
python3 进程
1.开进程的两种方式:
1. 使用内置的进程
#!/usr/bin/env python
#coding:utf-8
#Created by Andy @ 2017/9/17
from multiprocessing import Process
import os
def get_id(name):
print(name,"Main process:",os.getppid(),"current process;", os.getpid())
P1 = Process(target=get_id, args=('andy',))
P2 = Process(target = get_id, args=("Jack", ))
if __name__ == "__main__":
P2.start()
P1.start()
print("主进程")
2. 自定义进程类:
from multiprocessing import Process
import os
class Custom_Process(Process):
def __init__(self, name):
super().__init__()
self.name = name
def run(self):
print(self.name, "Main process:", os.getppid(), "current process;", os.getpid())
if __name__ == "__main__":
P1 = Custom_Process('andy')
P2 = Custom_Process("jack")
P1.start()
P2.start()
print("主进程")
事实上在调用P1.start时,系统调用了Process类的run方法,在我们直接调用Process类时,
我们需要指定target(即要进行的操作,参数args),那么定制后我们重写了run方法,即重写的
run方法。
在Custom_Process类中我用到了
super().__init__()
这是重写父类的方法之一,另一种方法是:
Parent.__init__(self)
在这里就是:Process.__init__()
关于super().__init__()事实上并不是调用父类,而是寻找继承顺序中的下一个
具体可以参考:Python’s super() considered super!
下面是一个应用进程的例子,之前在写 cs模型 时有:
server.listen(5)# 设置可以接受的连接数量
虽然这里可以接受5个链接,但事实上由于功能上并未实现
所以每次只有一个链接可以正常进行通信,其他的链接都必须
等到之前的链接完成才行。
下面着手改进:
server
#!/usr/bin/env python
#coding:utf-8
#Created by Andy @ 2017/9/16
import socket,json, struct, subprocess
from multiprocessing import Process
BUFF_SIZE = 1024
IP_PORT = ("127.0.0.1", 8081)
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR,1)# 重用端口
server.bind(IP_PORT)
server.listen(5)# 设置可以接受的连接数量
def communicate(conn, client_addr):
while True:# 内层循环为通信循环
msg = conn.recv(BUFF_SIZE)
if not msg:
break
pipes = subprocess.Popen(msg.decode("utf-8"),
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE
)
error = pipes.stderr.read()
if error:
print("Error:",error)
response_msg = error
else:
response_msg = pipes.stdout.read()
header = {'data_size':len(response_msg)}# 数据长度
header_json = json.dumps(header)#序列化
header_json_byte = bytes(header_json,encoding="utf-8")
conn.send(struct.pack('i',len(header_json_byte)))
#先发送报头长度,仅包含数据长度, 这里的i指int类型
conn.send(header_json_byte)# 再发送报头
conn.sendall(response_msg)# 正式的信息
print("Request from:",client_addr, "Command:",msg)
conn.close()
if __name__ == "__main__":
while True:# 外层循环为链接循环
conn, client_addr = server.accept()
p = Process(target=communicate, args=(conn, client_addr))
p.start()
server.close()
client未变:
#!/usr/bin/env python
#coding:utf-8
#Created by Andy @ 2017/9/16
import socket, json, struct
BUFF_SIZE = 1024
IP_PORT = ("127.0.0.1", 8081)
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect(IP_PORT)
while True:
msg = input(">>:").strip().encode("utf-8")
if not msg:
break
client.send(msg)
header = client.recv(4)
print("Header:",struct.unpack("i", header))
header_length = struct.unpack('i', header)[0]
print("Header_length:", header_length)
header_json = json.loads(client.recv(header_length).decode("utf-8"))
data_size = header_json['data_size']
print("Data_size:",data_size)
recv_size = 0
recv_data = b''
while recv_size < data_size:
recv_data += client.recv(BUFF_SIZE)
recv_size += len(recv_data)
print(recv_data.decode("gbk"))
client.close()
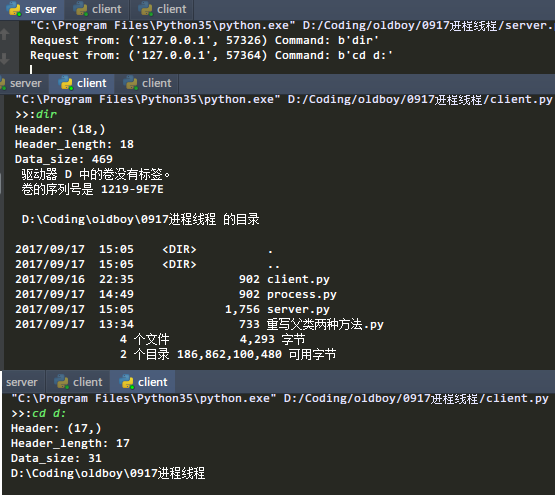
看下运行结果,这里只开了两个客户端,5个同样的道理:
2.LOCK 互斥锁:
import os, time
from multiprocessing import Process, Lock
def work(mutex):
mutex.acquire()
print("%d is working..." % os.getpid())
time.sleep(2)
print("%d is done!" % os.getpid())
mutex.release()
if __name__ == "__main__":
mutex = Lock()
p1 = Process(target=work, args=(mutex,))
p2 = Process(target=work, args=(mutex,))
p1.start()
p2.start()
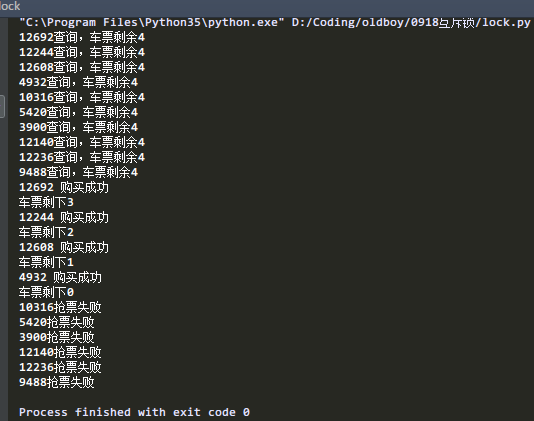
模拟 抢票系统:所有人都可以查看到还剩下多票,但是只有部分人能抢到票。
import json, random, time, os
from multiprocessing import Process , Lock
def search():
dic = json.load(open('db.txt',))
print("%s查询,车票剩余%s" % (os.getpid(),dic['count']))
def get_ticket():
dic = json.load(open('db.txt',))
if dic['count'] > 0:
dic['count'] -= 1
time.sleep(random.randint(1,4))
json.dump(dic,open('db.txt', 'w'))
print('%s 购买成功' % os.getpid())
print("车票剩下%s" % dic["count"])
else:
print("%s抢票失败 " % os.getpid())
def task(mutex):
search()
mutex.acquire()
get_ticket()
mutex.release()
if __name__ == "__main__":
mutex = Lock()
for i in range(10):
p = Process(target=task, args=(mutex,))
p.start()
3.Join
1.join方法的作用是阻塞主进程(挡住,无法执行join以后的语句),专注执行多线程。
2.多线程多join的情况下,依次执行各线程的join方法,前头一个结束了才能执行后面一个。
3.无参数,则等待到该线程结束,才开始执行下一个线程的join。
4.设置参数后,则等待该线程这么长时间就不管它了(而该线程并没有结束)。不管的意思就是可以执行后面的主进程了。
看例子:
#!/usr/bin/env python
#coding:utf-8
#Created by Andy @ 2017/9/19
import os, time
from multiprocessing import Process, Lock
def work(mutex, t):
mutex.acquire()
print("%s Running at %s\n" % (os.getpid(),time.strftime("%H:%M:%S")))
time.sleep(t)
mutex.release()
print("%s Stop at %s\n" % (os.getpid(),time.strftime("%H:%M:%S")))
if __name__ == "__main__":
print("Main Process Running at %s\n" % time.strftime("%H:%M:%S"))
mutex = Lock()
p1 = Process(target=work, args=(mutex,5))
p2 = Process(target=work, args=(mutex,3))
p1.start()
p2.start()
p1.join()
print("Join1 finish at %s!\n" % time.strftime("%H:%M:%S"))
p2.join()
print("Join2 finish at %s!\n" % time.strftime("%H:%M:%S"))
print("Main Process Stop at %s\n" % time.strftime("%H:%M:%S"))
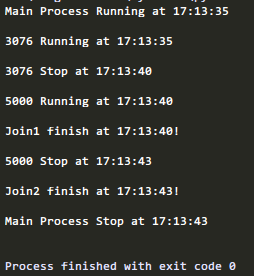
此时没有指定join的时长,所以,第一个进程执行完了,第一个join也相应的结束了,
然后第二个进程执行完了,第二个join也结束了。
当指定时间后分两种情况,当join的时间比进程需要执行的时间短时,它就不再等待该进行,直接执行
将join()修改为p2.join(2)
将p2.join()修改为p2.join(2)
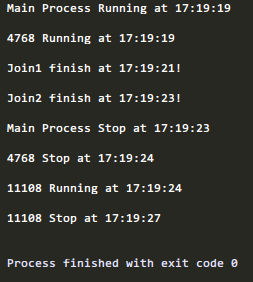
可以看到,进程4768还未执行完时,join1等待2秒后直接不管它了,执行了后面的打印语句
接着执行了join2,等待2秒后,主进程自己结束了自己(这里应该是打印语句的原因,事实上并未直接的结束)
此时4768仍在运行,直到自己结束。然后才是进程11108
如果我将时间设置得比它需要的时间还长呢,那么它应该在进程运行完时也结束
将P1.join()修改为p1.join(6)
将p2.join()修改为p2.join(4)
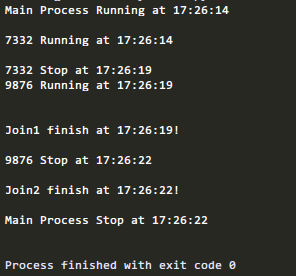
可以看到Join1,join2都是在两个进行结束后自己结束了,并没有等待设定的时间长度。
4.Daemon 守护进程
守护进程的作用:
一:守护进程会在主进程代码执行结束后就终止
二:守护进程内无法再开启子进程,否则抛出异常:AssertionError: daemonic processes are not allowed to have children
下面看例子:
#!/usr/bin/env python
#coding:utf-8
#Created by Andy @ 2017/9/19
from multiprocessing import Process
import time
def work():
print("Running...")
time.sleep(3)
print("Finish!")
if __name__ == "__main__":
p = Process(target=work,)
#p.daemon = True
p.start()
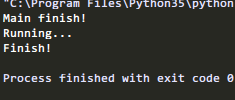
print("Main finish!")
运行结果:
将#p.daemon=True注释掉,再运行:
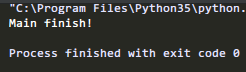
可以看到,主进程结束了,子进程也结束了, 并不会等待它运行完。
守护进程为什么在主进程结束后就结束了呢?
首先,我们要明白守护进程的作用:守护主进程的一些功能,当主进程执行完了,
也就是说它的功能已经全部执行完了,那么,守护进程也就没有继续守护下去的
必要了,所以一旦主进程结束了,守护进程也就结束了。
5.Semaphore 信号量
Semaphore制对共享资源的访问数量,比如可以同时运行的子进程数量:
#!/usr/bin/env python
#coding:utf-8
#Created by Andy @ 2017/9/19
import multiprocessing
import time
def worker(s):
s.acquire()
print(multiprocessing.current_process().name + "acquire");
time.sleep(2)
print(multiprocessing.current_process().name + "release\n");
s.release()
if __name__ == "__main__":
s = multiprocessing.Semaphore(2)
for i in range(5):
p = multiprocessing.Process(target = worker, args=(s,))
p.start()
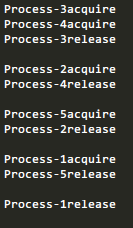
如上, 只有释放一个进程才有新的进程进来
将信号量改成大于等于进程数:
s = multiprocessing.Semaphore(5)

可以看到,所有进程一下全部启动了。
进程间通信有一个人种方式,一种是队列,一种是管道
6.队列
下面演示在一个进程中往队列中传入数据,用另一个进程取出来:
#!/usr/bin/env python
#coding:utf-8
#Created by Andy @ 2017/9/19
import random,os
from multiprocessing import Queue,Process
def put_q(q):
print("Put...")
for i in range(5):
n = random.randint(1,5)
print(n)
q.put(n)
def get_q(q):
print("\nGet...")
while True:
if not q.empty():
print("%s" % os.getpid(),q.get())
else:
break
if __name__ == "__main__":
q = Queue(8)
p1 = Process(target=put_q,args=(q,))
p2 = Process(target=get_q,args=(q,))
p1.start()
p1.join() # 防止进程2先启动,队列为空
p2.start()
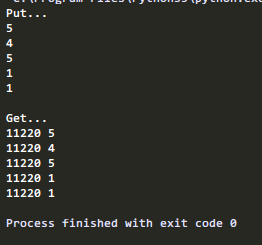
这样就实现了进程间的通信
7.管道
#!/usr/bin/env python
#coding:utf-8
#Created by Andy @ 2017/9/19
import random,os
from multiprocessing import Pipe,Process
def send_p(p):
print("send...")
for i in range(5):
n = random.randint(1,5)
print(n)
p.send(n)
def receive_p(p):
print("\nReceive...")
while True:
print("%s" % os.getpid(),p.recv())
if __name__ == "__main__":
p = Pipe()
p1 = Process(target=send_p,args=(p[0],))
p2 = Process(target=receive_p,args=(p[1],))
p1.start()
p1.join()
p2.start()
运行:
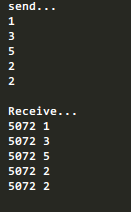
8.Pool 进程池
Pool可以提供指定数量的进程,供用户调用,当有新的请求提交到pool中时,
如果池还没有满,那么就会创建一个新的进程用来执行该请求;
但如果池中的进程数已经达到规定最大值,那么该请求就会等待,
直到池中有进程结束,才会创建新的进程来它。
看例子:
#!/usr/bin/env python
#coding:utf-8
#Created by Andy @ 2017/9/20
import time
from multiprocessing import Pool, Process
def work(msg):
print(msg, 'is working\n')
time.sleep(2)
print(msg,'finish!\n')
if __name__ == "__main__":
pro = Process()
pool = Pool(processes=3)
for i in range(1,6):
msg = "process %s" % i
pool.apply_async(work,(msg,))
pool.close()
pool.join()# 阻塞主进程,等待子进程执行完
运行:
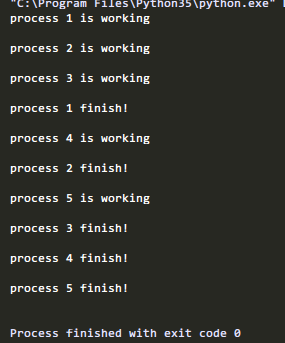
指定进程池只有3个进程,所以第四个进程只有前面结束一个进程时才能开始。
需要说明的是 pool.apply_async()是非阻塞的,pool.apply()则是阻塞的。看区别:
修改:
pool.apply(work,(msg,))
再次运行:
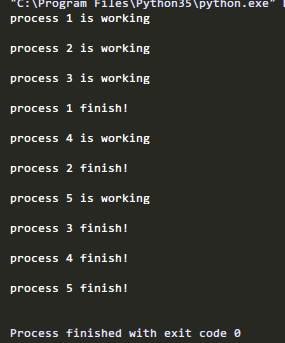
可以看到,子进程只能结束一个后都会运行下一个进程
回调函数:
回调函数指:进程池中任何一个任务一旦处理完了,就立即告知主进程:
我好了额,你可以处理我的结果了。主进程则调用一个函数去处理该结果。
对上面的例子进行修改:
#!/usr/bin/env python
#coding:utf-8
#Created by Andy @ 2017/9/20
import time, os
from multiprocessing import Pool, Process
def work(msg):
print(msg, 'is working\n')
time.sleep(2)
print(msg,'finish!\n')
return msg
def plus(msg):
if msg:
msg = msg + '*plus*'
print(msg)
if __name__ == "__main__":
pro = Process()
pool = Pool(processes=3)
for i in range(1,6):
msg = "process %s" % i
pool.apply_async(work,(msg,), callback=plus)# 回调函数
pool.close()
pool.join()
运行:

可以看到一个进程结果后,在开启一个新的进程到进程池后,
主进程又调用一个回调函数对该进程的结果进行了二次处理。
补充:
对于计算机来说,也并不能无限开启进程,通常比较好的情况是
进程数等于计算机核数是比较好的,否则开多了可能会起到反作用
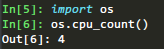
那么要怎么查看自己的计算机是几核的呢?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号