做题记录1
2021
1月
1月11日
P3592 [POI2015]MYJ(区间 dp)
区间\(dp\)+离散化
不是很懂\(dp\)转移方程
P4362 [NOI2002] 贪吃的九头龙(树形 dp)
树形\(dp\),设状态\(dp[x][k][0/1]\)表示当前结点\(x\)已经用了\(k\)种颜色,且\(x\)结点 没有/有 被染成\(1\)号颜色的最小代价
转移方程:
\(Trick:\)
\(1.\)注意到如果除了\(1\)号颜色有两种以上颜色,那么我们一定可以有一种方案使得贡献尽可能小(即两个相邻点一定不同色)
所以当我们根节点颜色不确定时,我们就可以通过置换一下减少贡献
\(2.\)但是当一共只有两种情况的时候,我们发现当结点\(x\)和\(y\)都不是\(1\)号色的话,那就只能都是\(2\)号色,所以要加贡献
\(3.\)注意无解就是结点数还不够染色的时候
P3554 [POI2013]LUK-Triumphal arch(树形 dp ,二分)
容易发现答案\(k\)具有单调性,\(k\)越大越容易满足答案正确,\(k\)越小越有可能错误
那么我们考虑二分答案\(k\),问题转化为判断一次染\(k\)个点是否可行
\(tip1:\)容易发现,\(B\)不会走回头路,因为如果走了在回去不就相当于白送\(A\)一次染色机会
考虑\(dp\)来检验:
设状态\(dp[x]\)表示\(x\)所以子树内(不包括\(x\))需要多少次"额外"的染色
\(tip2:\)"额外"的定义:因为我们走到子树中本身每一步都是在轮次中的,此时\(A\)也可以染色,这里指的是本身可以给予的染色机会不够了,必须"借用"其它地方的染色机会的点的个数
转移方程:
其中\(d[x]\)是指\(x\)的子树个数,\(mid\)是二分出来的那个答案\(k\)
那么\(dp\)完了过后,如果\(dp[1]==0\),那么此时这个\(mid\)就是可行解,我们可以寻找更小的答案\((r=mid)\),否则我们只能往更劣处找\((l=mid)\)
\(tip3:\)此时\(dp[1]==0\)的含义:整个树当中没有需要"额外"步数的结点,而\(1\)号结点作为根节点,不可能接受到其它地方的"帮助",所以必须要求这个点不能有额外的贡献
1月12日
CF1163F Indecisive Taxi Fee(最短路,线段树)
最短路+线段树
分四种情况讨论,主要困难点在于当前修改的边在最短路上且被改大了的情况
把题意转化成不经过某一条边的最短路
然后对于每一条不在最短路上的边,都可以更新一下其不经过最短路上中间一些边的\(l\)和\(r\)
\(Trick1:\)我们可以把经过某个点的最短路按这种方式统计\((s,u)(u,t)\),就是拼接起来
\(Trick2:\)我们也可以必须经过某一条边,即\((s,u)(u,v)(v,t)\)或者\((s,v)(v,u)(u,t)\),因为不确定是怎么拼的,是先拼\(u\),还是\(v\)?所以要讨论两种情况,取\(min\)
然后每一条非最短路上的边都可以这样搞一下,就求出了这样做可以在不经过最短路上,一个连续边集的情况下走的最短路(就是取\(min\))
这就相当于区间覆盖,就是线段树然后区间取\(min\)即可
P6381 『MdOI R2』Odyssey(分解质因数,DP,哈希/map)
首先手模一下可以发现这个 $$ab=c^k$$有点性质:
对于\(a\)和\(b\)分解质因数得到:
\(a=p_1^{x_1}*p_2^{x_2}...*p_n^{x_n}\)
\(b=p_1^{y_1}*p_2^{y_2}...*p_n^{y_n}\)
然后\(a,b\)一定满足:
\(x_1+y_1 \equiv 0 \mod k\)
\(x_2+y_2 \equiv 0 \mod k\)
\(...\)
\(x_n+y_n \equiv 0 \mod k\)
即对于任意的$i \in [1,n] ,\exists x_i+y_i \equiv 0 \mod k $且\(0 \leq x_i,y_i \leq k*r\),其中\(r\)是某个上界
于是此时我们可以对所有的边的权值都分解质因数,然后用新的来代替(即对所有指数模\(k\)),然后可以得到新的权
接下来可以发现满足上述条件的一组两个数都是唯一的,换句话说,就是假设我们现在数为\(p\),那么存在且只有一个数\(q\)和\(p\)一起构成”完美数对“(至于为什么,显而易见,因为\(\exists x_i+y_i \equiv 0 \mod k\))
那么接下来我们分层图然后\(dp\)就行了
设\(f_{x,p}\)为到达点\(x\),且上一条边的边权为\(p\)的最长路径长度,设\(p\)在上面的意义下映射为\(map[p]\)
那么转移就是\(f_{y,q}=max(f_{y,q},f_{x,p}*(map[p]==q))\)
然后我们发现这个值域太大了,空间开不下...再想到一个数分解质因数过后的质因子个数又不多,所以我们就可以使用\(map\)或者哈希乱搞就行了
1月20日
P3567[POI2014]KUR-Couriers(可持久化值域线段树)
容易发现其实我们可以查询每次对于一个值域区间\([l,r]\),存在某个数的出现次数大于\(len\)即可
那么就考虑主席树,每次询问就是\(root[r]\) ~ \(root[l-1]\)之间的某个数的个数
而且容易发现对于一个值域区间\([l,r]\),如果其本身数的个数小于\(len\),那么\([l,mid]\)和\([mid+1,r]\)同样也一定小于\(len\),所以不行
于是我们此处把区间询问转化成主席树的类似前缀和的差,把比较转化为线段树维护值域的个数
这个值域不用离散化,于是就做完了
P2839 [国家集训队]middle(可持久化线段树,二分)
询问多段区间中位数,求\(max\),强制在线
\(Trick1:\)看到区间中位数,要想到二分答案,直接二分中位数的值
\(Trick2:\)二分\(mid\)过后,发现可以把\(<mid\)的数看成\(-1\),\(\geq mid\)的数看成\(1\),记区间和为\(sum\),此时当\(sum=0\)时代表中位数就是这个数\(mid\),\(sum<0\)代表中位数比\(mid\)小,\(sum>0\)代表中位数比\(mid\)大
在这里,我们很容易发现,区间\([b+1,c-1]\)必定是要选择的
而\([a,b]\)和\([c,d]\)是我们可以考虑选择的
从刚刚的结论可以看出,我们要中位数更大,那么对于我们当前找到的\(mid\),肯定是区间和\(sum\)越大越好,因为这就代表我们\(mid\)可以变得更大(只要\(sum>0\),\(mid\)可以更大,\(sum<0\),\(mid\)要更小,\(sum=0\),中位数就是\(mid\))
而这里我们考虑在必选区间\([b+1,c-1]\)的基础上继续在\([a,b]\)和\([c,d]\)中选,由于我们是要\(sum\)尽可能大,那么我们就可以直接把\(sum\)加上区间\([a,b]\)的最大后缀和 和\([c,d]\)的最大前缀和即可
于是此时我们可以考虑暴力:每次二分中位数,暴力查询区间和,区间最大前缀和,区间最大后缀和,如果这三者之和\(>0\),则存在更大的中位数,\(l=mid+1\)(二分边界\(l\)),\(<0\)则是\(r=mid-1\),\(=0\)则中位数就是\(mid\)
然后唯一的问题就是怎么快速查询了
首先我们可以发现刚刚的三个值都是可以用线段树维护的(详见线段树维护最大子段和等)
但是问题就在于,这样干我们对于每一个\(mid\),都要把整个数组和\(mid\)比大小后改成\(1\)或\(-1\)再进行查询,也就是对于每一个数都要重新开一个线段树,空间无法承受
\(Trick3:\)可以发现,当我们前后的值分别为\(x\)和\(x+1\)的话(即我们二分的数从\(mid\)变成\(mid+1\)),数组上会有改变的只有\(=x\)的那些数,所以我们可以发现对于某一个数\(+1\)或者\(-1\)的改变,只有确定有限个位置的值会被改变,而且这样的改变随着\(x\)逐渐变大,不会有撤回的情况(也就是若\(x\)单调上升,我们绝对不会把某个\(-1\)改成\(1\)),而这样的位置我们可以发现,其实就是把初始的全\(1\)数列,改成了最后的全是\(-1\)的情况,一共会发生\(n\)次改动,每次改动都是单点修改
也就是说,我们此时只要拿主席树来进行这个修改操作,每次修改空间和时间都是\(O(logn)\)的,一共就是\(O(nlogn)\),可以承受
那么我们查询就是普通的线段树上查询就可以了
1月21日
P3402 可持久化并查集(可持久化数组,并查集)
我们考虑用可持久化数组来维护每一个下标的\(fa\)和\(dep\)(\(dep\)用于启发式合并)
然后考虑到这里的并查集不能路径压缩,于是考虑按秩合并(启发式合并)
所以用主席树来维护原本普通的\(fa\)数组和\(dep\)数组即可(就是把普通数组换成了可持久化数组)
最后注意启发式合并的实现
P3293 [SCOI2016]美味(可持久化值域线段树)
题意是查询一段区间中的异或和的最大值,所以可以想到按位贪心
也就是说,我们枚举当前可能的答案\(ans=a[i]+x\)的每一位(从高到低),于是我们可以发现,
最终答案\(a[i]\)一定落在:
\(\large [ans+(1<<i)-x,ans+(1<<(i+1))-1-x]\) \(\large (b[i]\)这一位为\(\large 0)\)
\(\large [ans-x,ans+(1<<i)-1-x]\) \(\large (b[i]\)这一位为\(\large1)\)
上面两种情况分别对应\(b[i]\)的当前位为\(0\)和\(1\)的情况
当\(b[i]\)为\(0\),则当前位为\(1\)答案更优
当\(b[i]\)为\(1\),则当前位为\(0\)答案更优
所以我们直接查询在两段值域区间内有没有数即可,如果有,那么继续下一位的枚举,当前这一位就变成\(1/0\),如果没有,那么当前这一位就变成\(0/1\),还是继续下一位,直到结束
此时\(ans=a[i]+x\),所以我们直接\(ans \bigoplus b\)就是最优的答案
因为要区间查询值域上数的个数,所以我们用值域线段树来维护
但是我们这样干只能记录对于下标区间\([1,n]\)的值域线段树(也就是全局),但是我们这里还要求某一个特定区间\([l,r]\)当中的值域线段树
这就是主席树的经典应用了,静态区间第\(k\)大的问题中我们就用过值域线段树维护值域,然后用下标的差来维护区间即可
所以我们这里采用主席树来维护值域就行了
1月22日
P4197 Peaks(Kruskal重构树,树上倍增,主席树[区间第\(k\)大] )
题解都说码农题(实际感觉还好\(?\))
容易发现,\(Kruskal\)最小生成树得出的重构树可以保证从当前点走的不经过点权大于\(x\)的点,可以得到的所有高度(就是所有可能到达的点)
稍微解释一下\(Kruskal\)重构树:

如图,左边是最小生成树中的一部分,现在我们可以将其转化成右图
也就是新建一个结点,令其点权等于原来的边权即可,然后连边,并将新的点作为原来点的祖先
然后我们题目对边的限制条件就变成了点的限制条件,,比如从点\(v\)走,限制为\(x\),也就是:
当前点\(v\),限制为\(x\)能到达的点等价于:
\(1.\)先从当前点往上跳,跳到其权值\(\leq x\)且深度最浅的点,记为\(fa\)。
\(2.\)\(fa\)作为根节点所有包含的叶子节点即为所求
想不懂这样为什么最小生成树是最优路径的同学,可以想一下\(Kruskal\)求最小生成树的过程:保证枚举的边按边权从小到大排序
于是\(Kruskal\)重构最小生成树便把原图直接化简成为了一棵树
(最小生成树化简图类似的应用:P1967 [NOIP2013 提高组] 货车运输,只是不是\(Kruskal\)重构树)
那么我们继续往下看,我们这样做了之后,可以发现:在跳到\(fa\)之后,每次要处理的点不过就是其子树代表的树上的一段区间而已
现在问题直接转化成了静态的区间第\(k\)大,套一个主席树即可,但是注意这里有无解的情况,所以主席树要特判无解(就是递归到底层的时候元素个数不够\(k\)个,就无解)
至于怎么往上跳,直接树上倍增即可
那么这道题就解决了,注意还要离散化\(...\)
2月
2月1日
P4211 [LNOI2014]LCA(树链剖分+线段树)
给出一个 \(n\) 个节点的有根树(编号为 \(0\) 到 \(n-1\),根节点为 \(0\))。
一个点的深度定义为这个节点到根的距离 \(+1\)。
设 \(dep[i]\) 表示点i的深度,\(LCA(i,j)\) 表示 \(i\) 与 \(j\) 的最近公共祖先。
有 \(q\) 次询问,每次询问给出 \(l\ r\ z\),求 \(\sum_{i=l}^r dep[LCA(i,z)]\) 。
两点\(LCA\)的\(dep\)有这样的一种转化:
例如\(u\)和\(v\),我们可以把\(u\)到根节点的路径上全部\(+1\),然后我们从\(v\)开始走到\(1\),把沿途路径统计\(sum\)就是\(dep[LCA(u,v)]\)了
那么我们考虑差分,这样的话就很简单了,比如对于一个区间\([l,r]\),我们可以先统计\([1,l-1]\)和\([1,r]\)的\(sum\),再相减就行了
于是这里问题就变成了:执行一些路径修改,然后查询一次路径的问题
如果强制在线我们可以使用树链剖分+主席树来处理,但是这里可以离线,于是可以离线询问,使用树链剖分+线段树即可
2月7日
CF958B2 Maximum Control (medium)(性质+长链剖分思想)

容易看出第一条就是直径,然后我们考虑处理每次的增量。
贪心地取挂在直径上的最长链,从大到小取即可。
可以看这篇题解。
3月
3月1日
P6664 [清华集训2016] 温暖会指引我们前行
LCT 维护最大生成树,以及统计路径权值和
重要的不是最小生成树,而是怎么维护边权。
可以使用拆点法。
具体来说就是新建一个节点为 \(n+EdgeNode\) ,然后把其权值设为边权 \(val\) 即可,剩下的原本是点的点其权值就是初始化状态。
P2387 [NOI2014] 魔法森林
LCT 维护双关键字最小生成树,一个道理
P4219 [BJOI2014]大融合
LCT 维护子树 \(siz\) ,我们可以通过维护每个点的所有虚子树信息再加上实子树信息即可,也就是代码里的 \(siz\) (实子树+虚子树) 和 \(si\) (虚子树)
具体有修改的只有两个函数:
1.Access
inline void Access(int x){
for(int y=0;x;x=fa[y=x]){
Splay(x);
si[x]+=siz[ch[x][1]];
si[x]-=siz[y];
ch[x][1]=y;
Pushup(x);
}
return;
}
2.Link
inline void Link(int x,int y){
Split(x,y);
si[fa[x]=y]+=siz[x];
return ;
}
因为只有这两个涉及到了虚子树的变化。
P3899 [湖南集训]谈笑风生
一道Dsu On Tree / 长链剖分。
先给出一条性质:\(a,b\) 两点一定处于 \(c->1\) 的路径上。
接下来我们可以分类讨论,很明显,我们只需要确定(枚举) \(a,b\) 点,那么对于 \(c\) 点计数就可以了。
所以我们枚举 \(a\) 是 \(1-n\) ,尝试讨论 \(b\) 点的分布情况,有两种,如果 \(b\) 在 \(a\) 点的上方,那么 \(b\) 有 \(\min(dep[a],K)\) 种方案,\(c\) 有 \(Size[a]\) 种方案,此时对答案的贡献即为 \(\min(dep[a],K)\times Size[a]\) 。
然后讨论 \(b\) 在 \(a\) 下方的情况。
容易发现只要 \(b\) 确定了,\(c\) 的情况就是 \(Size[b]-1\) ,那么任务就变成了找到所有合法的 \(b\) 。
这个我们只需要开个值域树状数组来维护,然后Dsu On Tree就可以了。
CF916E Jamie and Tree
换根树剖板题,重点在于 \(LCA\) 和子树的讨论。
这里还是放一下代码
int Find(int x,int y){
while(top[x]!=top[y]){
if(dep[top[x]]<dep[top[y]]) swap(x,y);
if(fa[top[x]]==y) return top[x];
x=fa[top[x]];
}
if(dep[x]>dep[y]) swap(x,y);
return son[x];
}
void TreeModify(int x,int k){
if(root==x){Modify(1,1,n,1,n,k);return ;}
int lca=QueryLCA(x,root);
if(lca!=x){Modify(1,1,n,dfn[x],dfn[x]+siz[x]-1,k);return ;}
int id=Find(x,root);
Modify(1,1,n,1,n,k),Modify(1,1,n,dfn[id],dfn[id]+siz[id]-1,-k);
return ;
}
ll TreeQuery(int x){
if(root==x){return Query(1,1,n,1,n);}
int lca=QueryLCA(x,root);
if(lca!=x){return Query(1,1,n,dfn[x],dfn[x]+siz[x]-1);}
int id=Find(x,root);
return Query(1,1,n,1,n)-Query(1,1,n,dfn[id],dfn[id]+siz[id]-1);
}
int LCA(int x,int y){
if(dep[x]>dep[y]) x^=y^=x^=y;
if(QueryLCA(x,y)==x){
if(dfn[root]>=dfn[y]&&dfn[root]<=dfn[y]+siz[y]-1) return y;
if(QueryLCA(x,root)==x) return QueryLCA(y,root);
return x;
}
if(dfn[root]>=dfn[x]&&dfn[root]<=dfn[x]+siz[x]-1)return x;
if(dfn[root]>=dfn[y]&&dfn[root]<=dfn[y]+siz[y]-1)return y;
if((QueryLCA(x,root)==root&&QueryLCA(x,y)==QueryLCA(y,root))||(QueryLCA(y,root)==root&&QueryLCA(x,y)==QueryLCA(x,root)))return root;
if(QueryLCA(x,root)==QueryLCA(y,root))return QueryLCA(x,y);
if(QueryLCA(x,y)!=QueryLCA(x,root))return QueryLCA(x,root);
return QueryLCA(y,root);
}
P3979 遥远的国度
同上,只不过是区间覆盖。
P4299 首都
LCT 维护重心板题,注意重心的性质,也就是新的重心必然处于相接的两个子树的重心的路径上。
那么核心在于怎么求,代码放一下:
inline int Search(int x){
int suml=0,sumr=0,sum=siz[x]>>1,odd=siz[x]&1,now=1e9+7,xx,yy;
while(x){
PushDown(x);
xx=suml+siz[ch[x][0]],yy=sumr+siz[ch[x][1]];
if(xx<=sum&&yy<=sum){
if(odd){now=x;break;}
else if(x<now){now=x;}
}
if(xx<yy) suml+=siz[ch[x][0]]+si[x]+1,x=ch[x][1];
else sumr+=siz[ch[x][1]]+si[x]+1,x=ch[x][0];
}
return now;
}
同时对于每一个点用并查集维护所在树的重心。
P2173 [ZJOI2012]网络
很裸的 LCT ,我们珂以直接开10个LCT来存一下每种颜色对应不同的图,再照常维护就行了。
BSOJ5359 远行
题意:
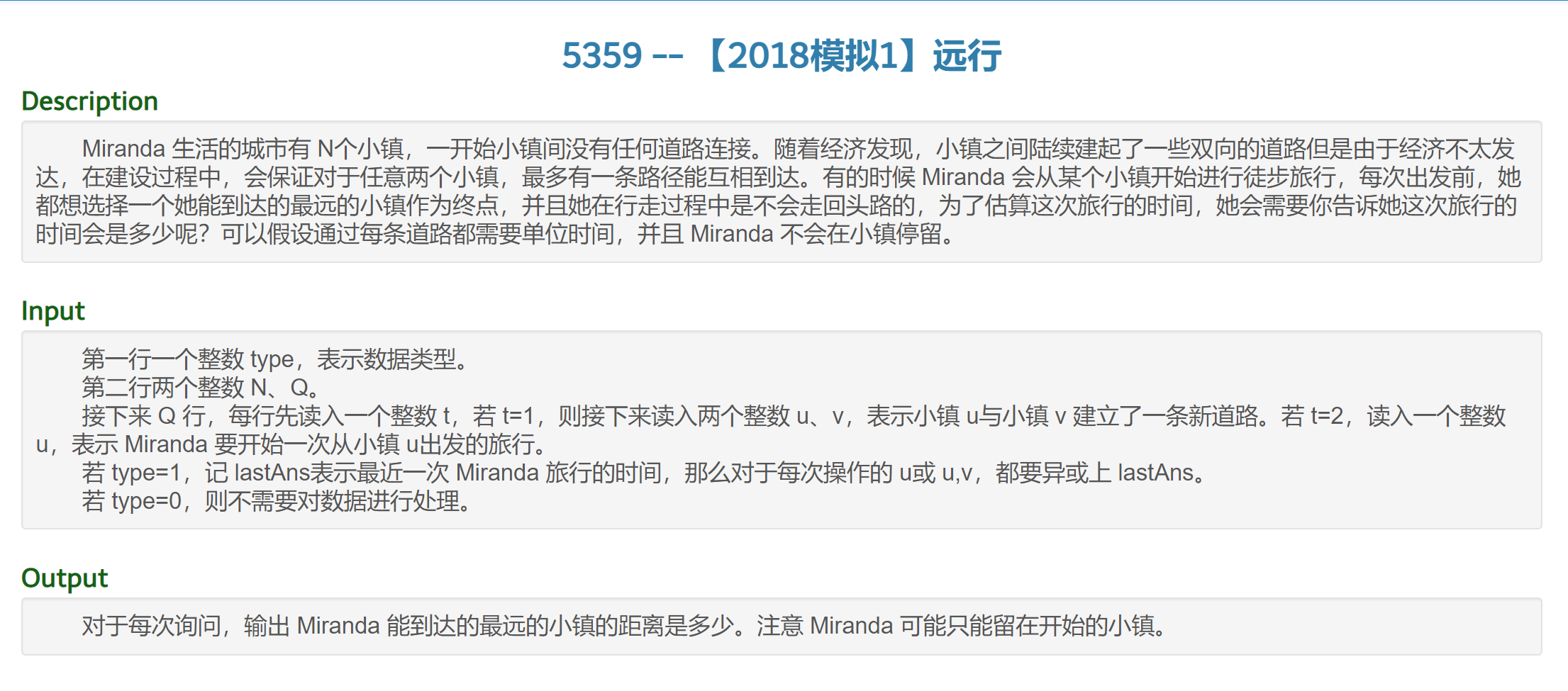
我们珂以看出这道题是让我们求树的直径,那么这道题就变成了LCT动态维护直径。
首先直径其实很好处理,就是分类讨论情况,然后更新直径即可。
然后对于每个点具体的对应直径用并查集维护。
3月2日
【模板】Trie树--前缀统计
就是打完标记,对于每次询问,我们可以统计沿途的标记的和即可。
拓展
Trie 树用于统计 LCP:
容易发现直接转化成为了 LCA 问题。
【算法竞赛】最长异或路径The xor-longest Path(POJ3764)
【算法竞赛】最长异或路径The xor-longest Path(POJ3764)
从高位到低位对于所有点建 01-Trie ,然后我们贪心的往反方向走就行了。
【模板】AC自动机(二次加强版)
对于 \(S\) 的每一个前缀,先在对应位置打上标记(因为 AC 自动机 Fail 的性质),然后我们对 Fail 树来一遍拓扑排序,类似树上差分的思路,不停地累计即可(为什么能累计:因为 AC 自动机 Fail 的性质)。
扩展
其实P3966 [TJOI2013]单词和这道题一模一样。
因为我们只要把所有小的串拼成一个大的(记为 \(S\) ),然后两道题就一样了(注意拼的时候要有间隔符)。
同样,这道题也有另外一种很好的做法,就是还是考虑 AC 自动机的性质,其实我们分析本质,这里我们根本不用拼起来,只需要在插入的时候一边插入一边打标记即可,最后上传是一样的。
【模板】AC自动机(加强版)
这道题就是把原本 \(endpos\) 的位置打上的标记换成了串的编号而已,注意处理一下映射即可。
P6018 [Ynoi2010] Fusion tree
P6018 [Ynoi2010] Fusion tree
01-Trie 树维护异或和。
这个题说是有个套路:对于每个点只维护子节点信息,然后父节点打标记(单独修改)。
于是这里我们对每个点开一个 01-Trie ,用于维护该点所有儿子的异或和。
而这个维护异或和的关键就在于数每一位的奇偶性。
这里要从低位到高位建树。
然后还有个关键就是全局 +1 ,根据 01-Trie 的性质,直接交换左右子树即可,具体正确性自己模拟。
【2020联合省选】树
01-Trie 树维护异或和+ 01-Trie 合并。
很容易看出来这个也是可以转化成全局 +1 这样的问题。
维护异或和不用多说,和上一道题唯一区别就是 01-Trie 合并,这里贴一下代码:
int Merge(int x,int y){
if(!x||!y) return x|y;
xorv[x]^=xorv[y];
w[x]+=w[y];
ch[x][0]=Merge(ch[x][0],ch[y][0]);
ch[x][1]=Merge(ch[x][1],ch[y][1]);
return x;
}
UVA11019 Matrix Matcher
题意:
给定两个字符矩阵 \(A\) 和 \(B\) ,求 \(A\) 中有多少个子矩阵和 \(B\) 完全相同。
解答:
最开始毫无思路,但是我们可以根据 “二维字符矩阵匹配” 转化成 “一维字符串匹配”。
于是我们可以想到先将 \(A\) 和 \(B\) 的每一行都缩成一个字符串(去重),然后我们可以对 \(B\) 的所有串建立一个 \(AC\) 自动机,把 \(A\) 的每一个串放进去匹配。
对于一个字符串 \(A_i\) 来说,我们假设它在位置 \(j\) 开始匹配到了 \(B_k\) ,那么我们就把对应点 \((i,j)\) 的编号设为 \(k\) 。
接下来相当于我们已经处理掉了横着的一维,对于列的一维,我们先将原 \(B\) 矩阵看成一个一维的编号数组。
然后我们对于 \(A\) 矩阵的每一列匹配这个一维编号数组就行了,实际上就是 KMP 匹配两个字符串即可。
CF1202E You Are Given Some Strings...
CF1202E You Are Given Some Strings...
题意:

直接拼不行,于是我们直接枚举原串的断点(注意这个技巧)。
然后发现对于每个拼接其实就是 AC 自动机,首先,我们由 Fail 树的性质—————不断跳到当前前缀的后缀的位置,可以得出当前点的后缀串匹配的个数就是 \(dep_i\) 个。
那么对于剩下的另一半,我们可以把所有的串都反过来再跑一次 AC 自动机,最后答案很明显就是乘法原理:把 \(n\) 个断电的答案累加,对于每一个点的贡献就是:左边可以有的前缀的后缀的数量*右边可以有的后缀的前缀数量,其实两者就是其在 AC 自动机上的深度。
所以利用这个性质我们直接统计即可。
P2414 [NOI2011] 阿狸的打字机
首先根据题意模拟可以建出 AC 自动机。
然后我们发现,对于每一个询问 \((x,y)\) ,对于 AC 自动机来说,其实就是在询问在 Fail 树上以 \(x\) 为根的子树内,有多少个 \(y\) 的前缀的标记。
解释一下为什么:因为一个结点 \(x\) 的子节点中有 \(y\) ,就代表 \(x\) 在 \(y\) 中出现过。
然后那就很简单了,我们直接离线询问,然后建出 Fail 树 和 Trie 树,因为要查子树内的权值和,所以我们在 Fail 树上跑 \(dfn\) 序,并统计子树 \(siz\) 。
然后我们在 Trie 树上 dfs ,通过树状数组统计答案,也就是每次来的时候加上这个点的贡献,回溯的时候删去,如果当前这个点有结尾标记,那么处理一下当前这个点作为询问中的 \(y\) 的询问(即把那些对应的 \(x\) 取出来询问一下子树和)。
然后就没有了。
3月3日
CF1437G Death DBMS(AC自动机+树剖)
修改就是直接在建出来的 Fail 树上的对应 \(endpos\) 处修改(对应后文的单点修)。
重点是询问,考虑这个询问对应到 AC 自动机上面是什么:当前串的子串--->当前串每一个前缀的 Fail 树上的祖先。
也就是说就是询问一个点到根的路径上的最大值,直接树剖即可。
CF710F String Set Queries(AC自动机+二进制分组)
CF710F String Set Queries(AC自动机+二进制分组)
非常牛逼的一道题。根据题意,就是动态的 AC 自动机(动态加字符串,删除字符串,查询所有串在模板串出现次数)
然后询问就是可以预处理每个点作为 \(endpos\) 的次数,对于一个串查其所有前缀的对应到根的边权总和。(直接预处理)
重点是怎么动态搞。
对操作二进制分组,也就是说,维护一堆树,大小分别是 \(2^{k_1},2^{k_2},...,2^{k^n}\) (大小即这个树是由前几个操作来的),然后每次二进制合并就是。
然后每次询问最多跑 \(logn\) 个树,每个串最多合并 \(logn\) 次,复杂度得到保证。
最后就是注意一下 Trie 树要单独建。
具体见题解。
P5840 [COCI2015]Divljak(AC自动机+LCA+BIT)
P5840 [COCI2015]Divljak(AC自动机+LCA+BIT)

我们发现对 \(T\) 集合建 AC 自动机非常的不好做(又要动态),所以我们考虑对 \(S\) 建 AC 自动机,然后每个 \(T\) 加入的时候都相当于修改一些节点的权值。
这里我们可以差分一下,把求点转化成求子树和,也就是把每次加入的 \(T\) 对应的 (假设为)序列 \(p\) 的地方都加上 1 的贡献。
所以可以发现对于所有的询问其实就是在询问 \(S_k\) 的子树和。
但是这里我们要避免统计同一个串两次,所以根据树上差分的思路,我们要把 \(LCA(p_i,p_{i-1})\) 处的点消去 1 的贡献 以及在 \(Fa[LCA(p_i,p_{i-1})]\) 处再消去 1 的贡献。
然后就是树状数组维护一下和就行了,记得还要树剖(因为统计子树嘛)。
坑点:树剖里更新 \(son\) 数组的时候注意判 \(0\) ,因为这个时候 \(0\) 节点有意义(代表 Fail 树的根节点)。
Trick(拓展)
关于在 LCA 处消去贡献的那一步,实际上先清楚我们这么做的目的:一个串在一次统计中只算一次。
而对于这个有个技巧就是我们必须先把该串对应的所有前缀对应的节点编号存下来,然后按照 dfn 序排序再按照上文的办法消去,这样消除才是正确的。
这个 Trick 非常实用,请务必记住。
P4556 [Vani有约会]雨天的尾巴 /【模板】线段树合并
P4556 [Vani有约会]雨天的尾巴 /【模板】线段树合并
线段树合并模板。
先很容易可以看出树上差分统计答案。
然后对于每个点用值域线段树来维护信息,所以统计就相当于维护值域内的最大值(维护的同时顺带更新对应的值是多少即可)。
然后对于父亲节点就相当于是把其多个儿子节点的信息合并,也就是值域线段树的合并。
然后这里还要求个 LCA 。。所以写个树剖什么的。。
重点放一下线段树合并的代码:
void Pushup(int x){
if(Maxn[ls[x]]>=Maxn[rs[x]]) Maxn[x]=Maxn[ls[x]],id[x]=id[ls[x]];
else Maxn[x]=Maxn[rs[x]],id[x]=id[rs[x]];
return ;
}
int Merge(int x,int y,int l,int r){
if(!x||!y) return x|y;
if(l==r){
Maxn[x]=Maxn[x]+Maxn[y];
if(Maxn[x]>0) id[x]=l;
else id[x]=0;
return x;
}
int mid=l+r>>1;
ls[x]=Merge(ls[x],ls[y],l,mid);
rs[x]=Merge(rs[x],rs[y],mid+1,r);
Pushup(x);
return x;
}
void Modify(int &x,int l,int r,int pos,int v){
if(!x) x=++cnt;
if(l==r){
Maxn[x]+=v;
if(Maxn[x]>0) id[x]=l;
else id[x]=0;
return ;
}
int mid=l+r>>1;
if(pos<=mid) Modify(ls[x],l,mid,pos,v);
else Modify(rs[x],mid+1,r,pos,v);
Pushup(x);
return ;
}
P3605 [USACO17JAN]Promotion Counting P(线段树合并)
P3605 [USACO17JAN]Promotion Counting P(线段树合并)
同样是一眼题。
对于每个点需要的是所有子节点的信息,所以就可以由其全部儿子的信息合并。
询问就相当于询问一个后缀值域的和。
3月4日
P5494 【模板】线段树分裂
线段树分裂和合并一般可以用于维护集合,这里便是模板。
贴一下板子,就不赘述了。
只是这个题有坑点: 开 long long
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=2e5+5;
#define ll long long
#define int long long
int n,m,Idx,now=1;
int ls[N<<5],rs[N<<5],root[N<<2],cnt,sta[N<<5],top;
ll sum[N<<5];
void Pushup(int x){sum[x]=sum[ls[x]]+sum[rs[x]];return ;}
void Delete(int x){sta[++top]=x,ls[x]=rs[x]=sum[x]=0;}
int NewNode(){return (top?sta[top--]:++cnt);}
int Merge(int x,int y){
if(!x||!y) return x+y;
sum[x]+=sum[y];
ls[x]=Merge(ls[x],ls[y]);
rs[x]=Merge(rs[x],rs[y]);
Delete(y);
return x;
}
void Split(int x,int &y,ll k){
if(!x) return ;
y=NewNode();ll v=sum[ls[x]];
if(k>v) Split(rs[x],rs[y],k-v);
else swap(rs[x],rs[y]);
if(k<v) Split(ls[x],ls[y],k);
sum[y]=sum[x]-k,sum[x]=k;
return ;
}
void Modify(int &x,int l,int r,int pos,int v){
if(!x) x=NewNode();
sum[x]+=v;
if(l==r) return ;
int mid=l+r>>1;
if(pos<=mid) Modify(ls[x],l,mid,pos,v);
else Modify(rs[x],mid+1,r,pos,v);
return ;
}
ll Query(int x,int l,int r,int ql,int qr){
if (qr<l||r<ql) {return 0;}
if(ql<=l&&r<=qr){return sum[x];}
int mid=l+r>>1;
return Query(ls[x],l,mid,ql,qr)+Query(rs[x],mid+1,r,ql,qr);
}
int QueryKth(int x,int l,int r,int k){
if(l==r) return l;
int mid=l+r>>1;
if(sum[ls[x]]>=k) return QueryKth(ls[x],l,mid,k);
return QueryKth(rs[x],mid+1,r,k-sum[ls[x]]);
}
signed main(){
read(n),read(m);
for(int i=1,x;i<=n;i++){
read(x);
Modify(root[1],1,n,i,x);
}
now=1;
for(int i=1,x,p,y,z,op;i<=m;i++){
read(op);
if(op==0){
read(p),read(x),read(y);
int k1=Query(root[p],1,n,1,y),k2=Query(root[p],1,n,x,y);
int tmp=0;
Split(root[p],root[++now],k1-k2);
Split(root[now],tmp,k2);
root[p]=Merge(root[p],tmp);
}
else if(op==1){
read(x),read(y);
root[x]=Merge(root[x],root[y]);
}
else if(op==2){
read(x),read(y),read(z);
Modify(root[x],1,n,z,y);
}
else if(op==3){
read(x),read(y),read(z);
write(Query(root[x],1,n,y,z)),puts("");
}
else if(op==4){
read(x),read(y);
if(sum[root[x]]<y){printf("-1\n");continue;}
printf("%d\n",QueryKth(root[x],1,n,y));
}
}
return 0;
}
P2824 [HEOI2016/TJOI2016]排序(线段树分裂&线段树合并)
P2824 [HEOI2016/TJOI2016]排序(线段树分裂&线段树合并)
对于值域建立线段树,所以对于排序操作自然是线段树的合并,然后因为有可能有重合的排序区间,所以这个时候即线段树分裂,再合并即可。
然后用 set 维护当前的整个数列的集合情况,分裂时用(因为排序,所以分裂就用 set 维护外部)。
CF558E A Simple Task(线段树分裂&线段树合并/线段树区间覆盖)
和上一题几乎一模一样,但是这里只是有重复的元素。
依然可以沿用上一题的解法,这里讲一下裸线段树的思路。
一看值域很小,于是我们可以开 26 个线段树,分别维护的是区间内该值的个数。
对于排序操作:先记录一下该区间内的 26 个元素的个数,然后相当于 从小到大/从大到小 对区间进行覆盖,打一下懒标记维护一下就行了。
具体核心代码:
void SortUp(int l,int r){
int now=l;
for(int i=1;i<=26;i++) t[i]=Query(1,1,n,l,r,i);
for(int i=1;i<=26;i++){
Modify(1,1,n,now,now+t[i]-1,i);
now+=t[i];
}
return ;
}
void SortDown(int l,int r){
int now=l;
for(int i=1;i<=26;i++) t[i]=Query(1,1,n,l,r,i);
for(int i=26;i>=1;i--){
Modify(1,1,n,now,now+t[i]-1,i);
now+=t[i];
}
return ;
}
(其中 Query 函数是查区间 \([l,r]\) 中,值为 \(i\) 的有多少个数。)
【BZOJ4771】七彩树(可持久化线段树&线段树合并)
题面:

摘自题解:
这个强制在线题目的第一想法应该是想办法求出这棵树每一个节点下的子树中出现的颜色的最小深度,并以此为键值,建立一棵线段树,
那么就可以很方便地统计出某一点子树的深度区间内的颜色数目。
我们现在再来考虑怎么维护这棵线段树(不难看出应当采用动态开点的方法)。
首先我们先把这个节点放入当前线段树,接下来我们就只要把它的儿子的线段树都合并在它自己所属的这棵线段树里面就好了、
问题时合并时怎么更新出现颜色的最小深度。
此时我们再在每个节点下面维护出现颜色的最小深度的线段树。
在每次合并时,先合并父节点和子节点上面所说的第二棵线段树,
如果有两个相同颜色的对应深度有不同,更新父节点第二棵线段树的信息,并在父节点第一棵线段树中删除对应的节点,然后将父节点和子节点的第一棵线段树合并。
CF163E e-Government(AC 自动机+ BIT + dfn 序 + LCA + 序列上差分)
CF163E e-Government(AC 自动机+ BIT + dfn 序 + LCA + 序列上差分)
这么多东西搞在一起其实也没有很难。。
其实我们可以发现,题目就是让我们求每一个串作为某个串的子串出现次数之和。(好像更难理解了。)
看一下样例就知道了..
input:
1 3
a
aa
ab
?aaab
output:
6
\(6=3+2+1\) ,题意就是这个。
好,那对应到 AC 自动机上面去,就是相当于询问一个串的每个前缀对应节点,Fail 树中从这个点到根节点路径上的 \(Endpos\) 标记之和。
同时还带修,支持把某个点的 \(Endpos\) 标记减一和加一。
暴力做当然是可以的,直接树剖或者 LCT 对着链上和一顿操作即可,但是这样做很麻烦(AC 自动机套个 LCT 就显得很烦了。。虽然码量也不算特别大。)
那么根据树上差分的思想,其实我们可以把原题从:
单点修改,链上查询。
变成:子树区间修改,单点查询。
然后我们再利用序列差分变成:单点修改,子树区间查询。
具体来说就是利用序列差分,先打一下 dfn 序,然后树状数组维护这两个操作即可。
Ex(延伸)
总的来说,这道题厉害的是那个题意的转化,也就是相当于反其道而行,其实我们这里的变化(尤其是从第一步到第二步),就是一个查询和修改的变换,有时候查询好统计,修改不好改,有时候修改方便,查询却又不利,这个时候我们就要学会变通。
再比如,一道题修改某些东西,我们会先考虑怎么去维护这个修改,但实际上我们也可以考虑每次修改对答案的影响。
所以,我们要做到的就是平衡,想问题要角度多一些。
P2336 [SCOI2012]喵星球上的点名(AC 自动机 + BIT + dfn 序 + LCA )
P2336 [SCOI2012]喵星球上的点名(AC 自动机 + BIT + dfn 序 + LCA )
这道题除了 AC 自动机中 Fail 树本身的性质,与其他题目最大不同是它 AC 自动机的建立。
这道题的字符集特别大,所以我们不能和以前一样直接存下来,于是可以想到用 Map 维护每个点可以到达的点集。
其他的区别不大,有三个地方要注意:
\(1.\) 对于一个喵星人,既有名又有姓,怎么统计呢?
直接把两个拼在一起然后搞一个间隔符就可以了。
\(2.\) 题目第一问要求不重复,于是和之前那道题一样,删除贡献即可。
\(3.\) Fail 树的构建(暂时不知道复杂度)
for(register mit it=t[0].son.begin();it!=t[0].son.end();it++) q[++r]=it->second,fail(it->second)=0;
while(l<=r){
int now=q[l];l++;
for(register mit it=t[now].son.begin();it!=t[now].son.end();it++){
int Fail=fail(now),val=it->first;
while(Fail and !son(Fail,val)) Fail=fail(Fail);
fail(it->second)=son(Fail,val);
q[++r]=it->second;
}
}
for(register int i=1;i<=node_cnt;i++) Add_Edge(fail(i),i);
然后这道题第一问就是让我们统计子树和,单点修改,第二问和上一题几乎一样,单点子树修改,然后单点查询即可。
最后这篇题解讲的不错,还看不懂可以看这个。
CF86C Genetic engineering(AC 自动机 + DP)
CF86C Genetic engineering(AC 自动机 + DP)
AC 自动机 + DP,还不怎么会,这里只说一下状态的设计:
dp[len][x][k]表示长度len且后缀状态为自动机结点x且后k位还不满足要求的方案数。
具体可以看这篇题解。
3月5日
SP16549 QTREE6 - Query on a tree VI(树剖/LCT)
SP16549 QTREE6 - Query on a tree VI(树剖/LCT)
没看 LCT ,这里用的是树剖。
其实我们发现题目就是维护连通块大小,然后还要支持单点修改。
首先,我们可以发现,对于一个连通块中的所有点,他们一定可以把答案挂到最上面的节点。
所以我们对每个点记一下 \(Black\) 点的个数(黑色联通块)和 \(White\) 点的个数(白色)。
那么我们询问就可以做了:对于一个点,把它跳到最上面的同色点,然后询问答案即可。
考虑修改操作,由于点 \(x\) 从黑变白和从白变黑是对称的,这里我们只讨论 \(x\) 从黑变白的情况.
从 \(Fa(x)\) 开始向上找到第一个白色点 \(u\),如果找不到的话 \(u=root\) ,将路径 \(Fa(x) \rightarrow u\) 上所有点的 \(Black\) 值减去 \(Black(x)\).
从 \(Fa(x)\) 开始向上找到第一个黑色点 \(u\),如果找不到的话 \(u=root\) ,将路径 \(Fa(x) \rightarrow u\) 上所有点的 \(White\) 值加上 \(White(x)\).
现在唯一剩下的问题是怎么找到 \(x\) 到根路径上的第一个白色/黑色点.
我们可以使用一颗线段树解决这个问题,树上每个节点维护其对应区间从右到左遇到的第一个白色点和黑色点的位置,这恰好对应了一条重链从下往上遇到的第一个白色点和黑色点的 \(dfs\) 序.
P4331 [BalticOI 2004]Sequence 数字序列(可并堆+贪心)
P4331 [BalticOI 2004]Sequence 数字序列(可并堆+贪心)
主要性质:
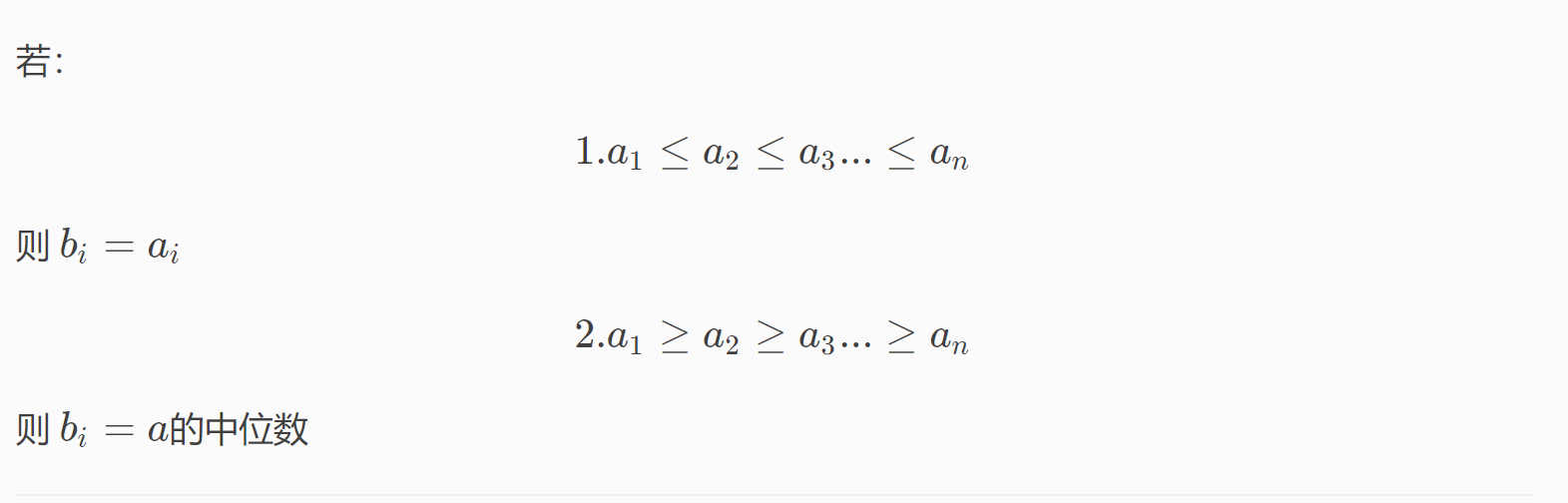
于是我们就可以根据这个把原序列分成若干个区间,具体实现就是把原序列一个一个加入队尾,如果中位数满足要求,那不管,如果不满足,就取出最顶上的两个区间合并。
这个可以用可并堆实现,具体就是把堆弹到只剩一半元素即可。
还有个 Trick 就是把单调递增的条件转化为单调不降:就是每个数差分一下,预先减掉其下标,也就是 \(a[i]-=i;\) 即可。
具体实现见代码。
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=1e6+5;
#define ll long long
int n,m,siz[N],val[N],ls[N],rs[N],rt[N];
ll a[N];
struct node{
int id,rs,ls;
ll key;
#define key(x) T[x].key
#define id(x) T[x].id
#define rs(x) T[x].rs
#define ls(x) T[x].ls
}T[N];
int Merge(int x,int y){
if(!x||!y) return x+y;
if(key(x)==key(y)?x>y:key(x)<key(y)) swap(x,y);
rs(x)=Merge(rs(x),y);
swap(ls(x),rs(x));
return x;
}
int top,st[N];
int main(){
read(n);
for(int i=1;i<=n;i++) read(a[i]),a[i]-=i,key(i)=a[i];
for(int i=1;i<=n;i++){
++top;rt[top]=rs[top]=ls[top]=i,siz[top]=1;val[top]=a[i];
while(top>1&&val[top-1]>val[top]){
int x=top-1;
rt[x]=Merge(rt[x],rt[top]);
siz[x]+=siz[top];
rs[x]=rs[top];
while(siz[x]*2>rs[x]-ls[x]+2){
siz[x]--;
rt[x]=Merge(ls(rt[x]),rs(rt[x]));
}
val[x]=key(rt[x]);
top--;
}
}
ll ans=0;
for(int i=1;i<=top;i++) for(int j=ls[i];j<=rs[i];j++) ans+=abs(a[j]-val[i]);
write(ans),putchar('\n');
for(int i=1;i<=top;i++) for(int j=ls[i];j<=rs[i];j++) write(val[i]+j),putchar(' ');
return 0;
}
P2596 [ZJOI2006]书架(平衡树)
两个思路,第一个就是直接维护平衡树,只不过不是按键值排序是按下标排序,插入删除时也有技巧。
主要困难在代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=8e4+5;
int n,m,ch[N][2],fa[N],cnt=0;
int num[N],pos[N],siz[N],rt=0;
void Pushup(int x){
siz[x]=siz[ch[x][0]]+siz[ch[x][1]]+1;
pos[num[ch[x][0]]]=ch[x][0],pos[num[ch[x][1]]]=ch[x][1];
return ;
}
void Rotate(int x,int p){
int y=fa[x];
fa[ch[x][!p]]=y,ch[y][p]=ch[x][!p];
fa[x]=fa[y];if(fa[y]) ch[fa[y]][ch[fa[y]][1]==y]=x;
fa[y]=x,ch[x][!p]=y;
Pushup(y),Pushup(x);
return ;
}
void Splay(int x,int goal){
while(fa[x]!=goal){
if(fa[fa[x]]==goal) Rotate(x,ch[fa[x]][1]==x);
else{
int y=fa[x],z=fa[y],p=ch[z][1]==y;
if(ch[y][p]==x) Rotate(y,p),Rotate(x,p);
else Rotate(x,!p),Rotate(x,p);
}
}
pos[num[x]]=x;
if(!goal) rt=x;
return ;
}
void insert(int key){
int x=rt;while(ch[rt][1]) x=ch[rt][1];
fa[++cnt]=x,ch[x][1]=cnt,num[cnt]=key,pos[key]=cnt,siz[cnt]=1,ch[cnt][0]=ch[cnt][1]=0;
Splay(cnt,0);
return ;
}
void Push(int s,int p){
Splay(pos[s],0);
if(!ch[rt][p]) return;
if(!ch[rt][!p]) ch[rt][!p]=ch[rt][p],ch[rt][p]=0;
else{
int x=ch[rt][!p];while(ch[x][p]) x=ch[x][p];
fa[ch[rt][p]]=x,ch[x][p]=ch[rt][p],ch[rt][p]=0;
Splay(ch[x][p],0);
}
return ;
}
void Insert(int t,int s){
Splay(pos[s],0);
if(!t) return;
if(t==1){
int suf=ch[rt][1],ps=pos[s];while(ch[suf][0]) suf=ch[suf][0];
swap(pos[s],pos[num[suf]]);
swap(num[ps],num[suf]);
}
else{
int pre=ch[rt][0],ps=pos[s];while(ch[pre][1]) pre=ch[pre][1];
swap(pos[s],pos[num[pre]]);
swap(num[ps],num[pre]);
}
return ;
}
void Ask(int s){Splay(pos[s],0);write(siz[ch[rt][0]]);return ;}
int Query(int s){
int x=rt;
while(1){
if(siz[ch[x][0]]+1==s) return num[x];
else if(siz[ch[x][0]]>=s) x=ch[x][0];
else s-=siz[ch[x][0]]+1,x=ch[x][1];
}
}
int main(){
ch[0][0]=ch[0][1]=siz[0]=fa[0]=num[0]=pos[0]=0;
read(n),read(m);
for(int i=1,x;i<=n;i++) read(x),insert(x);
for(int i=1;i<=m;i++){
char op[10];int x,y;
scanf("%s",op);
switch(op[0]){
case 'T':read(x),Push(x,0);break;
case 'B':read(x),Push(x,1);break;
case 'I':read(x),read(y),Insert(y,x);break;
case 'A':read(x),Ask(x),putchar('\n');break;
case 'Q':read(x),write(Query(x)),putchar('\n');break;
}
}
}
第二个就是用文艺平衡树的思路来做,感觉很妙,具体见这篇题解。
P4309 [TJOI2013]最长上升子序列(树状数组/平衡树)
P4309 [TJOI2013]最长上升子序列(树状数组/平衡树)
首先,观察题目,因为是依次从小到大插入,所以后面的一定比前面的大。
所以我们考虑每次插入后对答案的影响。
我们维护每个点结尾的最长上升子序列。
首先会影响到的点只有这个点,所以我们只需要统计一下这个点的答案即可,插入这个点对其他点原本位置的答案毫无影响。
那么怎么找以这个点结尾的最长上升子序列的长度呢?
找的正是这个点位置之前的前缀最大值,而这个点的答案就是 \(Maxn+1\) 。(因为不管怎么样这个点都可以拼接上这个序列,因为它是整个序列中目前最大的。)
所以这道题就是:动态加入一个数,询问前缀最大值。
可以使用平衡树维护区间,当然这里我用的暴力 vector 碾过去了。
CF965E Short Code(Trie树+贪心+堆)
很容易发现要建 Trie 树。
然后题目就变成了:给一棵树,有一些黑点。可以把黑点移到祖先处,但两个黑点不能在同一个位置。求最小的黑点深度和。
于是我们考虑贪心,每次对于每一个子树,都把深度最深的点提到根节点来(如果根节点没有黑点的话。)。
然后这个最深的点用堆维护一下即可,合并可以暴力加,因为总个数不超过 \(10^5\) 。
P4254 [JSOI2008]Blue Mary开公司(李超线段树)
P4254 [JSOI2008]Blue Mary开公司(李超线段树)
李超线段树模板题。
插入直线,单点询问最值。
李超树插入直线是 \(logn\) 的,查询单点也是 \(logn\) 的。
其核心就在于对于 \(mid\) 值的应用和区间的标记永久化。
比如对于插入一个直线,每个区间只有一个标记,我们就先将原来的标记与现在更新的直线比较,取两者间较优的,然后这样我们可以确定一个区间的答案,于是我们把剩下的劣一点的标记递归不确定的另一半区间。
然后询问每次都会经过路径上的所有标记,这就是标记永久化。
放一下代码。
int n,m,tag[N<<2],tot;
char op[10];
double k[N],b[N];
#define calc(i,x) (k[i]*(x-1)+b[i])
void Modify(int x,int l,int r,int d){
if(l==r){if(calc(d,l)>calc(tag[x],l)) tag[x]=d;return ;}
if(!tag[x]){tag[x]=d;return ;}
int mid=l+r>>1;
double Y1=calc(tag[x],mid),Y2=calc(d,mid);
if(k[tag[x]]<k[d]){
if(Y1<=Y2) Modify(x<<1,l,mid,tag[x]),tag[x]=d;
else Modify(x<<1|1,mid+1,r,d);
}
else if(k[tag[x]]>k[d]){
if(Y1<=Y2) Modify(x<<1|1,mid+1,r,tag[x]),tag[x]=d;
else Modify(x<<1,l,mid,d);
}
else if(b[tag[x]]<b[d]) tag[x]=d;
return ;
}
double Query(int x,int l,int r,int d){
if(l==r) return calc(tag[x],d);
int mid=l+r>>1;double res=calc(tag[x],d);
if(d<=mid) res=max(res,Query(x<<1,l,mid,d));
else res=max(res,Query(x<<1|1,mid+1,r,d));
return res;
}
3月6日
P4097 [HEOI2013]Segment(李超线段树)
P4097 [HEOI2013]Segment(李超线段树)
李超树插入线段,单点查询最值。
和上一道题唯一区别是插入线段而不是直线,注意:李超树插入线段是 \(log^2n\) 的,而插入直线是 \(logn\) 的。
放一下有区别的代码。(两个 Modify 意思是重载。)
void Modify(int x,int l,int r,int ql,int qr,int d){
if(ql<=l&&r<=qr){Modify(x,l,r,d);return ;}
int mid=l+r>>1;
if(ql<=mid) Modify(x<<1,l,mid,ql,qr,d);
if(qr>mid) Modify(x<<1|1,mid+1,r,ql,qr,d);
return ;
}
P7419 「PMOI-2」参天大树(数学)
打月赛随便签了个到。
观察性质,考虑递推得到答案。
把树画出来,发现对于每增加的一层,都会对上一层产生与层数相关的贡献。
写出来就是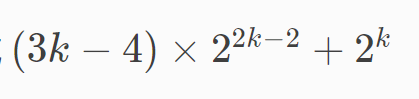 。
。
然后直接预处理过后询问就行。
P3195 [HNOI2008]玩具装箱(李超线段树+斜率优化)
P3195 [HNOI2008]玩具装箱(李超线段树+斜率优化)
先是 \(dp\)。

然后就是李超树维护了。
3月7日
P4069 [SDOI2016]游戏(李超树+树剖)
李超线段树+树剖。
先树剖,然后就是李超树线段插入,然后插入同时维护区间的最值,询问就是对区间最值的询问。
放一下李超树的代码。
#define calc(i,x) (k[i]*dis[rev[x]]+b[i])
void Modify(int x,int l,int r,int d){
if(l==r){if(calc(d,l)<=calc(tag[x],l)) tag[x]=d;Min[x]=calc(tag[x],l);Min[x]=min(Min[x],min(Min[x<<1],Min[x<<1|1]));return ;}
if(!tag[x]){tag[x]=d;Min[x]=min(calc(tag[x],l),calc(tag[x],r));Min[x]=min(Min[x],min(Min[x<<1],Min[x<<1|1]));return ;}
int mid=l+r>>1;
ll Y1=calc(tag[x],mid),Y2=calc(d,mid);
if(k[tag[x]]<k[d]){
if(Y1<=Y2) Modify(x<<1,l,mid,d);
else Modify(x<<1|1,mid+1,r,tag[x]),tag[x]=d;
}
else if(k[tag[x]]>k[d]){
if(Y1<=Y2) Modify(x<<1|1,mid+1,r,d);
else Modify(x<<1,l,mid,tag[x]),tag[x]=d;
}
else if(b[tag[x]]>=b[d]) tag[x]=d;
Min[x]=min(Min[x],min(Min[x<<1],Min[x<<1|1]));
return ;
}
void Modify(int x,int l,int r,int ql,int qr,int d){
if(ql<=l&&r<=qr){
Modify(x,l,r,d);
Min[x]=min(Min[x],min(calc(tag[x],l),calc(tag[x],r)));
Min[x]=min(Min[x],min(Min[x<<1],Min[x<<1|1]));
return ;
}
int mid=l+r>>1;
if(ql<=mid) Modify(x<<1,l,mid,ql,qr,d);
if(qr>mid) Modify(x<<1|1,mid+1,r,ql,qr,d);
Min[x]=min(Min[x],min(Min[x<<1],Min[x<<1|1]));
return ;
}
ll Query(int x,int l,int r,int ql,int qr){
if(ql<=l&&r<=qr) return Min[x];
ll res=min(calc(tag[x],max(l,ql)),calc(tag[x],min(r,qr)));int mid=l+r>>1;
if(ql<=mid) res=min(res,Query(x<<1,l,mid,ql,qr));
if(qr>mid) res=min(res,Query(x<<1|1,mid+1,r,ql,qr));
return res;
}
P6047 丝之割(李超树+斜率优化)
简要说就是转化成二维平面问题,然后 \(dp\)。
然后写出方程,用李超树优化 \(dp\) 。
CQA详细题解:

3月8日
CF1303G Sum of Prefix Sums(点分治+李超树)
CF1303G Sum of Prefix Sums(点分治+李超树)
先点分治,转化成可以确定两点路径的问题。
然后李超树维护路径(这里路径是一个一次函数。)。
有个 Trick 就是正着扫一遍再横着扫一遍,就能统计所有的答案。
CF932F Escape Through Leaf(李超树合并)
CF932F Escape Through Leaf(李超树合并)
首先是一个简单的 DP ,然后李超树维护。
对于树上的信息需要传递,所以李超树合并。
贴一下合并的代码。(注:还是动态开点。)
int Merge(int x,int y,int l,int r){
if(!x||!y) return x|y;
if(l==r) return calc(tag[x],l)>calc(tag[y],l)?y:x;
int mid=l+r>>1;
ls[x]=Merge(ls[x],ls[y],l,mid);
rs[x]=Merge(rs[x],rs[y],mid+1,r);
Modify(x,l,r,tag[y]);
return x;
}
P2161 [SHOI2009]会场预约(线段树)
线段树区间染色,区间统计颜色种数板题。
线段树部分代码:
struct Node{
int cnt,ml,mr,lc,rc;
Node operator + (const Node &b) {return (Node){(cnt&&b.cnt)?cnt+b.cnt-(rc&&(rc==b.lc)):cnt+b.cnt,min(ml,b.ml),max(mr,b.mr),lc,b.rc};}
void clear() {ml=mr=lc=rc=cnt=-1;}
};
struct SegMentTree{
Node tree[N<<3],tag[N<<3];
void pushdown(int x){
if (!~tag[x].cnt) return;
tree[x<<1].lc=tree[x<<1].rc=tree[x<<1|1].lc=tree[x<<1|1].rc=tag[x].cnt;
if (tag[x].cnt){
tree[x<<1|1].cnt=tree[x<<1].cnt=1;
tree[x<<1|1].ml=tree[x<<1].ml=tag[x].ml;
tree[x<<1|1].mr=tree[x<<1].mr=tag[x].mr;
tag[x<<1]=tag[x<<1|1]=tag[x];
}
else{
int mid=(tag[x].ml+tag[x].mr)>>1;
tree[x<<1|1].cnt=tree[x<<1].cnt=0;
tree[x<<1].ml=tag[x].ml;
tree[x<<1|1].ml=mid+1;
tree[x<<1|1].mr=tag[x].mr;
tree[x<<1].mr=mid;
tag[x<<1]=tag[x<<1|1]=tag[x];
tag[x<<1].mr=mid;tag[x<<1|1].ml=mid+1;
}
tag[x].clear();
}
void Modify(int x,int l,int r,int L,int R,int c){
if(L<=l&&r<=R){
tree[x].lc=tree[x].rc=c;
tag[x].cnt=c;
if (c){
tree[x].cnt=1;
tree[x].ml=L;tree[x].mr=R;
tag[x].ml=L;tag[x].mr=R;
}
else{
tree[x].cnt=0;
tree[x].ml=l;tree[x].mr=r;
tag[x].ml=l;tag[x].mr=r;
}
return;
}
int mid=(l+r)>>1;
pushdown(x);
if(L<=mid) Modify(x<<1,l,mid,L,R,c);
if(mid<R) Modify(x<<1|1,mid+1,r,L,R,c);
tree[x]=tree[x<<1]+tree[x<<1|1];
}
Node Query(int x,int l,int r,int L,int R){
if (L<=l&&r<=R) return tree[x];
pushdown(x);
int mid=(l+r)>>1;
if (mid<L) return Query(x<<1|1,mid+1,r,L,R);
if (mid>=R) return Query(x<<1,l,mid,L,R);
return Query(x<<1,l,mid,L,mid)+Query(x<<1|1,mid+1,r,mid+1,R);
}
void build(int x,int l,int r){
tag[x].clear();
if (l==r){
tree[x].cnt=0;
tree[x].lc=tree[x].rc=0;
tree[x].ml=tree[x].mr=l;
return;
}
int mid=(l+r)>>1;
build(x<<1,l,mid);build(x<<1|1,mid+1,r);
tree[x]=tree[x<<1]+tree[x<<1|1];
}
}T;
P1083 [NOIP2012 提高组] 借教室(二分+前缀和)
P1083 [NOIP2012 提高组] 借教室(二分+前缀和)
二分+前缀和简单题。
P4416 [COCI2017-2018#1] Plahte(扫描线+ \(set\) 启发式合并)
P4416 [COCI2017-2018#1] Plahte(扫描线+ \(set\) 启发式合并)
首先是扫描线,维护出一棵树的关系出来。
然后就是节点数颜色了,可以 \(set\) 启发式合并。
码量十足。
P4079 [SDOI2016]齿轮(带权并查集)
带权并查集。
首先发现对于一棵树肯定不会有矛盾的情况。
有矛盾当且仅当出现环且系数有错。
所以对于 \((u,v)\) 的联通情况分类讨论,然后并查集带权维护环的值即可。
简要代码:
int T,n,m,fa[N];
double k[N];
int get(int x){
if(x==fa[x])return x;
int pa=get(fa[x]);
k[x]*=k[fa[x]];
return fa[x]=pa;
}
放一下详细题解:

P4655 [CEOI2017]Building Bridges(李超树+斜率优化)
P4655 [CEOI2017]Building Bridges(李超树+斜率优化)
李超树优化 dp 简单题。
设状态为 \(dp_i\) 表示从 \(1\) 可到达 \(i\) 的最小代价。
方程很好写,就是 \(dp_i=dp_j+Sum_{i-1}-Sum_j+(h_i-h_j)^2\) 。
然后展开一下是 \(dp_i-h_i^2-Sum_{i-1}=dp_j-Sum_j+h_j^2-2 \times h_i \times h_j\)
其中设 \(k=h_j\) ,\(b=dp_j-Sum_j+h_j^2\),\(x=h_i\) 。
那么 \(dp_i\) 就是查询出来的这个最小值加上 \(h_i^2+Sum_{i-1}\) 即可。
当成板题,贴一下代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
#define ll long long
const int N=1e5+9,M=1e6+9;
ll k[N],b[N],h[N],w[N],f[N];
int tag[M<<2],u;
#define calc(i,x) (k[i]*x+b[i])
void Modify(int x,int l,int r,int d){
if(l==r){if(calc(d,l)<calc(tag[x],l)) tag[x]=d;return ;}
if(!tag[x]){tag[x]=d;return ;}
int mid=l+r>>1;
ll Y1=calc(tag[x],mid),Y2=calc(d,mid);
if(k[tag[x]]<k[d]){
if(Y1<=Y2) Modify(x<<1,l,mid,d);
else Modify(x<<1|1,mid+1,r,tag[x]),tag[x]=d;
}
else if(k[tag[x]]>k[d]){
if(Y1<=Y2) Modify(x<<1|1,mid+1,r,d);
else Modify(x<<1,l,mid,tag[x]),tag[x]=d;
}
else if(b[tag[x]]>b[d]) tag[x]=d;
return ;
}
ll Query(int x,int l,int r,int d){
if(l==r) return calc(tag[x],d);
int mid=l+r>>1;ll res=calc(tag[x],d);
if(d<=mid) res=min(res,Query(x<<1,l,mid,d));
else res=min(res,Query(x<<1|1,mid+1,r,d));
return res;
}
int n;
int main(){
read(n),b[0]=1e18;
for(int i=1;i<=n;i++) read(h[i]);
for(int i=1;i<=n;i++) read(w[i]),w[i]+=w[i-1];
k[1]=-2*h[1],b[1]=h[1]*h[1]-w[1],Modify(1,0,M,1);
for(int i=2;i<=n;i++){
f[i]=h[i]*h[i]+w[i-1]+Query(1,0,M,h[i]);
k[i]=-2*h[i],b[i]=f[i]+h[i]*h[i]-w[i],Modify(1,0,M,i);
}
write(f[n]);
return 0;
}
1212【线段树】矩形面积的并Atlantis(POJ1151)(扫描线)
1212【线段树】矩形面积的并Atlantis(POJ1151)(扫描线)
这题和 P5490 【模板】扫描线 几乎一模一样。
扫描线板题。
考虑从下往上扫描,对于每一个矩形,我们只记下其下端和上端的两条线段,存起来,对下面的线段打上 +1 标记,上面的打上 -1 标记。
然后我们对每一条线段排序,以 \(y\) 坐标为优先级。
(记得离散化。)
然后在扫的过程中,答案加上当前的 \(len*Delta\) ,然后照常 \(Modify\) 即可。
这里的区间修改有技巧(因为查询只查全局(即根节点))。
放一下模板题的代码:
#include<bits/stdc++.h>
#define ll long long
using namespace std;
const int N=2e6+5;
#define y2 qwq
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch==-'-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
struct Line{
ll x1,x2,y;
bool type;
bool operator <(Line another)const{
return y<another.y;
}
}lines[N];
int cnt=0;
struct Node{
int l,r;
ll len,cnt;
}tr[N];
void build(int p,int l,int r){
tr[p].l=l,tr[p].r=r;
if(l==r)return;
int mid=(l+r)>>1;
build(p<<1,l,mid);
build((p<<1)|1,mid+1,r);
return ;
}
ll a[N];
void pushup(int p){
if(tr[p].cnt) tr[p].len=a[tr[p].r+1]-a[tr[p].l];
else tr[p].len=tr[p<<1].len+tr[(p<<1)|1].len;
return ;
}
void modify(int p,int l,int r,int val){
if(tr[p].l>=l&&tr[p].r<=r){
tr[p].cnt+=val;
pushup(p);
return;
}
int mid=(tr[p].l+tr[p].r)>>1;
if(l<=mid)modify(p<<1,l,r,val);
if(r>mid)modify((p<<1)|1,l,r,val);
pushup(p);
}
int n;
int main(){
read(n);
for(int i=1;i<=n;i++){
ll x1,y1,x2,y2;
read(x1),read(y1),read(x2),read(y2);
lines[++cnt].x1=x1,lines[cnt].x2=x2;
lines[cnt].y=y1,lines[cnt].type=0;
lines[++cnt].x1=x1,lines[cnt].x2=x2;
lines[cnt].y=y2,lines[cnt].type=1;
a[i]=x1,a[i+n]=x2;
}
sort(a+1,a+2*n+1);
int cnt=unique(a+1,a+2*n+1)-a-1;
sort(lines+1,lines+2*n+1);
build(1,1,cnt-1);
ll ans=0;
for(int i=1;i<=2*n;i++){
Line now=lines[i];
if(i>1)ans+=tr[1].len*(lines[i].y-lines[i-1].y);
if(now.type) modify(1,lower_bound(a+1,a+cnt+1,now.x1)-a,lower_bound(a+1,a+cnt+1,now.x2)-a-1,-1);
else modify(1,lower_bound(a+1,a+cnt+1,now.x1)-a,lower_bound(a+1,a+cnt+1,now.x2)-a-1,1);
}
cout<<ans<<endl;
return 0;
}
1237【二维树状数组】单点修改,区间查询
如题面。
其实二维的就是多了一个 \(log\),具体见代码。
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=5e3+5,M=2e5+5;
#define ll long long
ll c[N][N];
int n,m;
void add(int x,int y,int v){
for(int i=x;i<=n;i+=(i&(-i))){
for(int j=y;j<=m;j+=(j&(-j))){
c[i][j]+=v;
}
}
return ;
}
ll ask(int x,int y){
ll res=0;
for(int i=x;i;i-=(i&(-i))){
for(int j=y;j;j-=(j&(-j))){
res+=c[i][j];
}
}
return res;
}
int main(){
read(n),read(m);int op;
while(scanf("%d",&op)!=EOF){
if(op==1){
int x,y;ll k;
read(x),read(y),read(k);
add(x,y,k);
}
else{
int X1,Y1,X2,Y2;
read(X1),read(Y1),read(X2),read(Y2);
write(ask(X2,Y2)+ask(X1-1,Y1-1)-ask(X1-1,Y2)-ask(X2,Y1-1)),putchar('\n');
}
}
return 0;
}
1210【线段树】矩阵Matrix(POJ2155)
线段树扫描线维护周长。
大概思路:横着扫一遍,竖着扫一遍,加起来。
有只扫一遍的办法,不用掌握。
5918【BZOJ4919】大根堆
\(set\) 启发式合并 + 贪心。
题解说就是树上 LIS ,还不是很懂这个贪心。
对每个点维护一个 \(set\) ,然后每次删掉大于等于当前数的第一个数,再把这个数插入。
至于 \(set\) 怎么上传就是大力启发式合并就行了。
最后询问 \(siz\) 即可。
