


python课后练习题
由于本人python学得太水,且最近心态浮躁,于是打算从0开始学习python,希望可以坚持。
01篇

答案
【测试题】
0.脚本语言Scripting language。与C语言/C++/JAVA语言不一样,脚本语言直接写出能让电脑听懂的程序,不需要编译,直接运行。
Why Python的优点是什么?①python是跨平台的 ②相同的程序,用python写代码量更少 ③应用范围广,如WEB/OS/3D动画/云计算/企业服务等。
1.IDLE是以键入文本的方式对python程序进行编程的SHELL编程命令行"工具",就像cmd命令行窗口一样,可以直接对操作系统下达命令。其中,ALT+N是回到上一行,ALT+P是回到下一行,CTRL+C强制停止,CTRL+N是新建一个窗口[编写后保存后run],F5是run module(python是模块化编程)
2.显示输出内容
3.*
4.*5,既可以对字符串/字符进行运算[连续],也可以对数值类型进行运算。但是+5,由于+要求对相同类型进行运算,5是数值类型,只能对数值类型进行。
5.用转义字符\",或者print(' " ')-单引号和双引号混合使用
6.python升级后,很多地方进行了修改,对python 2许多地方并不兼容。
【动动手】
0.“i love xhj”是类型和内容,print("i love xhj")只有内容
1.首先判断年是闰年还是平年,然后计算。
2.配置python环境变量[我的anaconda自动加进去了],并验证[如下]。
新建txt文件 -> 第一行写 #!usr/bin/python【表示该文件是可执行python脚本】-> 然后换行写python程序 -> 保存退出,并将文件后缀改为py -> 打开cmd,输入 ”python“ + [空格] + [该文件目录]
02篇

答案
【测试题】
0.built in function内置函数,可以直接调用。
1.进入IDLE,输入dir(__builtins__),可得到python3提供的BIF。再输入help(某个内置函数名),可以得到解读。
2.不一样,python命名规范和C一样。
3.缩进(我的答案既然是忠诚哈哈哈哈)
4.C语言中如果写if(a=1),会直接往下运行。而再python 的if语句中,如果写成了 if a=1,会自动报错,帮助我们找bug哈。
5.字符串拼接。
【动动手】
0.首先input内置函数返回值是字符串类型的,不用转换类型可以直接输出。然后运行的地方,选择run module 或者按F5运行 py该文件。
1.input返回值首先要转换为int类型,其次if判断中"或者"是用“or”表示,而不是“||”表示。
03篇
答案
【测试题】
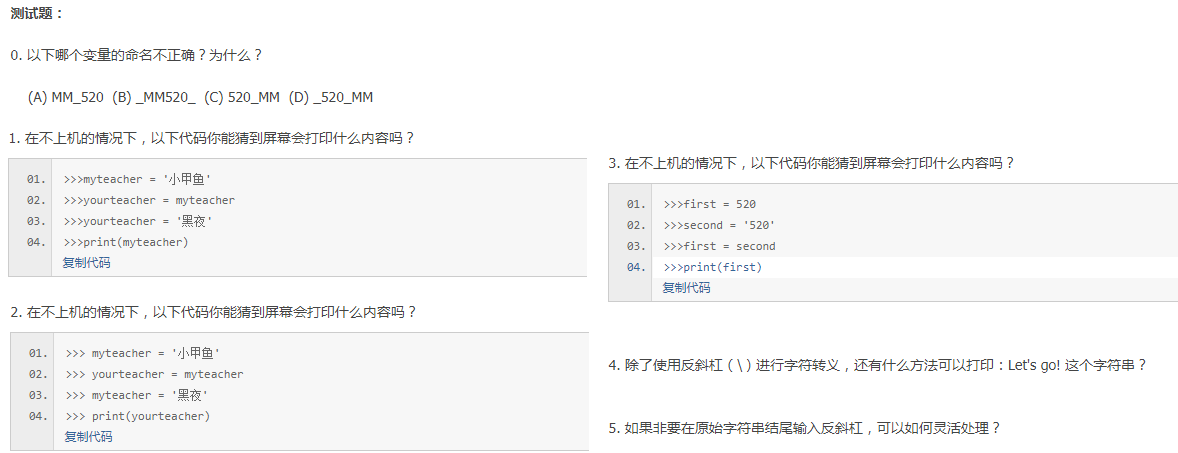
0.C,python的变量命名规范和C一样。
1.小甲鱼,PS:python的变量没有类型可言。
2.小甲鱼,没有赋地址。
3.520,但它是个字符串。如果单独>>>first ,就会输出'520'
4.str = r"Let's go" ,r代表原始字符串。或者用三重引号字符串,str = """Let's go"""。或者使用单双引号混用str = "Let's go"。他们都是可以保存原始格式的。
5.str = r'C:\Program Files\FishC\Good''\\' 这里'\\'就是'\'的转义字符表示。
04篇
答案
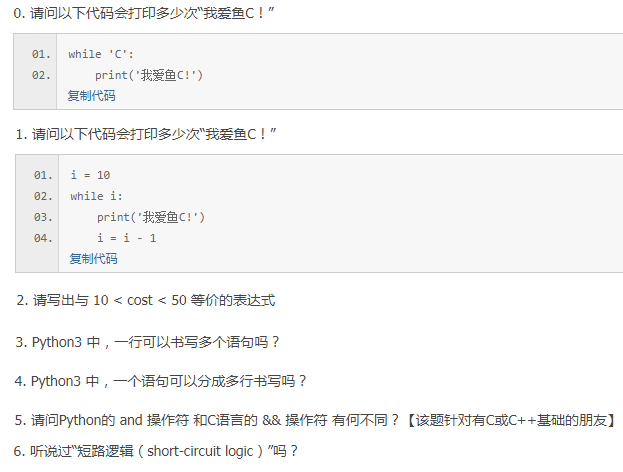
0.无数次。 CTRC+C强制结束。
1.10次
2.(10 < cost) and (cost<50)
3.python中一行可以输多行语句,只要中间用分号隔开就好。如,print("i love") ;print("xhj")
4.python中一条语句也可以分成多行写。
5.C的and和Python的and不一样!
C的and要求两边都为True,结果才是True,如1 and 0 ->0,1 and 3 ->1。Python的and,词不达意,如1 and 0 ->0,1 and 3 ->3
5.短路逻辑:即不需要运算的时候就不运算。举个例子,x and y 当x为False时就不再继续看y,直接返回False。
05篇

答案
【测试题】
0.python中int类型代表整数,而且不限长度。同样float也是,他代表小数(有小数点的数),bool是布尔类型,str是字符串类型。
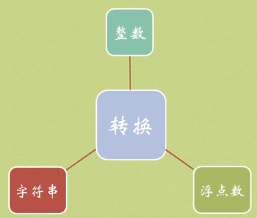
转换:float->int是直接截断小数点后面的数,int->float是直接加小数点,str->int要求只能str内容是整数,同理str->float,int/float->str 可以直接转。转换方式:类型(转换内容)
1.因为01二进制,计算机就不用再转换浪费力气了。
2.截断处理
3.如何对小数进行四舍五入呢?既然是+0.5,如int(3.4+05)->3,int(3.5+0.5)->4。
4.type返回类型,isinstance返回True/False。
5.python3允许中文作为变量名,因为源码文件是用utf-8编写的(支持中文)。如,我的猪 = “徐浩军”。
【动动手】
我们知道temp = input("输入内容")中type是字符串类型,但这个字符串类型转换时如何去避免类型错误呢?
s.isalnum() 所有字符都是数字或者字母,为真返回 True,否则返回 False。
s.isalpha() 所有字符都是字母,为真返回 True,否则返回 False。
s.isdigit() 所有字符都是数字,为真返回 True,否则返回 False。
s.islower() 所有字符都是小写,为真返回 True,否则返回 False。
s.isupper() 所有字符都是大写,为真返回 True,否则返回 False。
s.istitle() 所有单词都是首字母大写,为真返回 True,否则返回 False。
s.isspace() 所有字符都是空白字符,为真返回 True,否则返回 False。
06篇

答案
0.python运算符中,/是精确除法,无论是否整除,返回值都是小数。//是地板(Floor)除法,返回值是截断余数后的整数,但运算数中如果有小数,就直接得出精确结果。
1.True或者是False
2.那得用计算器了,0.04。需要注意的是 -1**2 -> -1,1**-2 ->0.5
3.x%2 == 0余数
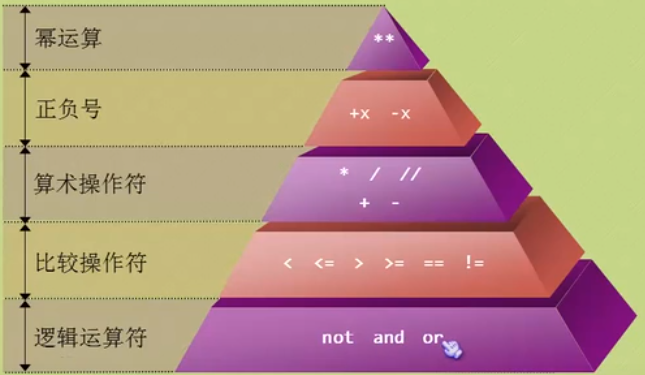
4.第一点,not or and 的优先级是不同的:not > and > or ,所以括号很重要。第二点,“短路逻辑”,4and3 为4,4or3 为3。
07、08篇

答案
0.if money>=100
1.断言,当这个关键字后边的条件为假的时候,程序自动崩溃并抛出AssertionError的异常。如,assert(a>10),如果不满足条件就会排除assertError的错误。用来测试。
2.不是使用中间变量,而是x, y, z = z, y, x
3.母鸡
4.成员资格运算符也就是in , not in
09篇

答案
0.5次
1.报错。 in 是“成员资格运算符”,python中的for更像foreach,这里应该改成for i in range(5)
2.continue是跳出本轮循环进行下一轮循环,break是终止当前循环,跳出循环体。
3.列表list元素可以是各种各样的类型,列表的追加extend,apend,insert,列表的删除remove,pop,列表的查找索引或者内容,列表的排序sort
4.0-9
5.打印2 3 ,因为 break 只能跳出一层循环。
10篇【列表】

答案
0.各种类型,如int,float,bool,str,list都可以。
1.append追加,extend追加,insert插入。区别在于append只能通过加入追加单个元素,extend可以加入多个元素,insert可以插入特定位置。
2.append() 方法是将参数作为一个元素增加到列表的末尾。extend() 方法则是将参数作为一个列表去扩展列表的末尾。如a1 = [99,'love',['xhj',66]] a2 = [99,'love',['xhj',66]] b =[1,2,3] c=a1.append(b) d = a2.extend(b) ----> c:[99,'love',['xhj',66],[1,2,3]] d:[99,'love',['xhj',66],1,2,3]
3.不一样
4.insert
11篇【列表】
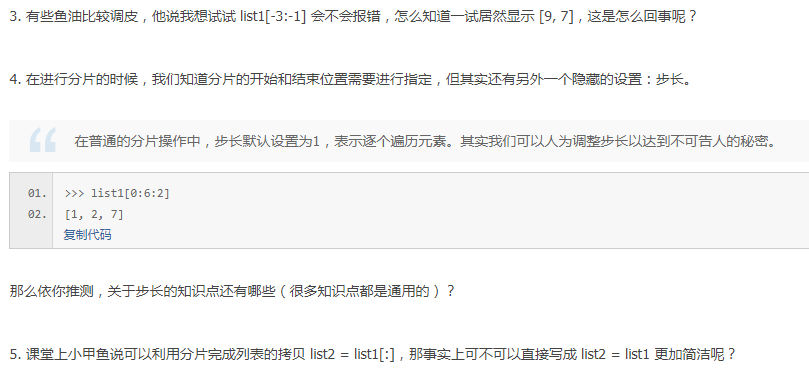
答案
3.列表切片返回还是列表,qiepian = list[起始位置:终止位置:步长],默认起始位置0,默认终止位置-1,python也是支持负数索引的。
4.步长也可以是负数,代表倒着走
5.a = list[:] 与a = list是完全不一样的。切片是拷贝,那么对原list的改变将不会影响到切片。=是指向同一个list,共进退。
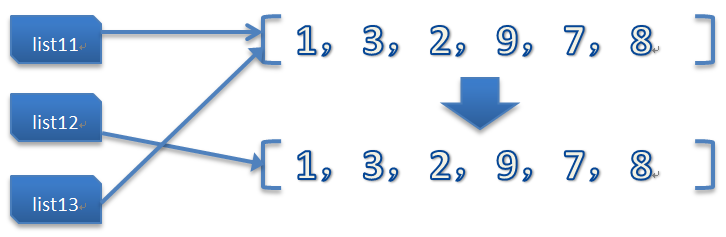
12篇【列表】
答案
0.吃惊的是new并没有和old共进退
1.索引的索引 list[1][2][0]=‘小鱿鱼’
2.sort
3.先sort后reverse或者sort(reverse=True)
4.copy和切片全拷贝一样的,clear是清空列表,但列表仍然存在只是是空list,[]而已。
5.列表推导式(List comprehensions)也叫列表解析,灵感取自函数式编程语言 Haskell。Ta 是一个非常有用和灵活的工具,可以用来动态的创建列表,语法如:[有关A的表达式 for A in B]
> list1 = [(x, y) for x in range(10) for y in range(10) if x%2==0 if y%2!=0]
>
- list1 = []
- for x in range(10):
- for y in range(10):
- if x%2 == 0:
- if y%2 != 0:
- list1.append((x, y))
6.list3 = [name + ':' + slogan[2:] for slogan in list1 for name in list2 if slogan[0] == name[0]] 【先写出来普通写法再转换吧】
13篇【元组】 答案
答案
0.列表list以方括号为标志,内容可修改,元素可多样的集装箱。元组tuple以逗号为标志,内容不可修改,元素可多样的静态元素。
1.a = ('xhj','love','tyj',1314) 我不希望他会改变。
2.列表哈哈,因为他更丰富。(我的答案?两个都不要了,我不会游泳)
3.如图,元组只能使用count和index方法。
4.元组只有一个元素的时候。如a=(1,)这个时候a是元组,否则如a=(1)这个a就是int类型的了。
5.不是,这个是分别赋值,等同于x=1,y=2,z=3。但h = x,y,z的话,h是元组。
6.1)列表,2)列表(因为我想改名),3)列表,4)元组,5)元组(人命关天),6)列表
7.没有,python有列表推到式就够用了。
14篇【字符串:内置函数】

答案
1.在不赋值的情况下,通常用于跨越多行的注释
2.因为其中\t,\r都是转义字符,要么\\要么/,或者用r“...\....”,r代表不转义。
3.索引切片
15篇【字符串:格式化】
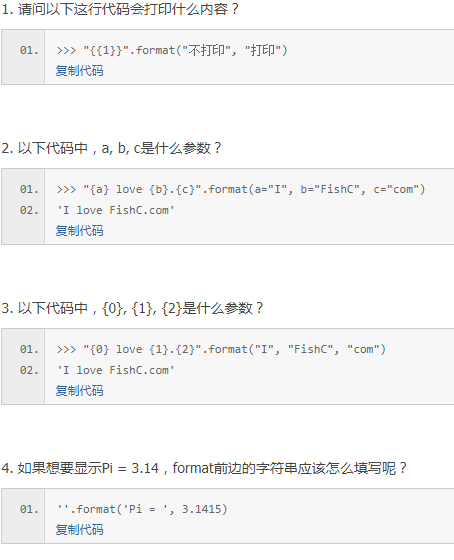
答案
1.打印{1},这里{1}已经解释为1了。正确的写法是‘{0}’.format('不打印'),或者‘{1}’.format('打印'),或者‘{0},{1}’.format('不打印','打印')。
2.关键字参数
3.位置参数
4. '{0}{1:.2f}'.format('Pi = ', 3.1415) 输出'Pi = 3.14'。其中0代表第一个元素,1代表第二个元素,.2f代表小数点后两位。
16篇【序列】
答案
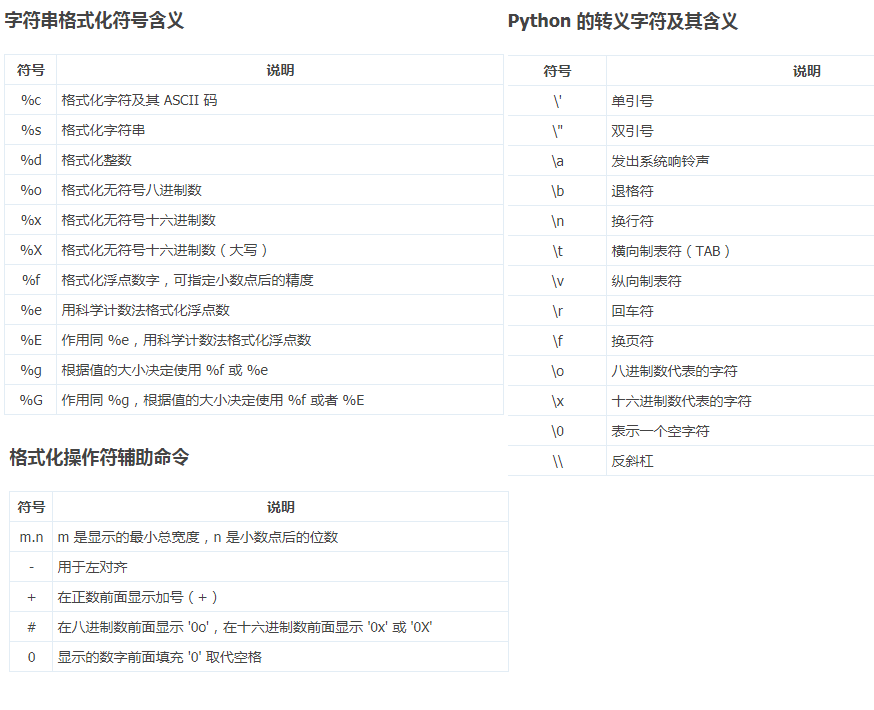
格式化输出,可以用位置参数也可以用关键字参数,如果想要混用,那需要位置参数在关键字参数前。
17篇【函数】
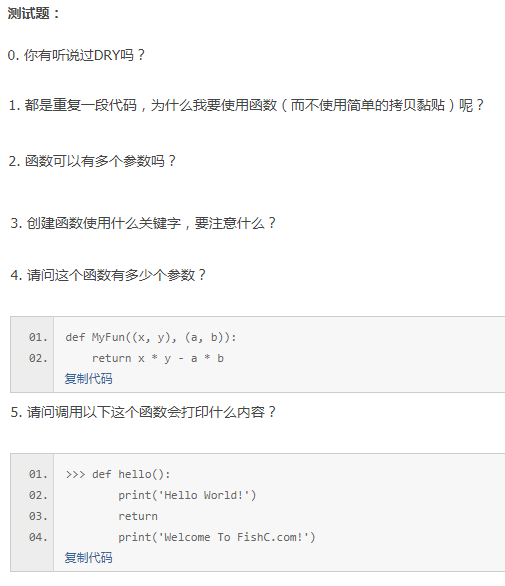
答案
0.DRY 是程序员们公认的指导原则:Don't Repeat Yourself. 拿起函数,不要再去重复拷贝一段代码了!
1.函数优点:
- 可以降低代码量(调用函数只需要一行,而拷贝黏贴需要N倍代码)
- 可以降低维护成本(函数只需修改def部分内容,而拷贝黏贴则需要每一处出现的地方都作修改)
- 使序更容易阅读
2.0个或任意多个
3.def,要注意函数名后边要加上小括号 “()”,然后小括号后边是冒号 “:”,然后缩进部分均属于函数体的内容
4.如果你回答两个,那么恭喜你错啦,答案是 0,因为类似于这样的写法是错误的!分析下,函数的参数需要的是变量,而这里你试图用“元祖”的形式来传递是不可行的。
5.Hello World! 因为当 Python 执行到 return 语句的时候,Python 认为函数到此结束,需要返回了(尽管没有任何返回值,也要返回)。
18篇【函数】
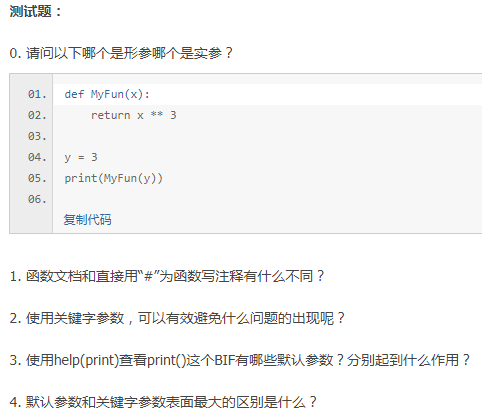
答案
0.x是形参,y是实参
1.函数文档和#都可以为函数写注释,但不同的是,函数文档是作为函数的一部分被存储起来的,可以被打印出来。如,

可以用 MyFirstFunction.__doc__ 或者 help(MyFirstFunction) 输出函数文档。
2.关键字参数可以避免位置安排不当造成的误会和错误。
3.sep是各个输出元素之间的分隔方式,end是输出内容以什么样的字符串结尾,file是文件类型对象,flush是是否强制刷新流,它们都有默认值。

4.默认参数为了避免忘记赋值,关键字参数为了避免位置误会。
19篇【函数】
答案
0.我在next()函数里...
我在pre()函数里...
1.有,python任一函数都有返回值,如果没有写,那就返回N。
2.python函数可以用元组或者列表的方式返回多个类型不同的返回值。
3.1314520 因为函数内部并没有使用全局var,python的保护机制重新创建了一个局部相同名字的var变量。
4.Baby I love you
20篇【函数:内嵌函数和闭包】
答案
21篇【函数:lambda】
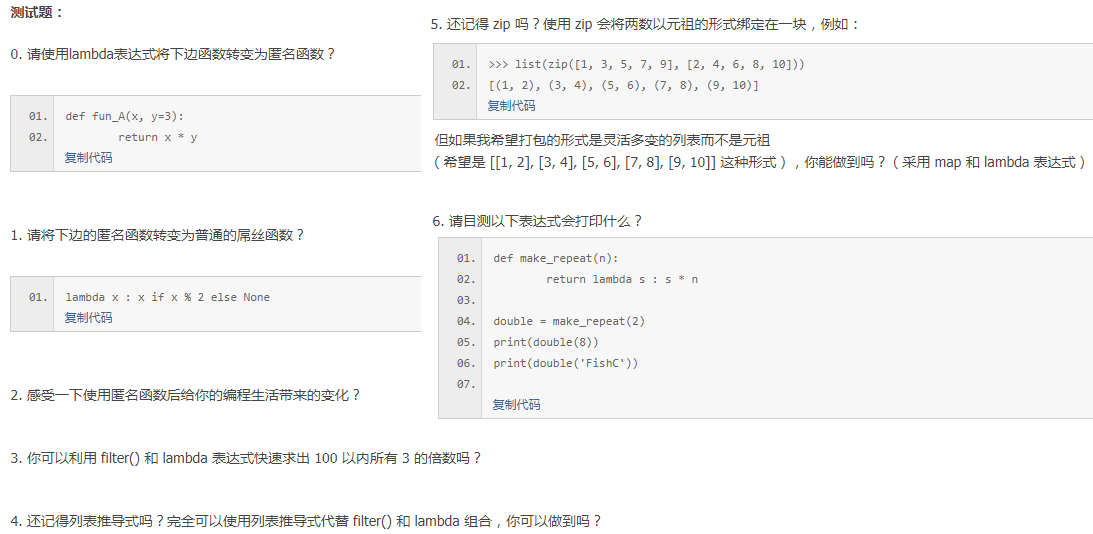
答案
0.g = lambda x,y=3 :x*y g(2)
1.def wc(x):
if x % 2 == 1:
return x
2.语句变短了,可以不用想用什么函数名了,但是我觉得lambda更难。
3.语法含义: lambdax:y 中x是参数,y是规则。filter(x,y)中x是规则,y是参数。list(filter(lambda x : x%3==0,range(100)))
4.? [ i for i in range(1, 100) if not(i%3)]
5. ? list(map(lambda x, y : [x, y], [1, 3, 5, 7, 9], [2, 4, 6, 8, 10]))
6.16 和 FishCFishC
22、23、24篇【函数:递归】
答案
25篇 【字典】
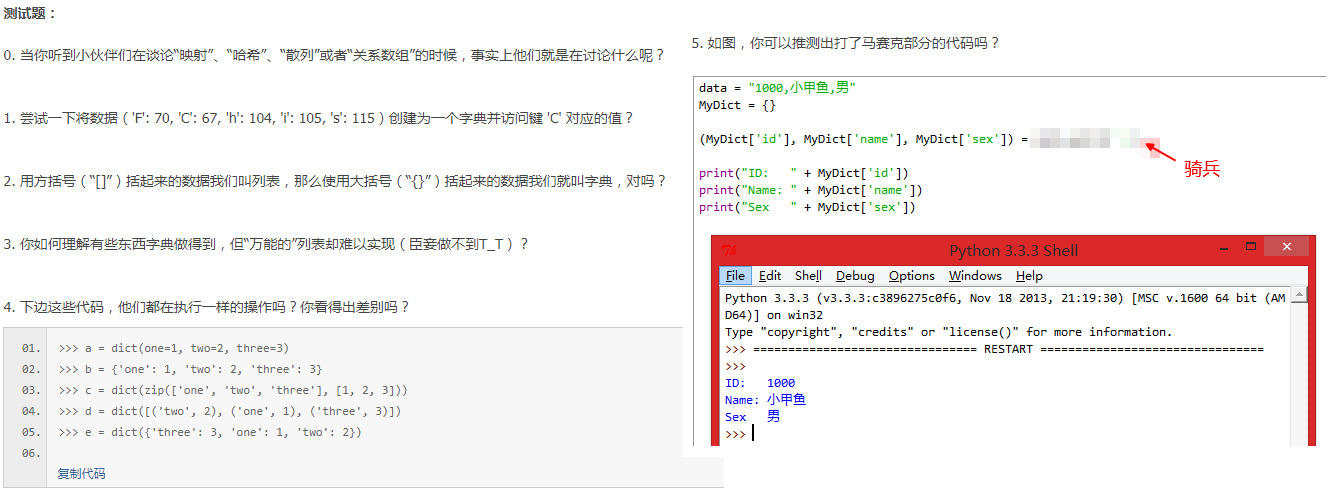 答案
答案
0.字典,因为都是一个概念(why?)
1.MyDict = dict((('F', 70), ('i',105), ('s',115), ('h',104), ('C',67)))
MyDict_2 = {'F':70, 'i':105, 's':115, 'h':104, 'C':67}
3.没有的元素,字典可以赋默认值。另外字典对于对应关系的处理更方便。
4.没区别
5字符串的分割方法 data.split(',')
26篇 【字典】
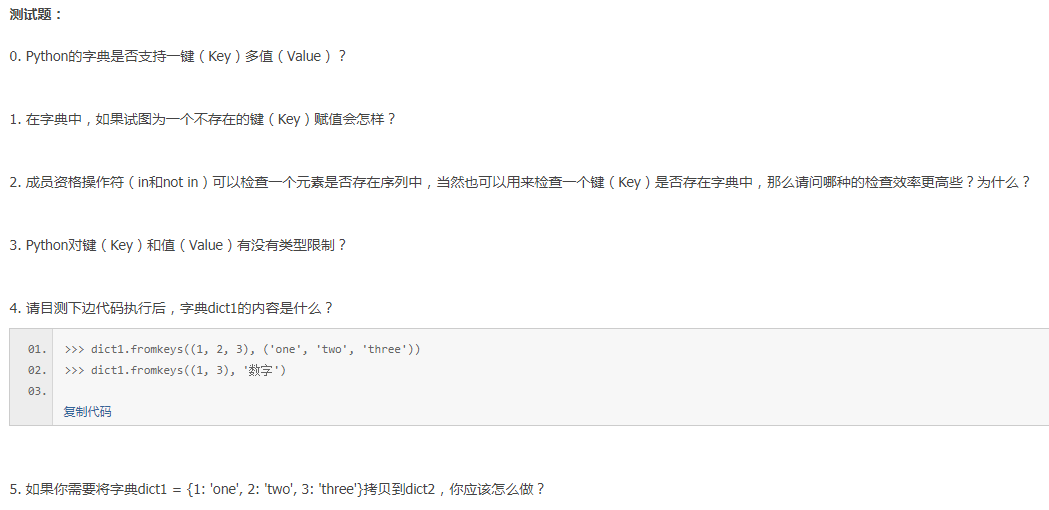
答案
0.不支持,会覆盖上一次的值。
1.会自动创建对应的键(Key)并添加相应的值(Value)进去
2.在字典中检查键(Key)是否存在比在序列中检查指定元素是否存在更高效。因为字典的原理是使用哈希算法存储,一步到位,不需要使用查找算法进行匹配,因此时间复杂度是O(1),效率非常高。
3.Python字典种,对键的要求相对要严格一些,要求它们必须是可哈希(Hash)的对象,不能是可变类型(包括变量、列表、字典本身等)。但是Python对值是没有任何限制的,它们可以是任意的Python对象。
4.执行完成后,字典dict1的内容是:{1: '数字', 3: '数字'},fromkeys用来创建新的字典,注意对原有字典修改时会完全覆盖。
5.copy是值复制,=是拷贝引用。dic1 = dic.copy() dic2 = dic这其中dic改变不会引起dic1的改变,会引起dic2的改变。
27篇【集合】
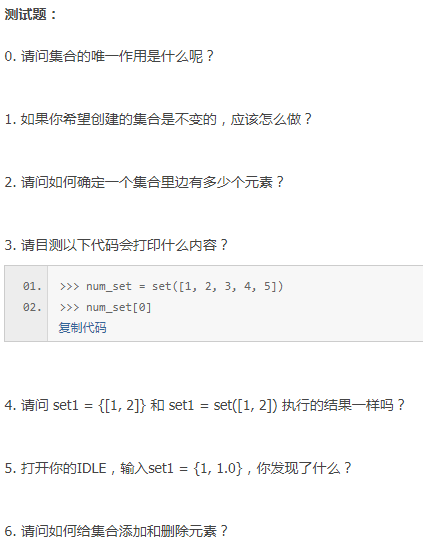
答案
0.保证元素的唯一性
1.frozenset冻结
2.调用__len__()内置函数,或者len(集合名)
3.set集合是无序的,所以无法从下标获取数据
4.set1 = set([1, 2]) 会生成一个集合{1, 2},但set1 = {[1, 2]}却会报错。列表不是可哈希类型,是可变的,因此不能作为集合元素。集合和字典一样都是无序的,都要求元素是可哈希的(字典是要求key)。
5.使用add()方法可以为集合添加元素,使用remove()方法可以删除集合中已知的元素。
28篇【文件】
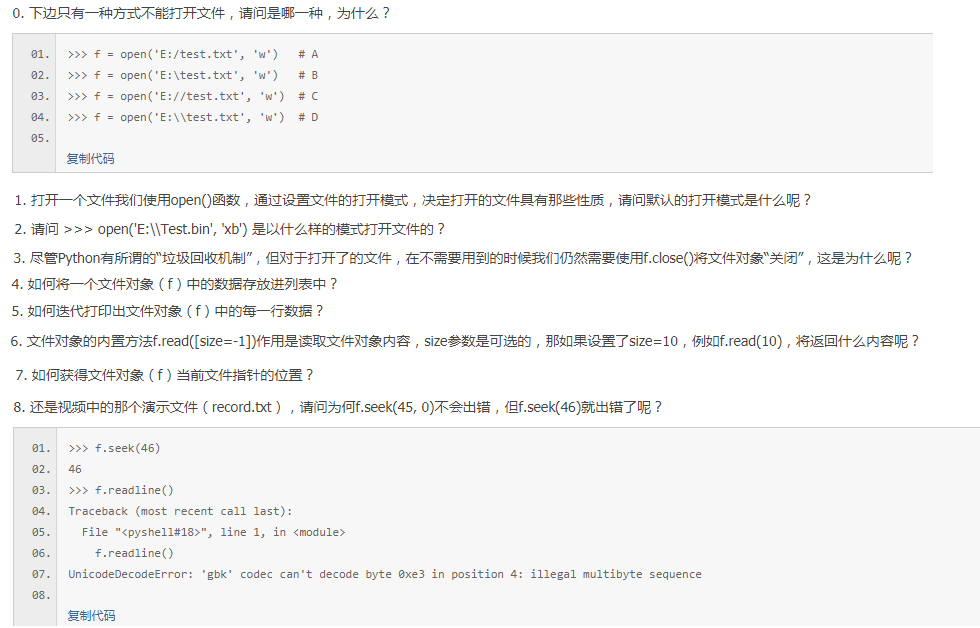
答案
0.B,因为没转义
1.open()函数默认的打开模式是'rt',即可读、文本的模式打开。t 代表文本。
2.b二进制方法,x可写入。要注意的是'x'和'w'均是以“可写入”的模式打开文件,但以'x'模式打开的时候,如果路径下已经存在相同的文件名,会抛出异常,而'w'模式的话会直接覆盖同名文件。
3.否则操作结果就还在缓冲中,如果断电没有保存在硬盘上就惨了。
4.list(f)
5.readline方式读取数据,或者 for each_line in f: print(each_line) 以迭代方式读取。
6.返回从文件指针开始(注意这里并不是文件头哦)的连续10个字符,而不是从文件头开始。
7.f.tell()文件当前指针的位置
8.f.seek()定位的文件指针是按字节为单位进行计算的,演示文件(record.txt)是以GBK进行编码的,按照规则,一个汉字需要占用两个字节。f.seek(45)的位置位于字符“小”的开始位置,而f.seek(46)的位置刚好位于字符“小”的中间位置。
------------------29,30,31
32篇【异常处理】
Python标准异常总结【见博客】
33篇【异常处理】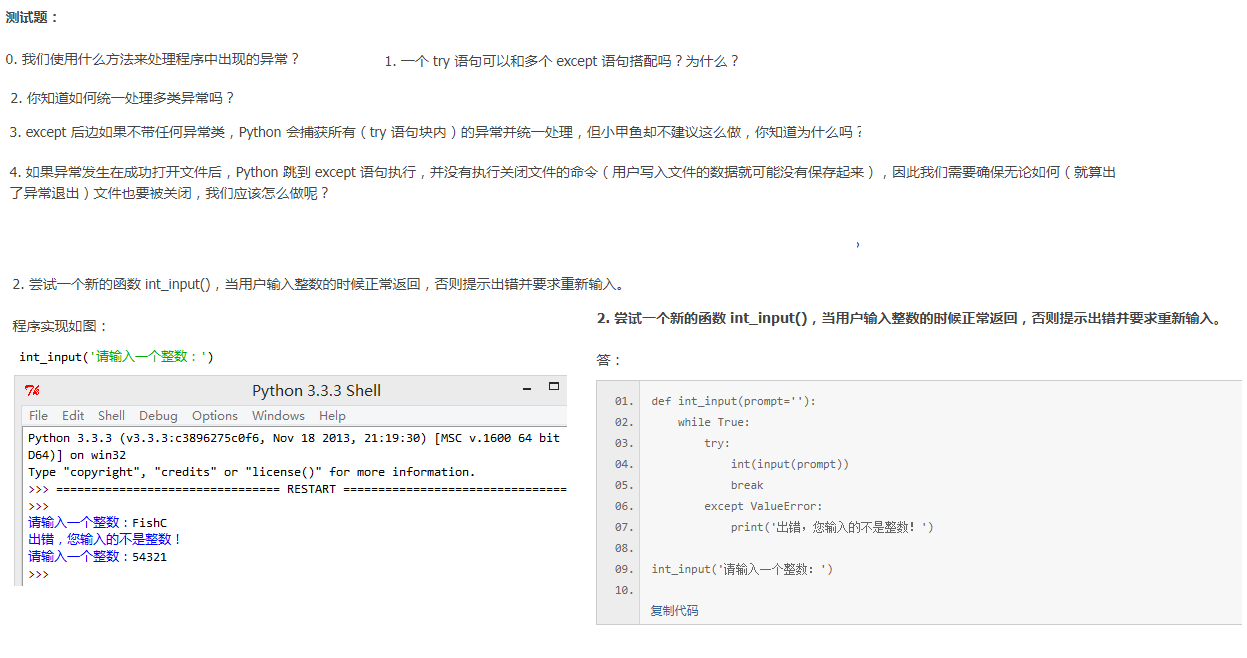
答案
0.
try:
检测范围
except Exception[as reason]:
出现异常(Exception)后的处理代码
1.可以,用来捕捉多种异常错误
try:.......
except OSError as reason:
print('文件出错啦T_T\n错误原因是:' + str(reason))
except TypeError as reason:
print('类型出错啦T_T\n错误原因是:' + str(reason))
2.except (OSError ,TypeError ) as reason: 或 except:
3.不知道还有哪些错误
4.finally或者用with
34篇【ELSE语句】
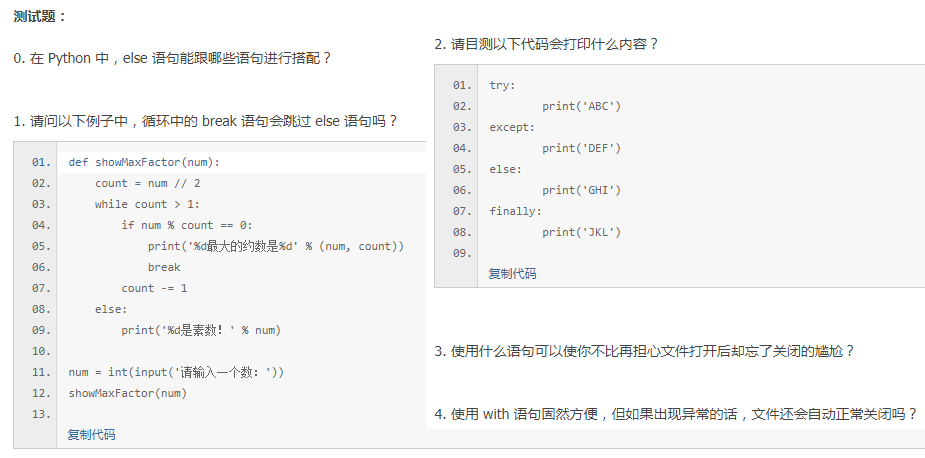
答案
0.else可以和if,for,while,try搭配。和for,while搭配时,“干完了就能else”。和try搭配时,“不出错就能else”。
1.如果没有执行break,就能else
2.ABC - GHI - JKL
3.with
4.会自动关闭
35篇【图形化界面】------ 答案
36篇【类与对象】

答案
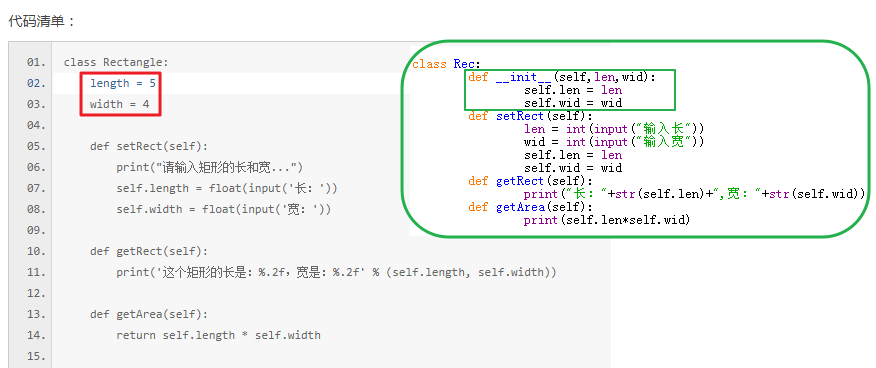 初始化参数的方法
初始化参数的方法
37篇【类与对象】
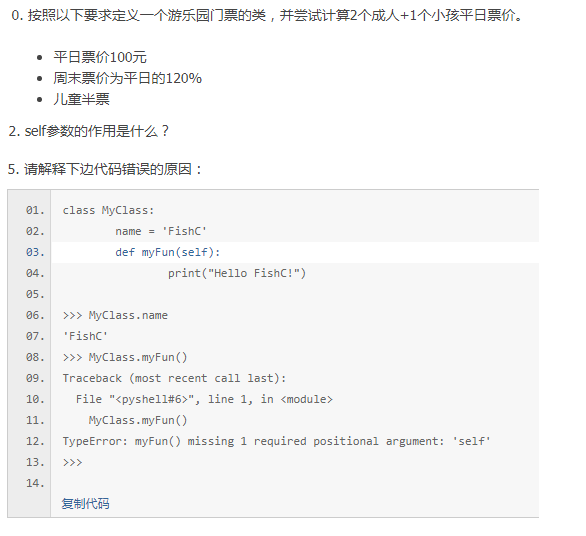
答案
0.

2.self是绑定方法,据说有了这个参数,Python 再也不会傻傻分不清是哪个对象在调用方法了,你可以认为方法中的 self 其实就是实例对象的唯一标志。
5.首先要明白类、类对象、实例对象是三个不同的名词。
我们常说的类指的是类定义,由于“Python无处不对象”,所以当类定义完之后,自然就是类对象。在这个时候,你可以对类的属性(变量)进行直接访问(MyClass.name)。f一个类可以实例化出无数的对象(实例对象),Python 为了区分是哪个实例对象调用了方法,于是要求方法必须绑定(通过 self 参数)才能调用。而未实例化的类对象直接调用方法,因为缺少 self 参数,所以就会报错。
38篇【类和对象】
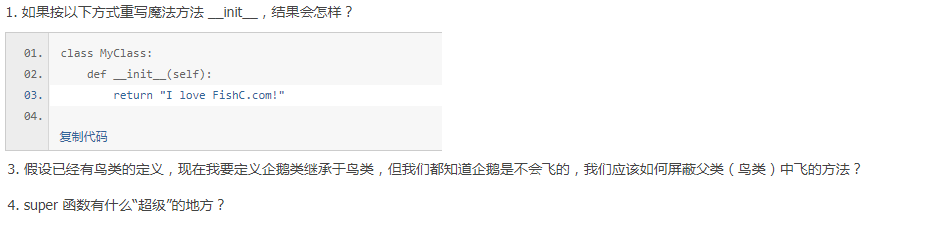
答案
1.报错,__init__返回值是None
3,覆盖父类方法,例如将函数体内容写 pass,这样调用 fly 方法就没有任何反应了

4.super 函数超级之处在于你不需要明确给出任何基类的名字,它会自动帮您找出所有基类以及对应的方法。由于你不用给出基类的名字,这就意味着你如果需要改变了类继承关系,你只要改变 class 语句里的父类即可,而不必在大量代码中去修改所有被继承的方法。
39篇【类与对象】
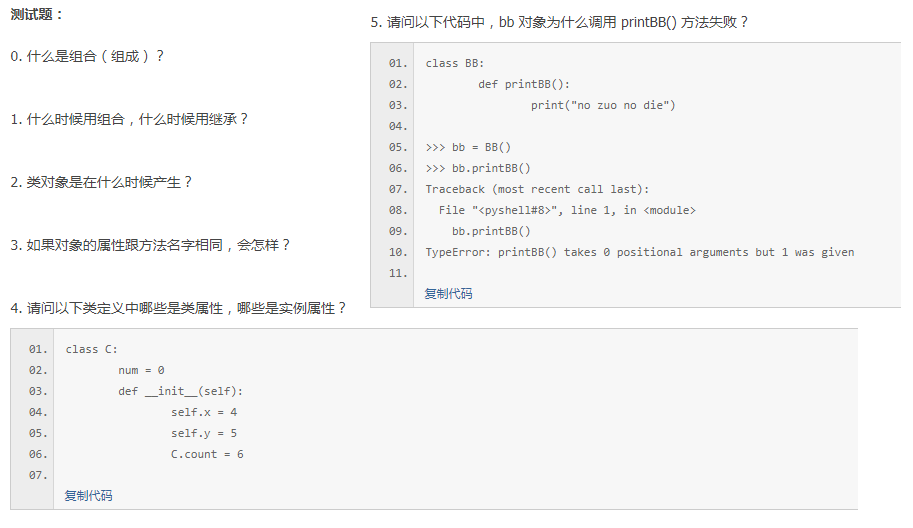
答案
0.继承多个可能会把代码复杂化,所以有时候用组合代替继承。python中,直接在类定义中把需要的类放进去实例化就可以了。
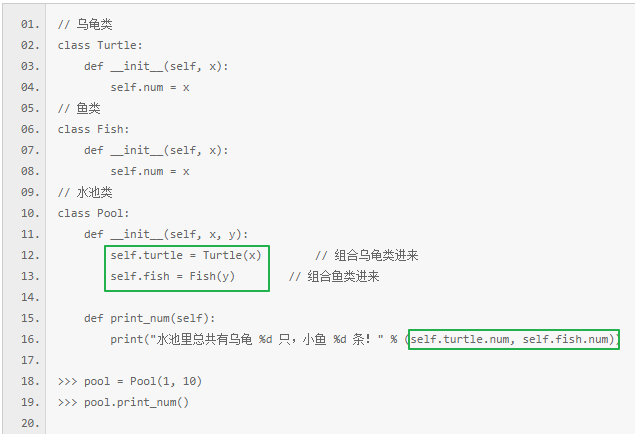
1.组合用于“有一个”的场景中,继承用于“是一个”的场景中
2.当你这个类定义完的时候,类定义就变成类对象,可以直接通过“类名.属性”或者“类名.方法名()”引用或使用相关的属性或方法。
3.如果对象的属性跟方法名相同,属性会覆盖方法。
4.num 和 count 是类属性(静态变量),x 和 y 是实例属性。大多数情况下,你应该考虑使用实例属性,而不是类属性(类属性通常仅用来跟踪与类相关的值)。
5python的绑定概念,要在函数方法的参数中加self
40篇【类和对象】
issubclass(class,classinfo)判断是否是子类
isinstance(object,class)判断是否是实例对象
hasattr(object,name)判断是否有某个属性
getattr(object,name[,default])返回某个属性的值,若没有该属性这返回default
setattr(object,name,value)设置属性
delattr(object,name)删除属性
property允许编程人员轻松、有效地管理属性访问
41篇【魔法方法】

答案
0.魔法方法总是被双下划线包围,例如 __init__
1.__new__ 是在一个对象实例化的时候所调用的第一个方法。它跟其他魔法方法不同,它的第一个参数不是 self 而是这个类(cls),而其他的参数会直接传递给 __init__ 方法的。
2.当我们的实例对象需要有明确的初始化步骤的时候,你可以在 __init__ 方法中部署初始化的代码。
3.编程中需要主要到 __init__ 方法的返回值一定是None
4.__new__ 方法主要任务时返回一个实例对象,通常是参数 cls 这个类的实例化对象,当然你也可以返回其他对象。R
5.如果说 __init__ 和 __new__ 方法是对象的构造器的话,那么 Python 也提供了一个析构器,叫做 __del__ 方法。当对象将要被销毁的时候,这个方法就会被调用。但一定要注意的是,并非 del x 就相当于自动调用 x.__del__(),__del__ 方法是当垃圾回收机制回收这个对象的时候调用的。
0.

42、43篇【魔法方法】
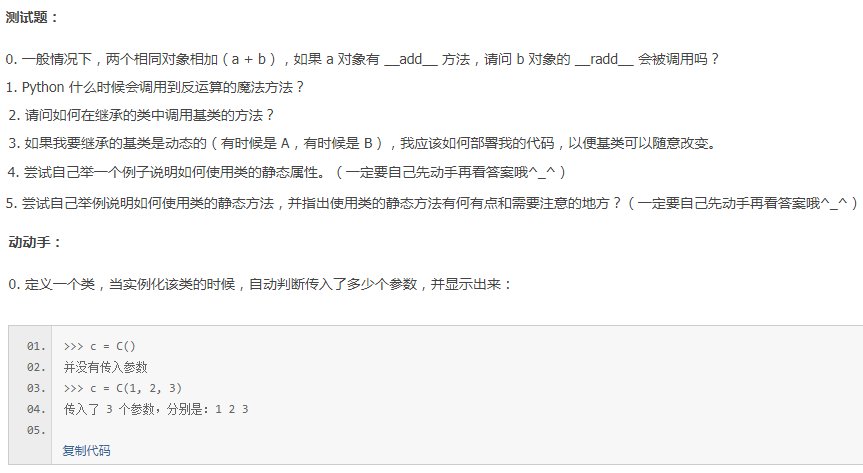
答案
0.不会
1.例如 a + b,如果 a 对象的 __add__ 方法没有实现或者不支持相应的操作,那么 Python 就会自动调用 b 的 __radd__ 方法
2.使用 super() 这个 BIF 函数。

3.可以先为基类定义一个别名,在类定义的时候,使用别名代替你要继承的基类。如此,当你想要改变基类的时候,只需要修改给别名赋值的那个语句即可。

4.类的静态属性很简单,在类中直接定义的变量(没有 self.)就是静态属性。引用类的静态属性使用”类名.属性名”的形式。
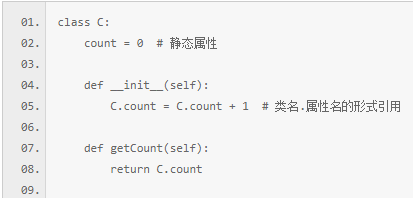
5.静态方法是类的特殊方法,静态方法只需要在普通方法的前边加上 @staticmethod 修饰符即可。静态方法最大的优点是:不会绑定到实例对象上,换而言之就是节省开销。使用的时候需要注意的地方:静态方法并不需要 self 参数,因此即使是使用对象去访问,self 参数也不会传进去。4

0.

44、45篇【魔法方法】

答案
这段代码试图在对象的属性发生赋值操作的时候,将实际的值 +1赋值给相应的属性。但这么写法是错误的,因为每当属性被赋值的时候, __setattr__() 会被调用,而里边的 self.name = value + 1 语句又会再次触发 __setattr__() 调用,导致无限递归。

46篇【魔法方法】
47篇【魔法方法】

答案
0.无疑是列表(List),元组(Tuple)和字符串(String)
1.如果你想要定制一个不可变的容器(像 String),你就不能定义像 __setitem__() 和 __delitem__() 这些会修改容器中的数据的方法 。
2.应该定义 __reversed__() 方法,提供对内置函数 reversed() 的支持。
3.在 Python 中,我们通过 len() 内置函数来查询容器的“容量”,所以容器应该定义 __len__() 方法。
4.读 —— __getitem__(),写 —— __setitem__(),删除 —— __delitem__()
5.在 Python 中,协议更像是一种指南。
48篇【魔法方法-迭代器】
答案
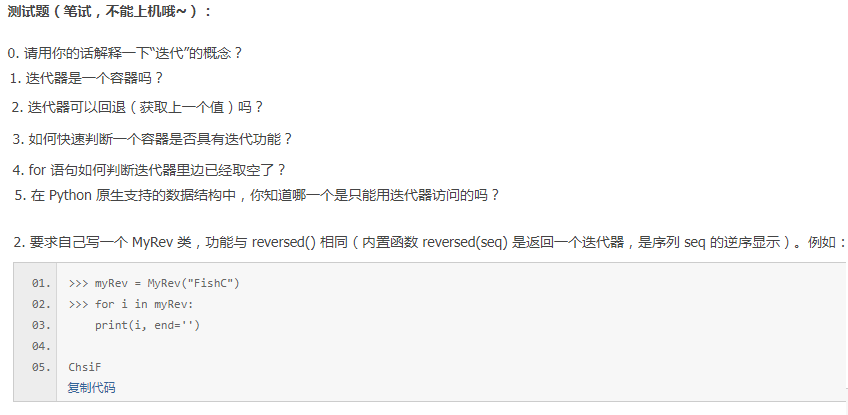
0.迭代器就是一个一个往下取。每一次对过程的重复被称为一次“迭代”,而每一次迭代得到的结果会被用来作为下一次迭代的初始值。
1.迭代器不是容器,是对象。例如将list,string等变成迭代对象。
2.迭代器只能向前,不能回退取值。
3.容器具有迭代功能则能用__iter__和__next__魔法方法
4.try except 如果迭代器到尾了会抛出StopIteration 异常
5.set集合,对于原生支持随机访问的数据结构(如tuple、list),可以使用迭代器或者下标索引的形式访问,但对于无法随机访问的数据结构 set 而言,迭代器是唯一的访问元素的方式。
2.

49篇【生成器】
答案
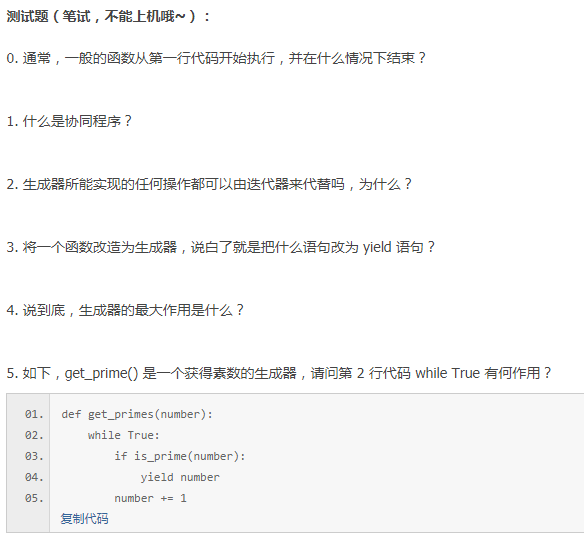
0.普通函数通常在第一行开始,在执行完/return/异常处结束。一旦函数将控制权交还给调用者,就意味着全部结束。函数中做的所有工作以及保存在局部变量中的数据都将丢失。如果再次调用这个函数时,一切都将重新开始。?]{Vne
1.所谓的协同程序就是可以运行的独立函数调用,函数可以暂停或者挂起,并在需要的时候从程序离开的地方继续或者重新开始。Python 是通过生成器来实现类似于协同程序的概念:生成器可以暂时挂起函数,并保留函数的局部变量等数据,然后在再次调用它的时候,从上次暂停的位置继续执行下去。
2.是的,因为生成器事实上就是基于迭代器来实现的,生成器只需要一个 yield 语句即可,但它内部会自动创建 __iter__() 和 __next__() 方法
3.return改为yield,这样下次直接从yield继续执行
4.保存现场,当下一次执行该函数是从上一次结束的地方开始,而不是重头再来。
5. while True 循环是用来确保生成器函数永远也不会执行到函数末尾的
