



手机号流量统计---Mapreduce项目分析
文档显示:

每行依次是 ~手机号~上行流量~下行流量
需求分析:
需要统计各自的手机号,及上行、下行、总流量
具体做法:
1.定义map输入输出类型
通常情况下map的输入的key-value就是longwritable,text
我们知道Map读取的过程为:读一行返回一个key-value对,每调用一行就执行一次map方法。而输出value应该是每行的上行流量和下行流量以及总流量,我们想到了对象。输出value可以为bean类----在mr程序中,可以使用自定义的类型作为mr的输出数据类型,但是前提是实现hadoop的writable序列化机制
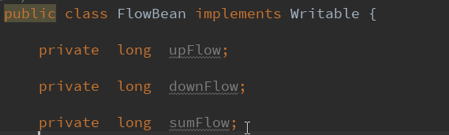
2.创建bean类---
2.1定义属性(注意:long类型)
自行通过setget / lambok+data注解 使用属性
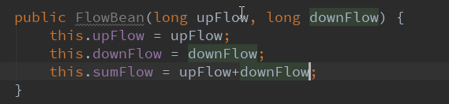
2.2构造方法
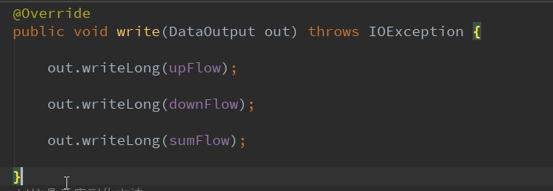
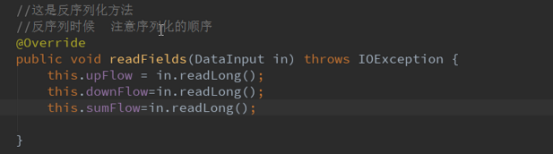
2.3重写序列化write和反序列化方法
序列化
反序列化(注意:先序列化的先反序列化)
3.map阶段
应该是手机号作为key,上行流量+下行流量作为value
小技巧:
1.如果line中间数据有丢失,可以正着+倒着配合获取字段)
2.构造函数参数和中间设置要机灵点儿哦
3.1map完成
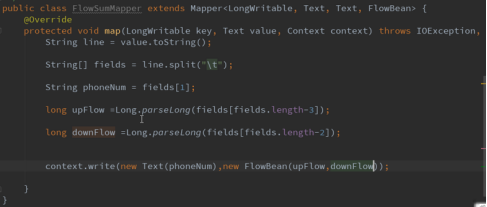
3.2.但是由于每次调用map方法都需要new,这样会增大垃圾回收量,所以优化提前new出所需对象,整个过程只需要重新set。
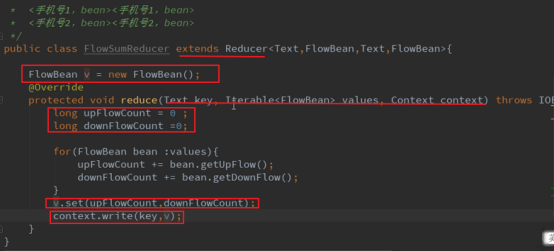
4.reduce阶段
Map的输出为reduce的输入,设置统计参数
5.job阶段
Job相当于是模板方法,大量代码都是一致的。所以我们可以找到之前的mapreduce的方法进行 黏贴修改代码、重新导包 即可。
6.重写toString 避免输出文件中是对象不便于观察

接下来我们可以在本地跑一下,拍桌子散伙!
-------补作业了!

