Mit6.S081笔记:知识点记录
程序到汇编的转换
任何一个处理器都有一个关联的ISA(Instruction Sets Architecture,指令集架构),ISA就是处理器能够理解的指令集。每一条指令都有一个对应的二进制编码或者一个Opcode。当处理器在运行时,如果看见了这些编码,那么处理器就知道该做什么样的操作。
写好的C程序需要被编译成汇编语言,汇编语言会被翻译成二进制文件也就是.obj或者.o文件。
汇编语言不具备C语言的组织结构,在汇编语言中只能看到一行行的指令,比如add,mult等等。汇编语言中没有很好的控制流程,没有循环(但是有基于lable的跳转),虽然有函数但是与C语言函数不太一样,汇编语言中的函数是以label的形式存在而不是真正的函数定义。汇编语言是一门非常底层的语言,许多其他语言,比如C++,都会编译成汇编语言。运行任何编译型语言之前都需要先生成汇编语言
汇编语言有很多种,不同的处理器指令集不一样,而汇编语言中都是一条条指令,所以不同处理器对应的汇编语言必然不一样。
寄存器
寄存器是CPU或者处理器上,预先定义的可以用来存储数据的位置。寄存器之所以重要是因为汇编代码并不是在内存上执行,而是在寄存器上执行,也就是说,在做add,sub时,其实是对寄存器进行操作。所以通常看到的汇编代码中的模式是,通过load将数据存放在寄存器中(这里的数据源可以是来自内存,也可以来自另一个寄存器),之后在寄存器上执行一些操作。如果对操作的结果关心的话,会将操作的结果store在某个地方。这里的目的地可能是内存中的某个地址,也可能是另一个寄存器。寄存器是用来进行任何运算和数据读取的最快的方式。
栈
栈使得函数变得有组织,且能够正常返回。下面是一个非常简单的栈的结构图,其中每一个区域都是一个Stack Frame,每执行一次函数调用就会产生一个Stack Frame
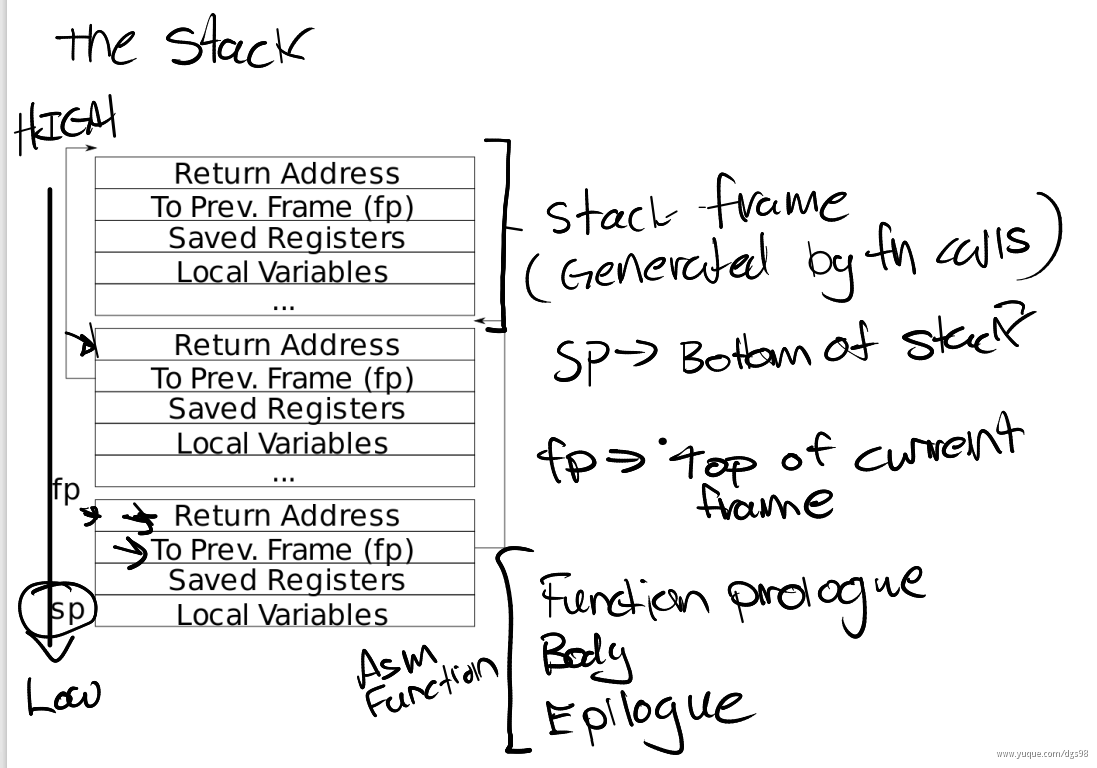
每一次调用一个函数,函数都会为自己创建一个Stack Frame,并且只给自己用。函数通过移动Stack Pointer来完成Stack Frame的空间分配
对于Stack来说,是从高地址开始向低地址使用。所以栈总是向下增长。当想要创建一个新的Stack Frame的时候,总是对当前的Stack Pointer做减法。一个函数的Stack Frame包含了保存的寄存器,本地变量,并且,如果函数的参数多于8个,额外的参数会出现在Stack中。所以Stack Frame大小并不总是一样,即使在这个图里面看起来是一样大的。不同的函数有不同数量的本地变量,不同的寄存器,所以Stack Frame的大小是不一样的。但是有关Stack Frame有两件事情是确定的:
- Return address总是会出现在Stack Frame的第一位
- 指向前一个Stack Frame的指针也会出现在栈中的固定位置
有关Stack Frame中有两个重要的寄存器,第一个是SP(Stack Pointer),它指向Stack的底部并代表了当前Stack Frame的位置。第二个是FP(Frame Pointer),它指向当前Stack Frame的顶部。因为Return address和指向前一个Stack Frame的的指针都在当前Stack Frame的固定位置,所以可以通过当前的FP寄存器寻址到这两个数据
保存前一个Stack Frame的指针的原因是为了能跳转回去。所以当前函数返回时,我们可以将前一个Frame Pointer存储到FP寄存器中。所以使用Frame Pointer来操纵Stack Frames,并确保总是指向正确的函数。
Stack Frame必须要被汇编代码创建,所以是编译器生成了汇编代码,进而创建了Stack Frame。所以通常,在汇编代码中,函数的最开始可以看到Function prologue,之后是函数的本体,最后是Epilogue。这就是一个汇编函数通常的样子
结构体
struct在内存中是一段连续的地址,可以认为struct像是一个数组,但是里面的不同字段的类型可以不一样
Trap机制
每当
- 程序执行系统调用
- 程序出现了类似page fault、运算时除以0的错误
- 一个设备触发了中断使得当前程序运行需要响应内核设备驱动
都会发生用户空间和内核空间的切换,这种切换通常被称为trap。很多应用程序,要么因为系统调用,要么因为page fault,都会频繁的切换到内核中。
需要清楚如何让程序的运行,从只拥有user权限并且位于用户空间的程序,切换到拥有supervisor权限的内核。在这个过程中,硬件的状态将会非常重要,因为很多的工作都是将硬件从适合运行用户应用程序的状态,改变到适合运行内核代码的状态
用户应用程序可以使用全部的32个寄存器,很多寄存器都有特殊的作用。其中
- 在硬件中还有一个寄存器叫做程序计数器(Program Counter Register)
- 表明当前mode的标志位,这个标志位表明了当前是supervisor mode还是user mode
- 还有一堆控制CPU工作方式的寄存器,比如SATP(Supervisor Address Translation and Protection)寄存器,包含了指向page table的物理内存地址
- STVEC(Supervisor Trap Vector Base Address Register)寄存器,指向了内核中处理trap的指令的起始地址
- SEPC(Supervisor Exception Program Counter)寄存器,在trap的过程中保存程序计数器的值
- SSCRATCH(Supervisor Scratch Register)寄存器,这也是个非常重要的寄存器
这些寄存器表明了执行系统调用时计算机的状态
在trap处理的过程中需要更改一些状态,或者对状态做一些操作。这样才可以运行系统内核中普通的C程序。先来预览一下需要做的操作:
- 首先需要保存32个用户寄存器。因为很显然我们需要恢复用户应用程序的执行,尤其是当用户程序随机的被设备中断所打断时。我们希望内核能够响应中断,之后在用户程序完全无感知的情况下再恢复用户代码的执行。所以这意味着32个用户寄存器不能被内核弄乱。但是这些寄存器又要被内核代码所使用,所以在trap之前必须先在某处保存这32个用户寄存器
- 程序计数器也需要在某个地方保存,它几乎跟一个用户寄存器的地位是一样的,需要能够在用户程序运行中断的位置继续执行用户程序
- 需要将mode改成supervisor mode,因为需要使用内核中的各种各样的特权指令
- SATP寄存器现在正指向user page table,而user page table只包含了用户程序所需要的内存映射和一两个其他的映射,它并没有包含整个内核数据的内存映射。所以在运行内核代码之前,需要将SATP指向kernel page table
- 需要将堆栈寄存器指向位于内核的一个地址,因为需要一个堆栈来调用内核的C函数
- 一旦设置好了,并且所有的硬件状态都适合在内核中使用, 需要跳入内核的C代码
一旦运行在内核的C代码中,那就跟平常的C代码是一样的。
不能让用户代码介入到这里的user/kernel切换,否则有可能会破坏安全性。所以这意味着,trap中涉及到的硬件和内核机制不能依赖任何来自用户空间东西。比如不能依赖32个用户寄存器,它们可能保存的是恶意的数据,所以,XV6的trap机制不会查看这些寄存器,而只是将它们保存起来。
Trap代码执行流程
用户程序执行系统调用函数(实际上通过执行ECALL指令来执行系统调用)
用户程序 → ECALL → uservec(在trampoline中) → usertrap(在trap.c中) → syscall → sys_xxx(对应的系统调用) →执行结果返回给syscall → usertrapret(在trap.c中) → userret(在trampoline中) → 系统调用完成,返回到用户空间,恢复ECALL之后的用户程序的执行
ECALL
shell调用write为例。作为用户代码的Shell调用write时,实际上调用的是关联到Shell的一个库函数,在usys.s,首先将SYS_write加载到a7寄存器(SYS_write映射常量16,表示第16个系统调用,即write),之后这个函数中执行ecall指令(此时进入了supervisor mode)
ecall指令会让程序计数器跳转到用户空间顶部trampoline page的位置,所以现在指令正运行在内存的trampoline page中,这个page包含了内核的trap处理代码。ecall并不会切换page table,这是ecall指令的一个非常重要的特点。所以这意味着,trap处理代码必须存在于每一个user page table中。因为ecall并不会切换page table,我们需要在user page table中的某个地方来执行最初的内核代码。而这个trampoline page,是由内核小心的映射到每一个user page table中,以使得当我们仍然在使用user page table时,内核在一个地方能够执行trap机制的最开始的一些指令
所有进程的 trampoline page 都映射到同一个物理地址
这里的控制是通过STVEC寄存器完成的,这是一个只能在supervisor mode下读写的特权寄存器。在从用户空间进入到内核空间之前,内核会设置好STVEC寄存器指向内核希望trap代码运行的位置,这就是trampoline page的起始位置。STVEC寄存器的内容,就是在ecall指令执行之后,我们会在这个特定地址执行指令的原因
即使trampoline page是在用户地址空间的user page table完成的映射,但用户代码并不能写它,因为这些page对应的PTE并没有设置PTE_U标志位
我们是通过ecall走到trampoline page的,而ecall实际上只会改变三件事情:
第一,ecall将代码从user mode改到supervisor mode
第二,ecall将程序计数器的值保存在了SEPC寄存器
第三,ecall会将STVEC拷贝到程序计数器,也就是程序开始执行STVEC所指向的代码,即trampoline page的位置
uservec函数
现在程序位于trampoline page的起始,也是uservec函数的起始,现在需要做的第一件事情就是保存寄存器的内容。在一些其他的机器中或许直接就将32个寄存器中的内容写到物理内存中某些合适的位置。但是不能在RISC-V中这样做,因为在RISC-V中,supervisor mode下的代码不允许直接访问物理内存,所以只能使用page table中的内容
对于保存用户寄存器,XV6在RISC-V上的实现包括了两个部分。第一个部分是,XV6在每个user page table映射了trapframe page,这样每个进程都有自己的trapframe page。这个page包含了很多有趣的数据,但是现在最重要的数据是用来保存用户寄存器的32个空槽位。所以,在trap处理代码中,user page table有一个之前由kernel设置好的映射关系,这个映射关系指向了一个可以用来存放这个进程的用户寄存器的内存位置。所以,如何保存用户寄存器的第一个部分是,内核非常方便的将trapframe page映射到了每个user page table
另一部分在于之前提过的SSCRATCH寄存器。这个由RISC-V提供的SSCRATCH寄存器,就是为接下来的目的而创建的。在进入到user space之前,内核会将trapframe page的地址保存在这个寄存器中。更重要的是,RISC-V有一个指令允许交换任意两个寄存器的值。而SSCRATCH寄存器的作用就是保存另一个寄存器的值,并将自己的值加载给另一个寄存器
trampoline.S代码要做的第一件事就是执行csrrw指令,这个指令交换了a0和sscratch两个寄存器的内容。这样,a0寄存器保存的就是trapframe page的地址,sscratch寄存器保存的就是原本a0寄存器的值。这样就可以通过a0寄存器指向的trapframe page的地址保存其他用户寄存器的数据。
......# 上面是保存寄存器数据
# save the user a0 in p->trapframe->a0
csrr t0, sscratch
sd t0, 112(a0)
# restore kernel stack pointer from p->trapframe->kernel_sp
ld sp, 8(a0)
# make tp hold the current hartid, from p->trapframe->kernel_hartid
ld tp, 32(a0)
# load the address of usertrap(), p->trapframe->kernel_trap
ld t0, 16(a0)
# restore kernel page table from p->trapframe->kernel_satp
ld t1, 0(a0)
csrw satp, t1
sfence.vma zero, zero
# a0 is no longer valid, since the kernel page
# table does not specially map p->tf.
# jump to usertrap(), which does not return
jr t0
保存其他寄存器的数据后,还需要保存a0寄存器原本的数据(此时是存在sscratch寄存器中)。在汇编代码中,先执行了csrr t0, sscratch,从sscratch中读取值,并存储到t0寄存器中。然后执行sd t0, 112(a0),将t0寄存器的值存储到a0寄存器指向的内存地址的偏移量为112的位置(此时a0指向的是trapframe page)。这样trapframe page中就备份好了所有寄存器的数据。
下一句指令是ld sp, 8(a0),这条指令将a0指向的内存地址往后数的第8个字节开始的数据加载到Stack Pointer寄存器(反复强调一下,此时a0指向的是trapframe page)。第8个字节开始的数据是内核的Stack Pointer(kernel_sp)。trapframe中的kernel_sp是由kernel在进入用户空间之前就设置好的,它的值是这个进程的kernel stack。所以这条指令的作用是初始化Stack Pointer指向这个进程的kernel stack的最顶端
下一条指令是ld tp, 32(a0),向tp寄存器写入数据。在RISC-V中,没有一个直接的方法来确认当前运行在多核处理器的哪个核上,XV6会将CPU核的编号也就是hartid保存在tp寄存器
下一条指令是ld t0, 16(a0),向t0寄存器写入数据。这里写入的是将要执行的第一个C函数的指针,也就是函数usertrap的指针,在后面会使用这个指针
下一条指令是ld t1, 0(a0),向t1寄存器写入数据,写入的是kernel page table的地址。实际上严格来说,t1的内容并不是kernel page table的地址,是需要向SATP寄存器写入的数据。它包含了kernel page table的地址,但是移位了,并且包含了各种标志位。下一条指令是交换SATP和t1寄存器。这条指令执行完成之后,当前程序会从user page table切换到kernel page table。
现在,Stack Pointer指向了kernel stack;有了kernel page table,可以读取kernel data,已经准备好了执行内核中的C代码了
为什么代码没有崩溃?毕竟我们在内存中的某个位置执行代码,程序计数器保存的是虚拟地址,如果切换了page table,为什么同一个虚拟地址不会通过新的page table寻址走到一些无关的page中?
因为现在还在trampoline代码中,而trampoline代码在用户空间和内核空间都映射到了同一个地址。
trampoline page在user page table中的映射与kernel page table中的映射是完全一样的。这两个page table中其他所有的映射都是不同的,只有trampoline page的映射是一样的,因此在切换page table时,寻址的结果不会改变,实际上就可以继续在同一个代码序列中执行程序而不崩溃。这是trampoline page的特殊之处,它同时在user page table和kernel page table都有相同的映射关系
最后一条指令是jr t0。执行了这条指令,就要从trampoline跳到内核的C代码中。这条指令的作用是跳转到t0指向的函数中,即usertrap函数
usertrap函数
void
usertrap(void)
{
int which_dev = 0;
if((r_sstatus() & SSTATUS_SPP) != 0)
panic("usertrap: not from user mode");
// send interrupts and exceptions to kerneltrap(),
// since we're now in the kernel.
w_stvec((uint64)kernelvec);
struct proc *p = myproc();
// save user program counter.
p->trapframe->epc = r_sepc();
if(r_scause() == 8){
// system call
if(p->killed)
exit(-1);
// sepc points to the ecall instruction,
// but we want to return to the next instruction.
p->trapframe->epc += 4;
// an interrupt will change sstatus &c registers,
// so don't enable until done with those registers.
intr_on();
syscall();
} else if((which_dev = devintr()) != 0){
// ok
}else {
printf("usertrap(): unexpected scause %p pid=%d\n", r_scause(), p->pid);
printf(" sepc=%p stval=%p\n", r_sepc(), r_stval());
p->killed = 1;
}
if(p->killed)
exit(-1);
// give up the CPU if this is a timer interrupt.
if(which_dev == 2)
yield();
usertrapret();
}
usertrap函数位于trap.c。有很多原因都可以让程序运行进入到usertrap函数中来,比如系统调用,运算时除以0,使用了一个未被映射的虚拟地址,或者是设备中断。usertrap某种程度上存储并恢复硬件状态,但是它也需要检查触发trap的原因,以确定相应的处理方式
usertrap做的第一件事情是更改STVEC寄存器。取决于trap是来自于用户空间还是内核空间,实际上XV6处理trap的方法是不一样的。目前为止,我们只讨论过当trap是由用户空间发起时会发生什么。如果trap从内核空间发起,将会是一个非常不同的处理流程,因为从内核发起的话,程序已经在使用kernel page table。所以当trap发生时,程序执行仍然在内核的话,很多处理都不必存在
在内核中执行任何操作之前,usertrap中先将STVEC指向了kernelvec变量,这是内核空间trap处理代码的位置,而不是用户空间trap处理代码的位置
我们需要知道当前运行的是什么进程,可以通过调用myproc函数来做到这一点。myproc函数会查找一个根据当前CPU核的编号索引的数组,CPU核的编号是hartid,这是myproc函数找出当前运行进程的方法
接下来要保存用户程序计数器,它虽然已经保存在SEPC寄存器中,但是可能发生这种情况:当程序还在内核中执行时,由于进程调度可能切换到另一个进程,并进入到那个程序的用户空间,然后那个进程可能再调用一个系统调用进而导致SEPC寄存器的内容被覆盖。所以,我们需要保存当前进程的SEPC寄存器到一个与该进程关联的内存中,这样这个数据才不会被覆盖。这里使用trapframe来保存这个程序计数器:struct proc *p = myproc();
接下来需要找出现在会在usertrap函数的原因: if(r_scause() == 8)。根据触发trap的原因,RISC-V的SCAUSE寄存器会有不同的数字(比如8表示系统调用)。接下来检查是不是有其他的进程杀掉了当前进程:if(p->killed)
p->trapframe->epc += 4;在RISC-V中,存储在SEPC寄存器中的程序计数器,是用户程序中触发trap的指令的地址。但是恢复用户程序时,我们希望在下一条指令恢复,也就是ecall之后的一条指令。所以对于系统调用,对于保存的用户程序计数器加4,这样会在ecall的下一条指令恢复,而不是重新执行ecall指令
intr_on();XV6会在处理系统调用的时候使能中断,这样中断可以更快的服务,有些系统调用需要许多时间处理。中断总是会被RISC-V的trap硬件关闭,所以在这个时间点,需要显式的打开中断
syscall();调用syscall函数,从syscall表单中,根据系统调用的编号查找相应的系统调用函数,syscall函数的工作就是获取由trampoline代码保存在trapframe中a7的数字,然后用这个数字索引实现了每个系统调用的表单。系统调用需要找到它们的参数,通过trapframe来获取这些参数。所有的系统调用都有一个返回值,比如write会返回实际写入的字节数,而RISC-V上的C代码的习惯是函数的返回值存储于寄存器a0,所以为了模拟函数的返回,这里将返回值存储在trapframe的a0中。之后,当返回到用户空间,trapframe中的a0槽位的数值会写到实际的a0寄存器,Shell会认为a0寄存器中的数值是write系统调用的返回值
if(p->killed)再次检查当前用户进程是否被杀掉了
最后,usertrap调用函数usertrapret
usertrapret函数
void
usertrapret(void)
{
struct proc *p = myproc();
// we're about to switch the destination of traps from
// kerneltrap() to usertrap(), so turn off interrupts until
// we're back in user space, where usertrap() is correct.
intr_off();
// send syscalls, interrupts, and exceptions to trampoline.S
w_stvec(TRAMPOLINE + (uservec - trampoline));
// set up trapframe values that uservec will need when
// the process next re-enters the kernel.
p->trapframe->kernel_satp = r_satp(); // kernel page table
p->trapframe->kernel_sp = p->kstack + PGSIZE; // process's kernel stack
p->trapframe->kernel_trap = (uint64)usertrap;
p->trapframe->kernel_hartid = r_tp(); // hartid for cpuid()
// set up the registers that trampoline.S's sret will use
// to get to user space.
// set S Previous Privilege mode to User.
unsigned long x = r_sstatus();
x &= ~SSTATUS_SPP; // clear SPP to 0 for user mode
x |= SSTATUS_SPIE; // enable interrupts in user mode
w_sstatus(x);
// set S Exception Program Counter to the saved user pc.
w_sepc(p->trapframe->epc);
// tell trampoline.S the user page table to switch to.
uint64 satp = MAKE_SATP(p->pagetable);
// jump to trampoline.S at the top of memory, which
// switches to the user page table, restores user registers,
// and switches to user mode with sret.
uint64 fn = TRAMPOLINE + (userret - trampoline);
((void (*)(uint64,uint64))fn)(TRAPFRAME, satp);
}
usertrapret函数设置在返回到用户空间之前内核要做的工作。
intr_off();首先关闭了中断。之前在系统调用的过程中打开了中断,这里关闭中断是因为要更新STVEC寄存器来指向用户空间的trap处理代码,而之前在内核中的时候,我们指向的是内核空间的trap处理代码。关闭中断因为将STVEC更新到指向用户空间的trap处理代码时,我们仍然在内核中执行代码。如果这时发生了一个中断,那么程序执行会走向用户空间的trap处理代码,即便现在仍然在内核中,出于各种各样具体细节的原因,这会导致内核出错。所以这里关闭中断
w_stvec(TRAMPOLINE + (uservec - trampoline));设置了STVEC寄存器指向trampoline代码,在那里最终会执行sret指令返回到用户空间。位于trampoline代码最后的sret指令会重新打开中断。这样,即使刚刚关闭了中断,在执行用户代码时中断也是打开的
接下来的几行填入了trapframe的内容,这些内容对于执行trampoline代码非常有用:
- 存储了kernel page table的指针
- 存储了当前用户进程的kernel stack
- 存储了usertrap函数的指针,这样trampoline代码才能跳转到这个函数
- 从tp寄存器中读取当前的CPU核编号,并存储在trapframe中,这样trampoline代码才能恢复这个数字,因为用户代码可能会修改这个数字
设置好trapframe中的这些数据,这样下一次从用户空间转换到内核空间时可以用到这些数据
接下来要设置SSTATUS寄存器,这是一个控制寄存器。这个寄存器的SPP bit位控制了sret指令的行为,该bit为0表示下次执行sret的时候想要返回user mode而不是supervisor mode。这个寄存器的SPIE bit位控制了,在执行完sret之后,是否打开中断。因为在返回到用户空间之后,我们的确希望打开中断,所以这里将SPIE bit位设置为1。修改完这些bit位之后会把新的值写回到SSTATUS寄存器
w_sepc(p->trapframe->epc);在trampoline代码的最后执行了sret指令,这条指令会将程序计数器设置成SEPC寄存器的值,所以现在将SEPC寄存器的值设置成之前保存的用户程序计数器的值。之前已在usertrap函数中将用户程序计数器保存在trapframe中的epc字段
uint64 satp = MAKE_SATP(p->pagetable);根据user page table地址生成相应的SATP值,这样在返回到用户空间的时候才能完成page table的切换。实际上,我们会在汇编代码trampoline中完成page table的切换,并且也只能在trampoline中完成切换,因为只有trampoline中代码是同时在用户和内核空间中映射。但是现在还没有在trampoline代码中,现在还在一个普通的C函数中,所以这里先将page table指针准备好,并将这个指针作为第二个参数传递给汇编代码,这个参数会出现在a1寄存器
uint64 fn = TRAMPOLINE + (userret - trampoline);计算出将要跳转的汇编代码的地址。我们期望跳转的地址是tampoline中的userret函数,这个函数包含了所有回到用户空间的指令
((void (*)(uint64,uint64))fn)(TRAPFRAME, satp);将fn指针作为一个函数指针,执行相应的函数(也就是userret函数)并传入两个参数,两个参数存储在a0,a1寄存器中
userret函数
现在程序执行又到了trampoline代码
.globl userret
userret:
# userret(TRAPFRAME, pagetable)
# switch from kernel to user.
# usertrapret() calls here.
# a0: TRAPFRAME, in user page table.
# a1: user page table, for satp.
# switch to the user page table.
csrw satp, a1
sfence.vma zero, zero
# put the saved user a0 in sscratch, so we
# can swap it with our a0 (TRAPFRAME) in the last step.
ld t0, 112(a0)
csrw sscratch, t0
# restore all but a0 from TRAPFRAME
ld ra, 40(a0)
ld sp, 48(a0)
......
# restore user a0, and save TRAPFRAME in sscratch
csrrw a0, sscratch, a0
# return to user mode and user pc.
# usertrapret() set up sstatus and sepc.
sret
csrw satp, a1:第一步是切换page table。在执行这条指令之前,page table还是巨大的kernel page table。这条指令会将user page table(在usertrapret中作为第二个参数传递给了这里的userret函数,所以存在a1寄存器中)存储在SATP寄存器中。执行完这条指令之后,page table就变成了小得多的user page table。user page table也映射了trampoline page,所以程序还能继续执行而不是崩溃。(sfence.vma是清空页表缓存)
ld t0, 112(a0):在uservec函数中,第一件事情就是交换SSRATCH和a0寄存器。而这里,先将SSCRATCH寄存器恢复成保存好的用户的a0寄存器。在这里a0是trapframe的地址,因为C代码usertrapret函数中将trapframe地址作为第一个参数传递过来了。112是a0寄存器在trapframe中的位置。(就是通过当前的a0寄存器找出存在trapframe中的a0寄存器)先将这个地址里的数值保存在t0寄存器中,之后再将t0寄存器的数值保存在SSCRATCH寄存器中
注:现在trapframe中的a0寄存器是执行系统调用的返回值。系统调用的返回值覆盖了保存在trapframe中的a0寄存器的值。我们希望用户程序在a0寄存器中看到系统调用的返回值。所以,现在SSCRATCH寄存器中也是系统调用的返回值
到目前为止,所有的寄存器内容还是属于内核。接下来的指令将a0寄存器指向的trapframe中,之前保存的寄存器的值加载到对应的各个寄存器中。恢复好寄存器的数据,a0寄存器现在仍然是指向trapframe的指针,而不是保存了的用户数据(注意和trapframe中的a0寄存器区分开来)
csrrw a0, sscratch, a0:在返回到用户空间之前,交换SSCRATCH寄存器和a0寄存器的值。SSCRATCH现在的值是系统调用的返回值,a0寄存器是trapframe的地址。交换完成之后,a0持有的是系统调用的返回值,SSCRATCH持有的是trapframe的地址。之后trapframe的地址会一直保存在SSCRATCH中,直到用户程序执行了另一次trap。现在还在kernel中
sret是在kernel中的最后一条指令,当执行完这条指令:
- 程序会切换回user mode
- SEPC寄存器的数值会被拷贝到PC寄存器(程序计数器)
- 重新打开中断
现在回到了用户空间
页面错误基础
page fault可以让地址映射关系变得动态起来。通过page fault,内核可以更新page table。当发生page fault时,内核需要什么样的信息才能够响应page fault:
- 需要出错的虚拟地址,或者是触发page fault的源。当出现page fault的时候,XV6内核会打印出错的虚拟地址,并且这个地址会被保存在STVAL寄存器中。所以,当一个用户应用程序触发了page fault,page fault会使用trap机制,将程序运行切换到内核,同时也会将出错的地址存放在STVAL寄存器中
- 出错的原因,需要对不同场景的page fault有不同的响应。不同的场景是指,比如因为load指令触发的page fault、因为store指令触发的page fault又或者是因为jump指令触发的page fault。RISC-V文档在SCAUSE(Supervisor cause寄存器,保存了trap机制中进入到supervisor mode的原因)寄存器的介绍中,有多个与page fault相关的原因。比如,13表示是因为load引起的page fault;15表示是因为store引起的page fault;12表示是因为指令执行引起的page fault。所以第二个信息存在SCAUSE寄存器中,其中总共有3个类型的原因与page fault相关,分别是读、写和指令。ECALL进入到supervisor mode对应的是8。基本上来说,page fault和其他的异常使用与系统调用相同的trap机制来从用户空间切换到内核空间。如果是因为page fault触发的trap机制并且进入到内核空间,STVAL寄存器和SCAUSE寄存器都会有相应的值
- 触发page fault的指令的地址。作为trap处理代码的一部分,这个地址存放在SEPC(Supervisor Exception Program Counter)寄存器中,并同时会保存在trapframe->epc中
所以,从硬件和XV6的角度来说,当出现了page fault,现在有3个极其有价值的信息,分别是:
-
引起page fault的内存地址
-
引起page fault的原因类型
-
引起page fault时的程序计数器值,这表明了page fault在用户空间发生的位置
Lazy page allocation 惰性分配
sbrk是XV6提供的系统调用,它使得用户应用程序能扩大自己的heap。当一个应用程序启动的时候,sbrk指向的是heap的最底端,同时也是stack的最顶端。这个位置通过代表进程的数据结构中的sz字段表示,这里以p->sz表示。

在xv6中,调用sbrk的时候默认是立即分配内存,创建映射。但应用程序一般会申请多于自己所需要的内存,多出来的内存可能会一直用不到,造成内存浪费。
惰性分配思想:调用sbrk的时候,只增加p->sz,将p->sz增加n,其中n是需要新分配的内存page数量,但不分配任何物理内存。之后在某个时间点,应用程序使用到了新申请的那部分内存,这时会触发page fault,因为还没有将新的内存映射到page table。因此,可以在使用到大于旧的p->sz并且小于新的p->sz的虚拟地址的时候,再分配内存。
当触发page fault,相应的虚拟地址小于当前p->sz,同时大于stack,就知道这是一个来自于heap的地址,但是内核还没有分配任何物理内存。这时可以通过kalloc函数分配一个内存page,初始化这个page内容为0,将这个内存page映射到user page table中,最后重新执行指令
Zero Fill On Demand
用户程序的地址空间存在text区域,data区域,同时还有一个BSS区域(BSS区域包含了未被初始化或者初始化为0的全局或者静态变量)。因为BSS里面保存了未被初始化的全局变量,这里或许有许多许多个page,但是所有的page内容都为0
Zero Fill On Demand思想:将这些数据全是0的page全都映射到用一个物理地址,节省物理内存分配。这些page的pte都是只读,应用程序尝试写BSS中的一个page时,触发page fault,这时在物理内存中申请一个新的内存page,将其内容设置为0,更新这个page的mapping关系,PTE设置成可读可写,然后将其指向新的物理page,相当于更新了PTE,之后可以重新执行指令
Copy On Write 写时复制
程序调用fork创建子进程的时候,会把父进程地址空间的数据完全复制给子进程。但如果子进程第一件事就是执行exec,马上丢弃这个地址空间,就浪费了操作,浪费了空间。
COW思路:创建子进程时,子进程直接共享父进程的地址空间,设置所有的page都是只读。当某一个进程执行写操作的时候,触发page fault,再分配新的物理内存,创建映射,恢复写权限,重新执行指令
Demand Paging
执行exec的时候,操作系统会加载程序内存的text,data区域,马上将这些数据加载进page table
Demand Paging思路:直到应用程序实际需要这些指令的时候再加载内存。在虚拟地址空间中为text和data分配好地址段,但是相应的PTE并不对应任何物理内存page,将这些PTE对应的PTE_V设置为0。应用程序是从地址0开始运行。text区域从地址0开始向上增长。位于地址0的指令触发第一个page fault,这个page是on-demand page,需要在某个地方记录了这些page对应的程序文件,在page fault handler中从程序文件中读取page数据,加载到内存中,之后将内存page映射到page table,最后再重新执行指令
文件系统
文件系统的目的是组织和存储数据,通常支持用户和应用程序之间的数据共享。文件系统解决了几个难题:
- 文件系统需要磁盘上的数据结构来表示目录和文件名称树,记录保存每个文件内容的块的标识,以及记录磁盘的哪些区域是空闲的。
- 文件系统必须支持崩溃恢复(crash recovery)。也就是说,如果发生崩溃(例如,电源故障),文件系统必须在重新启动后仍能正常工作。风险在于崩溃可能会中断一系列更新,并使磁盘上的数据结构不一致(例如,一个块在某个文件中使用但同时仍被标记为空闲)。
- 不同的进程可能同时在文件系统上运行,因此文件系统代码必须协调以保持不变量。
- 访问磁盘的速度比访问内存慢几个数量级,因此文件系统必须保持常用块的内存缓存。
概述
xv6文件系统实现分为七层
| 文件描述符(File descriptor) |
|---|
| 路径名(Pathname) |
| 目录(Directory) |
| 索引结点(Inode) |
| 日志(Logging) |
| 缓冲区高速缓存(Buffer cache) |
| 磁盘(Disk) |
磁盘层读取和写入virtio硬盘上的块。
缓冲区高速缓存层缓存磁盘块并同步对它们的访问,确保每次只有一个内核进程可以修改存储在任何特定块中的数据。
日志记录层允许更高层在一次事务(transaction)中将更新包装到多个块,并确保在遇到崩溃时自动更新这些块(即,所有块都已更新或无更新)。
索引结点层提供单独的文件,每个文件表示为一个索引结点,其中包含唯一的索引号(i-number)和一些保存文件数据的块。
目录层将每个目录实现为一种特殊的索引结点,其内容是一系列目录项,每个目录项包含一个文件名和索引号。
路径名层提供了分层路径名,如/usr/rtm/xv6/fs.c,并通过递归查找来解析它们。
文件描述符层使用文件系统接口抽象了许多Unix资源(例如,管道、设备、文件等),简化了应用程序员的工作
文件系统必须有将索引节点和内容块存储在磁盘上哪些位置的方案。为此,xv6将磁盘划分为几个部分
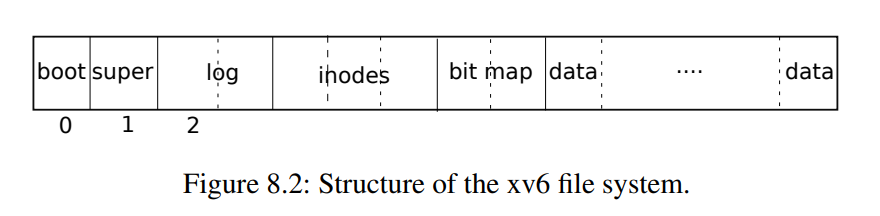
文件系统不使用块0(它保存引导扇区)
块1称为超级块:它包含有关文件系统的元数据(文件系统大小(以块为单位)、数据块数、索引节点数和日志中的块数)。超级块由一个名为mkfs的单独的程序填充,该程序构建初始文件系统
从2开始的块保存日志
日志之后是索引节点,每个块有多个索引节点
然后是位图块,跟踪正在使用的数据块
其余的块是数据块:每个都要么在位图块中标记为空闲,要么保存文件或目录的内容
缓冲区高速缓存层(Buffer cache)
相关代码:kernel/bio.c。Buffer cache有两个任务:
- 同步对磁盘块的访问,以确保磁盘块在内存中只有一个副本,并且一次只有一个内核线程使用该副本
- 缓存常用块,以便不需要从慢速磁盘重新读取它们
Buffer cache层导出的主接口主要是bread和bwrite:
bread获取一个buf,其中包含一个可以在内存中读取或修改的块的副本
bwrite将修改后的缓冲区写入磁盘上的相应块
内核线程必须通过调用brelse释放缓冲区。Buffer cache每个缓冲区使用一个睡眠锁,以确保每个缓冲区(每个磁盘块)每次只被一个线程使用;bread返回一个上锁的缓冲区,brelse释放该锁
Buffer cache中保存磁盘块的缓冲区数量固定,这意味着如果文件系统请求还未存放在缓存中的块,Buffer cache必须回收当前保存其他块内容的缓冲区。Buffer cache为新块回收最近使用最少的缓冲区。这样做的原因是认为最近使用最少的缓冲区是最不可能近期再次使用的缓冲区
相关代码:kernel/bio.c。
Buffer cache是以双链表表示的缓冲区。main(kernel/main.c*)调用的函数binit使用静态数组buf(kernel/bio.c*)中的NBUF个缓冲区初始化列表。对Buffer cache的所有其他访问都通过bcache.head引用链表,而不是buf数组
缓冲区有两个与之关联的状态字段。字段valid表示缓冲区是否包含块的副本。字段disk表示缓冲区内容是否已交给磁盘,这可能会更改缓冲区(例如,将数据从磁盘写入data)
bread调用bget为给定扇区获取缓冲区。如果缓冲区需要从磁盘进行读取,bread会在返回缓冲区之前调用virtio_disk_rw来执行此操作。
bget扫描缓冲区列表,查找具有给定设备和扇区号的缓冲区。如果存在这样的缓冲区,bget将获取缓冲区的睡眠锁。然后bget返回锁定的缓冲区
如果对于给定的扇区没有缓冲区,bget必须创建一个,这可能会重用包含其他扇区的缓冲区。再次扫描缓冲区列表,查找未在使用中的缓冲区(b->refcnt = 0):任何这样的缓冲区都可以使用。bget编辑缓冲区元数据以记录新设备和扇区号,并获取其睡眠锁。注意,b->valid = 0的布置确保了bread将从磁盘读取块数据,而不是错误地使用缓冲区以前的内容
一旦bread读取了磁盘并将缓冲区返回给其调用者,调用者就可以独占使用缓冲区,并可以读取或写入数据字节。如果调用者确实修改了缓冲区,则必须在释放缓冲区之前调用bwrite将更改的数据写入磁盘。bwrite调用virtio_disk_rw与磁盘硬件对话
当调用方使用完缓冲区后,它必须调用brelse来释放缓冲区。brelse释放睡眠锁并将缓冲区移动到链表的前面。移动缓冲区会使列表按缓冲区的使用频率排序:列表中的第一个缓冲区是最近使用的,最后一个是最近使用最少的。bget中的两个循环利用了这一点:在最坏的情况下,对现有缓冲区的扫描必须处理整个列表,但首先检查最新使用的缓冲区(从bcache.head开始,然后是下一个指针),在引用局部性良好的情况下将减少扫描时间。选择要重用的缓冲区时,通过自后向前扫描(跟随prev指针)选择最近使用最少的缓冲区
inode
inode是一个64字节的数据结构,包含:
-
type字段,表明inode是文件还是目录
-
nlink字段,也就是link计数器,用来跟踪究竟有多少文件名指向了当前的inode
-
size字段,表明了文件数据有多少个字节
-
12个direct block number,这些直接块编号直接指向文件的前 12 个磁盘块。当文件较小时,直接块可以满足文件存储的需求,每个块的大小在 xv6 中是 1KB,因此使用 12 个直接块意味着最多可以存储 12 * 1KB = 12KB 的数据
-
1个indirect block number,指向一个间接块,间接块本身是一个磁盘块,其中包含了 256 个条目,每个条目存储一个数据块编号,这些编号依次指向文件的数据块
XV6中最大文件尺寸:(256 + 12) * 1KB = 268KB
1个block是1KB,一个 block number 是4字节,1024 / 4 = 256
inode有两种含义:磁盘上的数据结构inode,以及内存中的inode,包含磁盘inode的副本以及内核中所需的额外信息
磁盘inode:inode 在磁盘上被存储为固定大小的结构,并被连续存储在一个区域中。 struct dinode(kernel/fs.h)是磁盘 inode 的数据结构,字段type表示 inode 类型(文件、目录、特殊文件),字段nlink记录引用该 inode 的目录条目的数量,减为零时释放该 inode 和其占用的数据块,字段size记录文件内容的字节数,字段addrs为一个数组,记录了保存文件内容的磁盘块号
内存inode:当文件被访问(如打开或修改)时,系统会将磁盘上的 inode 加载到内存中,并在内存中维护它的一个副本。struct inode(kernel/file.h) 是磁盘 inode 的内存副本,并包含额外字段来支持内核的操作。只有当某个进程需要访问文件时,系统才会将磁盘 inode 加载到内存,并创建 struct inode。ref字段统计引用内存中inode的C指针的数量,如果引用计数降至零,内核将从内存中丢弃该inode。iget 和 iput 函数分别获取和释放指向 inode 的指针,修改引用计数
内存inode中的锁机制:
icache.lock:保护全局 inode 缓存(icache),确保每个 inode 在缓存中最多只有一个副本,保护 inode中ref字段的正确性,即记录指向该 inode 的内存指针的正确数量- inode的
struct sleeplock lock字段:每个 inode 的独立锁,用于对该 inode 的独占访问,确保对 inode 的元数据字段和其内容块的修改是线程安全的 - inode的
ref字段:管理内存 inode 的生命周期,记录指向该 inode 的 C 指针数量。如果 ref 减少到 0,表示内存中已没有任何代码持有该 inode 的引用,缓存可以移除该inode,但 inode 在磁盘上仍然存在 - inode的
nlink字段:管理磁盘 inode 的生命周期,记录指向该inode的目录项(创建硬链接)。当 nlink 减少到 0,表示没有任何目录项指向该 inode,如果 inode 的内容已经不在内存中(即ref == 0),该 inode 将被完全释放,包括 inode 本身和它占用的所有数据块
iget(uint dev, uint inum)函数返回一个inode指针,在调用iput(struct inode *ip)函数之前该inode始终有效(iput对ref-1,若ref为0会释放该indoe)。不锁inode,保证将 inode 加载到内存,并增加其引用计数。多个线程或进程可以同时持有指向同一 inode 的指针,提高访问效率,但在对 inode 数据进行修改或读取时,需要调用 ilock 来加锁
iget函数中的部分代码如下:
empty = 0;
for(ip = &icache.inode[0]; ip < &icache.inode[NINODE]; ip++){
if(ip->ref > 0 && ip->dev == dev && ip->inum == inum){
ip->ref++;
release(&icache.lock);
return ip;
}
if(empty == 0 && ip->ref == 0) // Remember empty slot.
empty = ip;
}
如果没有找到匹配的inode,会返回一个之前未被引用的inode(当然返回之前会初始化这个inode,ref为1),这个inode的valid字段为0,表示未从磁盘中读取到内存中。为了确保该inode保存磁盘inode的副本,代码必须调用ilock函数。ilock函数确保 inode 被独占访问,如果 inode 的 valid 标志为0(未加载内容),则从磁盘读取 inode 的内容到内存。iunlock函数用于释放 inode 上的锁,解锁后,其他进程或线程可以访问该 inode
内存inode的主要功能是确保对 inode 的并发访问是安全的,只要有 C 指针引用 inode(即 ref > 0),该 inode 就会保留在缓存中,不会被释放。inode 缓存是直写的(write-through),对 inode 的任何修改都会通过 iupdate() 立即同步到磁盘
ialloc是分配一个新的磁盘inode的函数,用于创建文件、目录或设备节点时初始化inode数据结构。ialloc函数遍历所有inode,寻找字段type==0的空闲inode。找到之后,将该inode初始化,设置其字段type为指定的type,在通过iget函数将该磁盘inode读入内存。在遍历过程中,会使用bread函数读取磁盘块bp,此时bp是上锁的,确保ialloc的分配过程是原子的
iput函数会将一个内存inode的ref字段-1。如果ref减为零,意味着没有任何指针引用该 inode,此时该 inode 的缓存槽位可以被其他 inode 重用。如果ref减为零且没有任何链接指向该 inode(nlink == 0),iput 将释放该 inode 及其占用的数据块。
-
当
ip->ref == 1且nlink == 0时,只有调用iput的线程持有该 inode 的引用,其他线程无法再获取指向该 inode 的指针。iput中,通过先获取icache.lock,然后获取睡眠锁,确保在操作过程中不会出现死锁。 -
当
ialloc尝试分配新的 inode 时,如果正好选择了一个正在被iput释放的 inode,分配线程会等待inode.lock,确保在读取或写入该 inode 时不会发生冲突。这种竞争是良性的,因为分配线程会在iput完成后继续进行 -
由于
iput可能进行磁盘写操作,所有涉及文件系统的系统调用(包括只读操作)都需要在事务中执行,确保文件系统的一致性和完整性
即使文件的链接计数(nlink)降为 0,某些进程仍可能持有该 inode 的引用(比如进程打开了该文件并正在读写)。因此,不能在 iput 中立刻释放 inode 和相关资源。如果在最后一个进程关闭该文件之前发生崩溃,inode 会以一种“不一致”状态留存在磁盘上:文件在磁盘上被标记为“已分配”,但磁盘上没有任何目录项指向该 inode,导致用户无法访问该磁盘inode。随着时间推移,磁盘空间会被这些“不再使用但未释放”的 inode 逐渐耗尽
现代文件系统通过两种方式解决这一问题:
- 文件系统在崩溃后重新启动时,扫描整个磁盘上的所有 inode,查找标记为“已分配”但没有任何目录项引用的 inode,释放它们的空间,回收资源
- 文件系统维护一个列表(比如记录在超级块中),用来跟踪nlink为 0,但引用计数不为 0 的 inode。当系统重新启动时,只需检查这个列表中的 inode 是否仍然有进程引用,如果没有引用(ref为 0),释放它们,如果仍有引用,则无需操作
(XV6没有实现上面两种方案,没有解决这个问题。对于这个实验来说是一个扩展点)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号