skip list
跳表是个概率性数据结构,可以被看作是二叉树的一个变种。跳表是由William Pugh在1990年发明的。它是一种用户维护有序元素的数据结构。
一个跳表,应该具有以下特征:
1.一个跳表应该有几个层(level)组成;
2.跳表的第一层包含所有的元素;
3.每一层都是一个有序的链表;
4.如果元素x出现在第i层,则所有比i小的层都包含x;
5.第i层的元素通过一个down指针指向下一层拥有相同值的元素;
6.在每一层中,-1和1两个元素都出现(分别表示INT_MIN和INT_MAX);
7.Top指针指向最高层的第一个元素。
跳表的构造过程是:
1、给定一个有序的链表。
2、选择连表中最大和最小的元素,然后从其他元素中按照一定算法随即选出一些元素,将这些元素组成有序链表。这个新的链表称为一层,原链表称为其下一层。
3、为刚选出的每个元素添加一个指针域,这个指针指向下一层中值同自己相等的元素。Top指针指向该层首元素
4、重复2、3步,直到不再能选择出除最大最小元素以外的元素。
复杂度:
1.The expected number of levels is O( log n )
(here n is the numer of elements)
2.The expected time for insert/delete/find is O( log n )
3.The expected size (number of cells) is O(n )
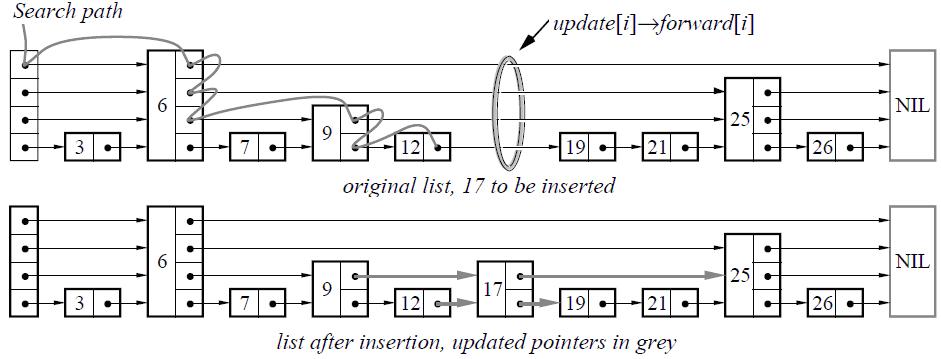
关于时空效率的证明:
1. 空间复杂度 O(n):
对于每层的期待:第一层n,第二层n/2,第三层n/22,...,直到 n/2log n=1。所以,总空间需求:
S = n + n/2 + n/22 + ... + n/2log n < n(1 + 1/2 + 1/22 + ... + 1/2∞) =2n
因此他的空间复杂度为 2n = O(n)
2. Skip List高度:
对每层来说,它会向上增长的概率为1/2,则第m层向上增长的概率为1/2m;n个元素,则在m层元素数目的期待为Em = n/2m;当Em = 1,m = log2n即为层数的期待。故其高度期待为 Eh = O(log n)。
*关于“高概率(high probability)”的定义:
(参考【3】【4】)
对于事件A,如果它发生的概率至少为1-cα/nα,其中cα仅取决于α,那么我们称它为高概率。
在牺牲时间和/或空间的情况下,我们可以选择α的值。
3. 查找的复杂度:
claim:在高概率的前提下,查找的时间复杂度为O(log n)
4. 插入的复杂度:
claim:在高概率的前提下,插入的时间复杂度为O(log n)
首先通过查找找到要插入的位置:O(log n)
之后进行插入,同时对每层进行对应的更新(依照概率决定是否向上增长):o(log n)
5. 删除的复杂度:
claim:在高概率的前提下,删除的时间复杂度为O(log n)
参考资料:
http://www.kernelchina.org/algorithm/SL.ppt
http://epaperpress.com/sortsearch/skl.html
http://www.spongeliu.com/63.html
http://www.cnblogs.com/flyfy1/archive/2011/02/24/1963347.html
http://courses.csail.mit.edu/6.046/spring04/handouts/skiplists.pdf


/** * 跳表是个概率性数据结构,可以被看作是二叉树的一个变种。跳表是由William Pugh在1990年发明的。它是一种用户维护有序元素的数据结构。 一个跳表,应该具有以下特征: 1.一个跳表应该有几个层(level)组成; 2.跳表的第一层包含所有的元素; 3.每一层都是一个有序的链表; 4.如果元素x出现在第i层,则所有比i小的层都包含x; 5.第i层的元素通过一个down指针指向下一层拥有相同值的元素; 6.在每一层中,-1和1两个元素都出现(分别表示INT_MIN和INT_MAX); 7.Top指针指向最高层的第一个元素。 跳表的构造过程是: 1、给定一个有序的链表。 2、选择连表中最大和最小的元素,然后从其他元素中按照一定算法随即选出一些元素,将这些元素组成有序链表。这个新的链表称为一层,原链表称为其下一层。 3、为刚选出的每个元素添加一个指针域,这个指针指向下一层中值同自己相等的元素。Top指针指向该层首元素 4、重复2、3步,直到不再能选择出除最大最小元素以外的元素。 复杂度: 1.The expected number of levels is O( log n ) (here n is the numer of elements) 2.The expected time for insert/delete/find is O( log n ) 3.The expected size (number of cells) is O(n ) 关于时空效率的证明: 1. 空间复杂度 O(n): 对于每层的期待:第一层n,第二层n/2,第三层n/22,...,直到 n/2log n=1。所以,总空间需求: S = n + n/2 + n/22 + ... + n/2log n < n(1 + 1/2 + 1/22 + ... + 1/2∞) =2n 因此他的空间复杂度为 2n = O(n) 2. Skip List高度: 对每层来说,它会向上增长的概率为1/2,则第m层向上增长的概率为1/2m;n个元素,则在m层元素数目的期待为Em = n/2m;当Em = 1,m = log2n即为层数的期待。故其高度期待为 Eh = O(log n)。 *关于“高概率(high probability)”的定义: (参考【3】【4】) 对于事件A,如果它发生的概率至少为1-cα/nα,其中cα仅取决于α,那么我们称它为高概率。 在牺牲时间和/或空间的情况下,我们可以选择α的值。 3. 查找的复杂度: claim:在高概率的前提下,查找的时间复杂度为O(log n) 4. 插入的复杂度: claim:在高概率的前提下,插入的时间复杂度为O(log n) 首先通过查找找到要插入的位置:O(log n) 之后进行插入,同时对每层进行对应的更新(依照概率决定是否向上增长):o(log n) 5. 删除的复杂度: claim:在高概率的前提下,删除的时间复杂度为O(log n) 参考资料: http://www.kernelchina.org/algorithm/SL.ppt http://epaperpress.com/sortsearch/skl.html http://www.spongeliu.com/63.html http://www.cnblogs.com/flyfy1/archive/2011/02/24/1963347.html http://courses.csail.mit.edu/6.046/spring04/handouts/skiplists.pdf */ #include <stdio.h> #include <stdlib.h> #define MAX_LEVEL 10 //the max level /** * node */ typedef struct nodeStructure { int key; int value; struct nodeStructure *forward[MAX_LEVEL]; int name; } nodeStructure; /** * skip list */ typedef struct skiplist { int level; nodeStructure *header; } skiplist; /** * create node */ nodeStructure* createNode(int level,int key,int value) { nodeStructure *ns = (nodeStructure *) malloc(sizeof(nodeStructure)); for(int i = 0; i < level;i++) { ns->forward[i] = NULL; } ns->key = key; ns->value = value; ns->name = key; return ns; } /** * initate skiplist */ skiplist* createSkiplist() { skiplist *sl = (skiplist *) malloc(sizeof(skiplist)); sl->level = 0; sl->header = createNode(MAX_LEVEL - 1,0,0); for(int i = 0; i < MAX_LEVEL; i ++){ sl->header->forward[i] = NULL; } return sl; } /** * just like throw coins */ int randomLevel() { int k = 1; while(rand()%2) { k++; } k = (k < MAX_LEVEL) ? k : MAX_LEVEL; return k; } bool insert(skiplist *sl, int key, int value) { nodeStructure *update[MAX_LEVEL]; nodeStructure *p,*q; p = sl->header; int k = sl->level; //Search from top level to low for(int i = k - 1 ; i >= 0; i -- ) { while((q = p->forward[i]) && (q->key < key)) { p = q; } update[i] = p; //若新的key所存在第i层,则当前节点的第i个forword会指向新节点 } if(q && q->key == key) { return false; } //创建新的节点 int new_level = randomLevel(); if( new_level > sl->level) { for(int i = sl->level; i < new_level; i++){ update[i] = sl->header; //header的第level--k 层的下一节点都将指向新节点 } sl->level = new_level; } q = createNode(new_level,key,value); for(int i = 0; i < new_level; i ++) { q->forward[i] = update[i]->forward[i]; update[i]->forward[i] = q; //printf("%d\n",update[i]->forward[i]->value); } return true; } nodeStructure* search(skiplist *sl, int key) { nodeStructure *p,*q = NULL; p = sl->header; int level = sl->level; for( int i = level - 1; i >= 0; i--){ while((q=p->forward[i]) && (q -> key < key)) { p = q; } if(q && q->key == key) { return q; } } return NULL; } bool deleteSL(skiplist *sl, int key){ nodeStructure *p,*q = NULL; nodeStructure *update[MAX_LEVEL]; int level = sl->level; p = sl->header; for(int i = level - 1; i >= 0; i --){ while((q = p->forward[i]) && q->key < key) { p = q; } update[i] = p; } if(q && q->key == key) { //从最下面一层开始更新 for(int i = 0; i < sl->level ;i ++) { if(update[i]->forward[i] == q) { update[i]->forward[i] = q->forward[i]; //printf("update[%d]->name:%d\n",i,update[i]->name); } else { //个人觉得当不等时,i既是q的level数,不需要再往下遍历 break; } } free(q); //如果被删的是最高level的节点,需维护新跳表 for( int i = sl->level - 1; i >= 0; i --) { if(sl->header->forward[i] == NULL) { sl->level --; } } return true; } return false; } /** * 从最高层开始打印 */ void printSL(skiplist *sl) { nodeStructure *p,*q = NULL; int level = sl->level; for(int i = level - 1; i >= 0; i--) { p = sl->header; while((q=p->forward[i])) { printf("%d(%d) -> ",q->key,q->value); p=q; } printf("\n"); } printf("\n"); } int main() { skiplist *sl = createSkiplist(); for(int i = 1; i <= 19; i++) { insert(sl,i,i*2); } printSL(sl); //search nodeStructure* i = search(sl,4); printf("key=>%d,value=>%d\n",i->key,i->value); bool b = deleteSL(sl,4); if(b) { printf("Delete success\n"); } printSL(sl); return 0; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号