category, ignoreBucket) # I am going to eliminate any word in the vocabulary # that doesn't occur at least 3 times toDelete = [] for word in self.vocabulary: if self.vocabulary[word] < 3: # mark word for deletion # can't delete now because you can't delete # from a list you are currently iterating over toDelete.append(word) # now delete for word in toDelete: del self.vocabulary[word] # now compute probabilities vocabLength = len(self.vocabulary) #print("Computing probabilities:") for category in self.categories: #print(' ' + category) denominator = self.totals[category] + vocabLength for word in self.vocabulary: if word in self.prob[category]: count = self.prob[category][word] else: count = 1 self.prob[category][word] = (float(count + 1) / denominator) #print ("DONE TRAINING\n\n") def train(self, trainingdir, category, bucketNumberToIgnore): """counts word occurrences for a particular category""" ignore = "%i" % bucketNumberToIgnore currentdir = trainingdir + category directories = os.listdir(currentdir) counts = {} total = 0 for directory in directories: if directory != ignore: currentBucket = trainingdir + category + "/" + directory files = os.listdir(currentBucket) #print(" " + currentBucket) for file in files: f = codecs.open(currentBucket + '/' + file, 'r', 'iso8859-1') for line in f: tokens = line.split() for token in tokens: # get rid of punctuation and lowercase token token = token.strip('\'".,?:-') token = token.lower() if token != '' and not token in self.stopwords: self.vocabulary.setdefault(token, 0) self.vocabulary[token] += 1 counts.setdefault(token, 0) counts[token] += 1 total += 1 f.close() return(counts, total) def classify(self, filename): results = {} for category in self.categories: results[category] = 0 f = codecs.open(filename, 'r', 'iso8859-1') for line in f: tokens = line.split() for token in tokens: #print(token) token = token.strip('\'".,?:-').lower() if token in self.vocabulary: for category in self.categories: if self.prob[category][token] == 0: print("%s %s" % (category, token)) results[category] += math.log( self.prob[category][token]) f.close() results = list(results.items()) results.sort(key=lambda tuple: tuple[1], reverse = True) # for debugging I can change this to give me the entire list return results[0][0] def testCategory(self, direc, category, bucketNumber): results = {} directory = direc + ("%i/" % bucketNumber) #print("Testing " + directory) files = os.listdir(directory) total = 0 correct = 0 for file in files: total += 1 result = self.classify(directory + file) results.setdefault(result, 0) results[result] += 1 #if result == category: # correct += 1 return results def test(self, testdir, bucketNumber): """Test all files in the test directory--that directory is organized into subdirectories--each subdir is a classification category""" results = {} categories = os.listdir(testdir) #filter out files that are not directories categories = [filename for filename in categories if os.path.isdir(testdir + filename)] correct = 0 total = 0 for category in categories: #print(".", end="") results[category] = self.testCategory( testdir + category + '/', category, bucketNumber) return results def tenfold(dataPrefix, stoplist): results = {} for i in range(0,10): bT = BayesText(dataPrefix, stoplist, i) r = bT.test(theDir, i) for (key, value) in r.items(): results.setdefault(key, {}) for (ckey, cvalue) in value.items(): results[key].setdefault(ckey, 0) results[key][ckey] += cvalue categories = list(results.keys()) categories.sort() print( "\n Classified as: ") header = " " subheader = " +" for category in categories: header += "% 2s " % category subheader += "-----+" print (header) print (subheader) total = 0.0 correct = 0.0 for category in categories: row = " %s |" % category for c2 in categories: if c2 in results[category]: count = results[category][c2] else: count = 0 row += " %3i |" % count total += count if c2 == category: correct += count print(row) print(subheader) print("\n%5.3f percent correct" %((correct * 100) / total)) print("total of %i instances" % total) # change these to match your directory structure prefixPath = "reviewPolarityBuckets/review_polarity_buckets/" theDir = prefixPath + "/txt_sentoken/" stoplistfile = prefixPath + "stopwords25.txt" tenfold(theDir, stoplistfile)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号