浅析支持向量机(SVM)
brief introduction
information
支持向量机(Support Vector Machine,以下简称SVM),是一个二元分类( dualistic classification)的广义线性分类器(generalized linear classifier),通过寻找分离超平面作为决策边界(decision boundary),分离少量的支持向量(support vector),从而达到分类目的\([1][2][3]\)。
可采用一对一(One Versus One)、一对多(One Versus Rest)等策略转变为多分类问题\([6]\)。
原问题(primal problem)仅支持硬间隔最大化(hard margin maximum),添加松弛变量(slack variable)后支持软间隔最大化(soft margin maximum)。
details
属性:稀疏性和稳健性(Robust)\([1]\)、非参数模型(nonparametric models)、监督学习(supervised learning)、判别模型(discriminant model)、【KKT条件(Karush-Kuhn-Tucker condition)约束,对偶形式(dual form)转换,序列最小优化(Sequential Minimal Optimization,以下简称为SMO)算法求解\([1][4][5]\)】、支持核方法(kernel method)。
求解:使用门页损失函数(hinge loss function)计算经验风险(empirical risk)并在求解时加入了正则化项以优化结构风险(structural risk),1.直接进行二次规划(Quadratic Programming)求解;2.利用拉格朗日算子( Lagrange multipliers),将其转为,符合KKT条件(Karush-Kuhn-Tucker condition)的对偶形式(dual form),再进行二次规划(Quadratic Programming)求解\([1]\)。
扩展:利用正则化、概率学、结构化、核方法改进算法,包括偏斜数据、概率SVM、最小二乘SVM(Least Square SVM, LS-SVM)、结构化SVM(structured SVM)、多核SVM(multiple kernel SVM);也可扩充到回归(Support Vector Regression)、聚类、半监督学习(Semi-Supervised SVM, S3VM)。
problems
- generalized formula:
- 间隔距离(support vector distance):最优解时,值等于\(\frac{2}{\| w \|}\);
- 分割线-原点垂直距离: 最优解时,值等于\(\frac{b}{\| w \|}\);
- 简单推导:
-
\[\color{black}{s\,v\,distance\,:} \begin{aligned} &\begin{cases} W^{\rm{T}}x_i^++b=1\\ W^{\rm{T}}x_i+b=0\\ W^{\rm{T}}x_i^-+b=-1\\ \end{cases} \\ &\downarrow \\ &\begin{cases} W^{\rm{T}}(x_i-x_j)= 0 &\rightarrow W\bot (x_i-x_j)\\ W\| (x^+-x^-) &\rightarrow x^+=x^-+\lambda W\\ W^{\rm{T}}x^++b=1 &\rightarrow \lambda W^{\rm{T}}W=2, \,|\lambda| =\frac{2}{|W^{\rm{T}}W|}\\ \end{cases} \\ &\downarrow \\ &maximize\;\|x^+-x^-\| \\ &\rightarrow \|x^+-x^-\| = \|\lambda W\|=\frac{2}{\|W\|} \end{aligned}\]
-
primal problem
当样本数据集线性可分(linear separable)时,寻找正负样本中各自距离对方最近的样本数据(称为支持向量,即SVM的名字由来)(一般为三个),利用相对位置(排除坐标缩放影响,也是采用几何间隔的原因),构建最大间隔(几何间隔)进行分类[3]。
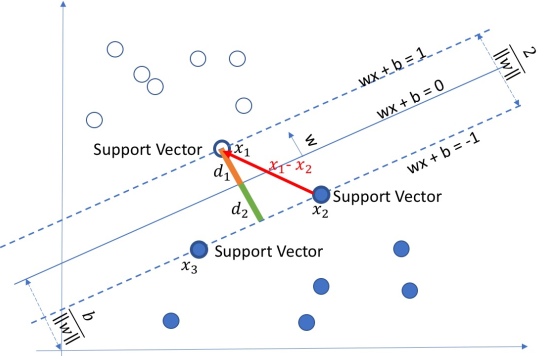
\[from:greedyai.com \]
如图,当硬间隔最大化时,正类支持向量(positive support vector)(图中\(x_1\))与负类支持向量(negative support vector)(图中\(x_2, x_3\))使
- 约束条件:\(y_i(W^{\top}x_i+b)\geq 1\)
- 经验风险函数(Hinge loss):\([1-y_i(W^{\top}x_i+b)]_+\)
- 目标函数:\(min_{(w,b)}\,\frac{1}{2}\|W\|^2\)
- 预测:\(h(x)=sign(W^{\top}x+b)\)
\(sign\)表示符号函数,即计算括号内的值,值为正数则取正类别,反之亦然。
(求解推导请查看下方dual problem内容)
multi-class
- 多元分类(类似于LR多标签分类的策略)(\(C_k^2>k,\;when\;k>3\))
- OVR(one versus rest):k元分类问题,训练\(k\)个模型,每个模型二分类为某个类和非该类,预测时选择\(max_i\,w_i^{\rm{T}}x\;\)为\(x\)的类别
- OVO(one versus one):k元分类问题,训练\(C_k^2\)个模型,每个模型二分类为k元中二元组合,预测时选择计票次数最多的\(i\)为\(x\)的类别
slack problem
硬间隔最大化无法满足实际条件中,异常值间隔、线性不可分等情况,因此引入软间隔(soft margin)方式: 在原问题基础上,添加松弛变量(slack variable),增加容错率。
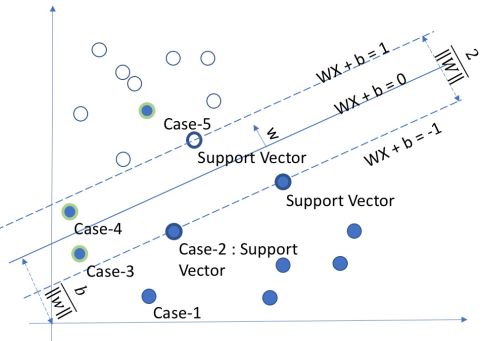
\[from:greedyai.com \]
- 约束条件:\(\begin{aligned} &y_i(W^{\rm{T}}x_i+b)\geq 1\color{red}{-\xi_i} \end{aligned}\)
- 经验风险函数(Hinge loss):\[\begin{aligned} y_i(W^{\rm{T}}x+b)\geq 1-{\color{red}{\xi_i}} \rightarrow &\begin{cases} {\color{red}{\xi_i}}\geq 1-y_i(W^{\rm{T}}x+b) \\ {\color{red}{\xi_i}}\geq 0 \end{cases}\\ &\downarrow \\ {\color{red}{\xi_i}}=&[1-y_i(W^{\rm{T}}x+b)]_+ \end{aligned}\]
- 目标函数:\(min_{(w,b,\color{red}{\xi\geq 0})}\,\frac{1}{2}\|W\|^2+\color{red}{C\sum_{i}\xi_i} \\\)
- 预测:\(h(x)=sign(W^{\top}X+b)\)
(求解推导请查看下方dual problem内容)
Duality
- 原问题转为对偶形式再求解的好处:\([9]\)
- 把约束条件和待优化目标融合在一个表达式,便于求解;
- 对偶问题一般是凹函数,便于求全局最优解(global optimal);
- 对偶形式,便于引入核技巧;
KKT condition
-
成立条件:
- \(f(W)=W^{\rm{T}}W\) is convex,
- \(\begin{cases}g_i(W)\\h_i(W)=\alpha_i^{\rm{T}}W+b\end{cases}\) is affine,
- \(\exists W,\,\forall_i g_i(W)<0\),
-
内容(具体问题中有不同表现形式):
\[\begin{cases} \frac{\partial }{\partial w_i}L(w^\star,\alpha^\star,\beta^\star)=0 & i=1,\dots,d \\ \frac{\partial }{\partial \beta_i}L(w^\star,\alpha^\star,\beta^\star)=0 & i=1,\dots,l \\ {\color{red}{\alpha^\star g_i(w^\star)=0}}& i=1,\dots,k\\ g_i(w^\star)\leq 0 & i=1,\dots,k \\ \alpha^\star \geq 0 & i=1,\dots,k \\ \end{cases} \rightarrow \alpha^\star>0, g_i(w^\star)=0 \]
留意\(\alpha^\star>0, g_i(w^\star)=0\),即非支持向量的样本令\(g_i(w^\star)\neq 0\),可得\(\alpha^\star=0\);
dual form normal processing
-
原优化问题:
\[\begin{align} &min_w\;f(w) \\ s.t. &g_i(w)\leq 0 \\ &h_i(w)=0 \end{align} \] -
拉格朗日函数(添加\(\alpha,\beta\)算子):
\[\begin{align} &{\cal{L}(w,\alpha,\beta)}= f(w)+ \sum_{i=1}^k\alpha_ig_i(w)+ \sum_{i=1}^l\beta_ih_i(w) \end{align} \]- 约束情况:\[\begin{align} \theta_{\cal{p}}(w) &= max_{\alpha,\beta:\alpha_i\geq0} {\cal{L}}(w,\alpha,\beta) \\ &= \begin{cases} f(w)&约束被满足\\ \infty&约束未满足 \end{cases} \end{align} \]
- 约束情况:
dual form transformation
primal to dual
(from greedyai.com)
- 已知: 原问题数学模型
-
改造:符合对偶形式一般流程(dual form normal processing)
\[\begin{align} g_i(w)= -y_i(W^{\top}x_i+b)+1 \leq 0 \end{align} \] -
转换:拉格朗日函数
\[\begin{align} {\cal{L}(w,\alpha,\beta)} &= f(w) + \sum_{i=1}^k\alpha_ig_i(w)+ \sum_{i=1}^l\beta_ih_i(w) \\ &=\frac{1}{2}\|W\|^2- \sum_{i=1}^n\alpha_i[y_i(W^{\top}x_i+b)-1] \end{align} \] -
去除:未知值\(w,b\)求解
\[\begin{align} \]
&=\nabla_w\large[\frac{1}{2}|W|^2-
\sum_{i=1}n\alpha_i[y_i(Wx_i+b)-1]\large] \
&=w-\sum_{i=1}^n\alpha_iy_ix_i
{\color{red}{\rightarrow0}} \
\rightarrow w
&=\sum_{i=1}^n\alpha_iy_ix_i
\tag{3.1} \
\nabla_b{\cal{L}(w,b,\alpha,\beta)}
&=\nabla_b\large[\frac{1}{2}|W|^2-
\sum_{i=1}n\alpha_i[y_i(Wx_i+b)-1]\large] \
&=\sum_{i=1}^n\alpha_iy_i
{\color{red}{\rightarrow0}}
\tag{3.2} \
\end{align}
\begin{align}
{\cal{L}(w,b,\alpha,\beta)}
&=
\frac{1}{2}[\sum_{i=1}n\alpha_iy_ix_i]2-
\sum_{i=1}n\alpha_i[y_i(\sum_{i=1}n\alpha_jy_jx_ix_j+b)-1] \
&=
\frac{1}{2}\sum_{i=1}^n\alpha_i\alpha_jy_iy_jx_ix_j-
\sum_{i,j=1}n\alpha_i\alpha_jy_iy_jx_ix_j-b\sum_{i=1}n\alpha_iy_i+
\sum_{i=1}^n\alpha_i \
&=
-\frac{1}{2}\sum_{i=1}^n\alpha_i\alpha_jy_iy_jx_ix_j-
0+
\sum_{i=1}^n\alpha_i \
&=
\sum_{i=1}n\alpha_i-\frac{1}{2}\sum_{i=1}n\alpha_i\alpha_jy_iy_jx_ix_j
\tag{3.3}
\end{align}
\begin{align}
max_\alpha;W(\alpha)
&=
\sum_{i=1}n\alpha_i-\frac{1}{2}\sum_{i=1}n\alpha_i\alpha_jy_iy_jx_ix_j \
s.t.;
&\alpha_i\geq 0 \
&\sum_{i=1}^n\alpha_iy_i=0
\end{align}
\begin{align}
b=-\frac{1}{2}
(max_{i:y_i=-1}W^\top x_i+min_{i:y=1}W^\top x_i)
\end{align}
\begin{align}
f(w)
&=
W^\top x+b \
&=(\sum_{i=1}^n\alpha_iy_ix_i)x-
\frac{1}{2}
(max_{i:y_i=-1}W^\top x_i+min_{i:y=1}W^\top x_i) \
\end{align}
\begin{cases}
&\alpha_i&=&0 &\Rightarrow
&y_i(W^{\rm{T}}x+b) &\geq 1 \
&\alpha_i&>&0 &\Rightarrow
&y_i(W^{\rm{T}}x+b)&= 1 \
\end{cases}
\begin{align}
&min_{(w,b,\color{red}{\xi\geq 0})},\frac{1}{2}|W|^2+\color{red}{C\sum_{i}\xi_i} \
s.t.
&y_i(W^{\rm{T}}x_i+b)\geq 1\color{red}{-\xi_i}
\end{align}
\begin{align}
g_i(w)=
-y_i(W^{\top}x_i+b)+1{\color{red}{-\xi_i}}
\leq 0
\end{align}
\begin{align}
{\cal{L}(w,\alpha,\beta)}
&=
f(w) +
\sum_{i=1}^k\alpha_ig_i(w)+
\sum_{i=1}^l\beta_ih_i(w) \
&=\frac{1}{2}|W|^2+{\color{red}{C\sum_{i}\xi_i}}-
\sum_{i=1}n\alpha_i[y_i(Wx_i+b)-1{\color{red}{+\xi_i}}]
\end{align}
\begin{align}
\nabla_w{\cal{L}(w,b,\xi,\alpha,\beta)}
&=w-\sum_{i=1}^n\alpha_iy_ix_i
{\color{red}{\rightarrow0}} \
\rightarrow w
&=\sum_{i=1}^n\alpha_iy_ix_i
\tag{3.4} \
\nabla_b{\cal{L}(w,b,\xi,\alpha,\beta)}
&=\sum_{i=1}^n\alpha_iy_i
{\color{red}{\rightarrow0}}
\tag{3.5} \
\nabla_\xi{\cal{L}(w,b,\xi,\alpha,\beta)}
&=\nabla_\xi\large[\frac{1}{2}|W|^2+\color{red}{C\sum_{i}\xi_i}\
&\qquad -\sum_{i=1}n\alpha_i[y_i(Wx_i+b)-1+{\color{red}{\xi_i}}]\
&\qquad -\sum_i \lambda_i{\color{red}{\xi_i}}\large] \
&=0+\sum_iC-\sum_{i=1}^n\alpha_i-\sum_i\lambda_i
{\color{red}{\rightarrow0}} \
\rightarrow C&=\alpha_i+\lambda_i
\tag{3.6}
\end{align}
\begin{align}
{\cal{L}(w,b,\xi,\alpha,\beta)}
&=
\large[\frac{1}{2}|W|^2+\color{red}{C\sum_{i}\xi_i}\
&\qquad -\sum_{i=1}n\alpha_i[y_i(Wx_i+b)-1+{\color{red}{\xi_i}}]\
&\qquad -\sum_i \lambda_i{\color{red}{\xi_i}}\large] \
&=
\frac{1}{2}\sum_{i=1}^n\alpha_i\alpha_jy_iy_jx_ix_j+(\alpha_i+\lambda_i)\sum_i{\color{red}{\xi_i}}\
&\qquad -\sum_{i,j=1}n\alpha_i\alpha_jy_iy_jx_ix_j-b\sum_{i=1}n\alpha_iy_i+
\sum_{i=1}^n\alpha_i (1-{\color{red}{\xi_i}})\
&\qquad -\sum_i\lambda_i\color{red}{\xi_i}\
&=
-\frac{1}{2}\sum_{i=1}^n\alpha_i\alpha_jy_iy_jx_ix_j-
0+
\sum_{i=1}^n\alpha_i +
0\sum_i\color{red}{\xi_i}\
&=
\sum_{i=1}n\alpha_i-\frac{1}{2}\sum_{i=1}n\alpha_i\alpha_jy_iy_jx_ix_j
\tag{3.7}
\end{align}
\begin{align}
max_{\alpha};W(\alpha)
&=
\sum_{i=1}n\alpha_i-\frac{1}{2}\sum_{i=1}n\alpha_i\alpha_jy_iy_jx_ix_j \
s.t.;
&\alpha_i\geq 0\
&\sum_{i=1}^n\alpha_iy_i=0 \
&{\color{red}{\alpha_i\leq C}}
\end{align}
\begin{cases}&\alpha_i&=&0 &\Rightarrow &y_i(W^{\rm{T}}x+b) &\geq 1 \&\alpha_i&=&C &\Rightarrow &y_i(W^{\rm{T}}x+b)&\leq 1 \0&<&\alpha_i&<C&\Rightarrow &y_i(W^{\rm{T}}x+b)&= 1 \\end{cases}
\begin{align}
max_{\alpha};W(\alpha)
&=
\sum_{i=1}n\alpha_i-\frac{1}{2}\sum_{i=1}n\alpha_i\alpha_j
{\color{blue}{y_iy_j}}{\color{green}{x_ix_j}} \
s.t.;
&\alpha_i\geq 0\
&\sum_{i=1}^n{\color{orange}{\alpha_iy_i}}=0 \
&C\geq \alpha_i
\end{align}
\begin{align}
max &\begin{cases}
-{\color{blue}{y_iy_j}}:;
两样本标签同类,值减少 & 阻碍max
\
-{\color{green}{x_ix_j}}:;
两样本数据相似,值减少 & 阻碍max
\
-{\color{blue}{y_iy_j}}{\color{green}{x_ix_j}}:;
两样本内在逻辑类似,值减少 & 阻碍max
\
\end{cases}\
\sum_{i=1}^n &\begin{cases}
{\color{orange}{\alpha_iy_i}}:;
不同类标签各自加和,绝对值相等
\
\end{cases}\
\end{align}
|x_nk-x_0k|\leq \varepsilon
\begin{align}
&k={\cal{K}}(i,i)+{\cal{K}}(j,j)-2{\cal{K}}(i,j) ;
,s.t.,k>0
\end{align}
\begin{align}
&\alpha_j^{new}=
\begin{cases}
U & min\
\alpha_j^{old}+\frac{y(E_j-E_i)}{k} & \alpha \
V & max \
\end{cases} \
&\alpha_i{new}=\alpha_i+y_iy_j(\alpha_j{old}-\alpha_j)\
s.t.&;U\leq \alpha_j\leq V \
&\
define&;\begin{cases}
E_m=\sum_{l=1}^n[\alpha_jy_lK(l,m)]+b-y_m \
U=
\begin{cases}
max(0,\alpha_j{old}-\alpha_i) &y_i\neq y_j\
max(0,\alpha_j{old}+\alpha_i-C) &y_i= y_j\
\end{cases}\
V=
\begin{cases}
min(0,\alpha_j{old}-\alpha_i)+C &y_i\neq y_j\
min(C,\alpha_j{old}+\alpha_i) &y_i= y_j\
\end{cases}\
\end{cases} \
\end{align}
\begin{align}
b=&(b_x+b_y)/2,;;init;0\
b_x&=b-E_{\color{blue}{i}}\
&\qquad-y_i(\alpha_i{new}-\alpha_i){\cal{K}}(i,{\color{blue}{i}})\
&\qquad-y_i(\alpha_j{new}-\alpha_j){\cal{K}}({\color{blue}{i}},j),;;0<\alpha_{\color{blue}{i}}^{new}<C\
b_y&=b-E_{\color{green}{j}}\
&\qquad-y_i(\alpha_i{new}-\alpha_i){\cal{K}}(i,{\color{green}{j}})\
&\qquad-y_i(\alpha_j{new}-\alpha_j){\cal{K}}({\color{green}{j}},j),;;0<\alpha_{\color{green}{j}}^{new}<C\\
\end{align}
\begin{align}
&{\cal{K}}(x_i,x_j)=
({\large<}x_i,x_j{\large>}+c)^d \\
\end{align}
$$
-
Gaussian Kernel(need:feature standardization)
\[\begin{align} &{\cal{K}}(x_i,x_j)= \exp(-\frac{\|x_i-x_j\|_2^2}{2\sigma^2}) \\ &\qquad\begin{cases} lower\;bias&low\;\sigma^2\\ lower\;variance&high\;\sigma^2\\ \end{cases} \end{align} \] -
Sigmoid Kernel(equal:NN without hidden layer)
\[\begin{align} &{\cal{K}}(x_i,x_j)= \tanh(\alpha{\large<}x_i,x_j{\large>}+c) \\ \end{align} \] -
Cosine Similarity Kernel(used:text similarity)
\[\begin{align} &{\cal{K}}(x_i,x_j)= \frac{{\large<}x_i,x_j{\large>}} {\|x_i\|\|x_j\|} \\ \end{align} \] -
Chi-squared Kernel
\[\begin{align} SVM:\;&{\cal{K}}(x_i,x_j)= 1-\sum_{i=1}^n{\frac{(x_i-y_i)^2}{0.5(x_i+y_i)}}\\ rest:\;&{\cal{K}}(x_i,x_j)= \sum_{i=1}^n{\frac{2x_iy_i}{x_i+y_i}} \\ \end{align} \] -
Kerel condition
\[\begin{align} gram\;&G_{i,j} \begin{cases} symmetric \\ pos-difi\\ \end{cases}\\ define: &G_{i,j}={\cal{K}}(x_i. x_j)\\ \end{align} \]
kernel svm
-
直观模型
\[\begin{align} &{\color{gray}{max_{\alpha}\;W(\alpha)= \sum_{i=1}^n\alpha_i-\frac{1}{2}\sum_{i=1}^n\alpha_i\alpha_jy_iy_j}}{\color{red}{x_ix_j}} \\ &{\color{black}{max_{\alpha}\;W(\alpha)= \sum_{i=1}^n\alpha_i-\frac{1}{2}\sum_{i=1}^n\alpha_i\alpha_jy_iy_j}}{\color{blue}{\cal{K}(x_i,x_j)}} \\ &s.t.\; 0\leq \alpha_i\leq C,\;\sum_{i=1}^n\alpha_iy_i=0 \\ &define:\; {\cal{K}(x_i,x_j)}= \large<\varPhi(x_i),\varPhi(x_j)\large>\\ \end{align} \] -
kernel trick
-
关于正定核\({\cal{K}_i}\)的函数可以转为关于另一个正定核\({\cal{K}_j}\)的函数
-
预测:
\[\begin{align} {\color{gray}{h(x)}} &{\color{gray}{=sign(W^{\top}X+b)}} \\ h(x) &=sign(W^\top\varPhi(X)+b) \\ &=sign(\sum_i\alpha_iy_i{\cal{K}}(x_i,x)+b) \end{align} \] -
高维映射(核空间定义可参看B站-3Blue1Brown-微积分的本质)
\[\begin{align} polynomial\;kernel&(c=0,d=2):\\ &{\cal{K}}(x_i,x_j)= ({\large<}x_i,x_j{\large>}+0)^2\\ &\qquad\qquad={\large<}\varPhi(x_i),\varPhi(x_j){\large>}\\ &\begin{cases} \varPhi(x_i)=[x_{i1}^2,x_{i2}^2,\sqrt{2}x_{i1}x_{i2}] \\ \varPhi(x_j)= [x_{j1}^2,x_{j2}^2,\sqrt{2}x_{j1}x_{j2}] \\ \end{cases}\\ \end{align} \]
-
-
kernel & basis expansion(compared)
-
Oxford-Basis Expansion, Regularization, Validation, SNU-Basis expansions and Kernel methods,
-
类似:使用创建多项式方法创建新特征,都可用于线性分类(线性核),都能升维
-
不同:feature map不同(\(\varPhi(x)\)),存在非线性核
-
模型:
\[\begin{align} linear\;model: &y=w{\cdot}\varPhi(x)+\epsilon\\ basis: &\begin{cases} \varPhi(x)=[1,x_1,x_2,x_1x_2,x_1^2,x_2^2], D^dfeatures \\ define:\;D\,dimension,\;d\,polynomials\\ \end{cases}\\ kernel: &\begin{cases} \varPhi(x)={\cal{K}}(x_1,x_2) ={\large<}x_1,x_2{\large>},\;2\;features\\ \varPhi(x)=[1,{\cal{K}}(\mu_i,x)],\mu\,is\,centre, \;i\,features\\ \end{cases}\\ \end{align} \]
-
#.reference links
重点推荐\([5][6][10]\):
- [1].百度百科,支持向量机;
- [2].简书,作者:刘敬,支持向量机(SVM) 浅析;
- [3].CSDN,作者:于建民,浅析支持向量机SVM;
- [4].百度文库,未知作者,SVM算法学习(PPT);
- [5].CSDN,作者:zouxy09,机器学习算法与Python实践之(四)支持向量机(SVM)实现;
- [6].CSDN,作者:zouxy09,机器学习算法与Python实践之(三)支持向量机(SVM)进阶;
- [7].CSDN,作者:勿在浮砂筑高台,【机器学习详解】SMO算法剖析;
- [8].CSDN,作者:qll125596718,SVM学习(五):松弛变量与惩罚因子;
- [9].CSDN,作者:Dominic_S,手撕SVM公式——硬间隔、软间隔、核技巧;
- [10].私人网站,作者:pluskid,支持向量机: Support Vector 2;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号