



Mapreduce求气温值项目
Mapreduce前提工作
简单的来说map是大数据,reduce是计算<运行时如果数据量不大,但是却要分工做这就比较花时间了>
首先想要使用mapreduce,需要在linux中进行一些配置:
1.在notepad++里修改yarn-site.xml文件,新添加


<property> <name>yarn.resourcemanager.hostname</name> <value>192.168.64.141</value> </property> <property> <name>yarn.nodemanager.aux-service</name> <value>mapreduce_shuffle</value> </property> 在notepad++里修改mapred-site.xml文件,新添加 <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
2.在xshell里将soft/soft/hadoop/etc/hadoop下的mapred-site.xml.template去掉后缀名

3.保证在start-dfs.sh、start-yarn.sh服务打开情况下

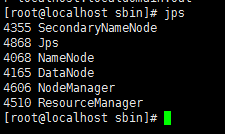
检测服务是否打开。输入Jps,显示namenod 和 datanod
4.到hadoop目录下新建一个有数据的txt

 (保存退出是 Esc 后输入:wq!)
(保存退出是 Esc 后输入:wq!)
5.确保文件存在之后,将其放在hadoop文件下(如果用可视化界面如XFTP比较难找目录,但是使用eclipse上的小蓝象还是挺方便的)

6.在我们的ip下查看,已经将hadoop.txt放进了hadoop下


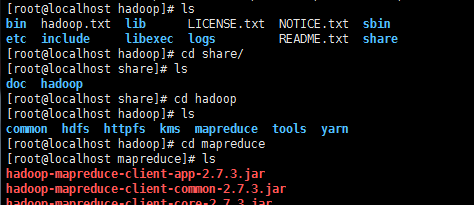
7.到hadoop下的mapreduce文件下
8.在hadoop下运行(这里hadoop-mapreduce-examples-2.7.3.jar是以及放在上面的架包工具)

可以看见数据在map和reduce之间传



9.也可以刷新eclipse里面的hadoop文件下的abc.txt查看结果
接下来我们自己来写一个mapreduce吧!
在mapreduce中,map和reduce是有个字不同的所以要单独写成两个类。
1.引入架包
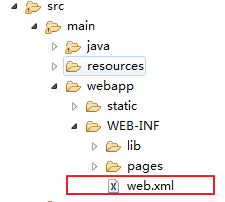
2.创建webapp下的WEB-INF文件下的web.xml
2.建类
Worldcount项目
Mapper代码:
package com.nenu.mprd.test;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MyMap extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
String line=value.toString();
String[] words=line.split(" ");
for (String word : words) {
context.write(new Text(word.trim()), new IntWritable(1));
}
}
}
Reduce代码:
package com.nenu.mprd.test;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// TODO Auto-generated method stub
int sum=0;
for (IntWritable intWritable : values) {
sum+=intWritable.get();
}
context.write(key, new IntWritable(sum));
}
}
Job代码:
package com.nenu.mprd.test;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MyJob extends Configured implements Tool{
public static void main(String[] args) throws Exception {
MyJob myJob=new MyJob();
ToolRunner.run(myJob, null);
}
@Override
public int run(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf=new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.64.141:9000");
Job job=Job.getInstance(conf);
job.setJarByClass(MyJob.class);
job.setMapperClass(MyMap.class);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("/hadoop/hadoop.txt"));
FileOutputFormat.setOutputPath(job, new Path("/hadoop/out"));
job.waitForCompletion(true);
return 0;
}
}
Weather平均气温项目:
Mapper代码:
package com.nenu.weathermyreduce.test;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
//传入文件 输出拆分后的每个单词
public class MyMap extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
//获取文件目录下的每个文件的部分文件名
FileSplit filesplit = (FileSplit)context.getInputSplit();
String fileName = filesplit.getPath().getName().substring(5,10).trim();
//获取气温值
//每次只处理一行 字符偏移量下一行第一个字符为上一行最后一个字符位+1
//按行提取字符串
String line=value.toString();
//获取对应位置上的气温
Integer val =Integer.parseInt(line.substring(13, 19).trim());//去掉空格
//文件名作为输出key 获取的气温值作为value
//相同的key会交给同一个reduce进行计算
context.write(new Text(fileName), new IntWritable(val));
}
}
Reduce代码:
package com.nenu.weathermyreduce.test;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
//输入单词 输出混洗、统计结果和
public class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// TODO Auto-generated method stub
//求平均数
//计数 一共有多少个数据
int sum=0;//和
int count=0;//计算
for (IntWritable val : values) {
count++;
sum+=val.get();//转换为int类型
}
int average = sum/count;
context.write(key, new IntWritable(average));
}
}
Myjob代码:
package com.nenu.weathermyreduce.test;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MyJob extends Configured implements Tool{
public static void main(String[] args) throws Exception {
MyJob myJob=new MyJob();
ToolRunner.run(myJob, null);
}
@Override
public int run(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf=new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.64.141:9000");
Job job=Job.getInstance(conf);
job.setJarByClass(MyJob.class);
job.setMapperClass(MyMap.class);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("/hadoop/weather"));
FileOutputFormat.setOutputPath(job, new Path("/hadoop/weather/out"));
job.waitForCompletion(true);
return 0;
}
}
3.开启服务,dfs+yarn。(所有mapreduce项目都需要开启yarn,yarn下管理资源和节点)
4.运行job类
Job的任务:
是mapreduce程序运行的主类。指定使用的是哪个mapper哪个reduce
指定mapper、reduce输入输出的key-value类型
以及输入、输出的数据位置
要说明的一点是,在我的程序中Job提交---一般是用waitforCompletion(true)可以看见运行过程(不用submit)


