简明详细了解朴素贝叶斯分类
朴素贝叶斯分类是监督学习中的一个方法。其不按常理出牌,以概率的方式来进行分类和学习。
我将首先给定一个具体的例子说明其实现过程,然后我将给出其具体的推导原理:
我们首先对一个人美丑进行判别
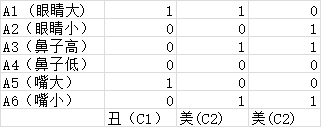
这个表格是我们事先对美丑进行的分类
A={A1,A2,A3,A4,A5,A6} 这个A被称为属性的集合(又称特征值)
C={C1,C2} C被称为类别(即是我们最终对输入数据所分的类别)
朴素贝叶斯基于这个原理

我们首先利用训练集对模型进行训练:
p(C=C1) = 1/3(我们样本集中分类为C1 ,就是丑的概率) p(C=C2) = 2/3(我们样本集中分类为C2 ,就是美的概率)
p(A1=1|C1)=1 (在丑的样例中眼睛大的概率) p(A1=1|C2)=1/2(在美的样例中眼睛大的概率)
p(A1=0|C1)=1 (在丑的样例中眼睛小的概率) p(A1=0|C2)=1/2(在美的样例中眼睛小的概率)
这样对表中数据A1-A6均算出概率

接下来我们给定一个人的数据
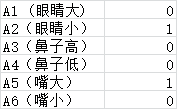
首先判断他是丑的类别的概率:p(C=C1) = P(A1=0|C=C1)+P(A2=1|C=C1)+P(A3=0|C=C1)+P(A4=0|C=C1)+P(A5=1|C=C1)+P(A6=0|C=C1)
然后判断他是美的类别的概率:p(C=C2) = P(A1=0|C=C2)+P(A2=1|C=C2)+P(A3=0|C=C2)+P(A4=0|C=C2)+P(A5=1|C=C2)+P(A6=0|C=C2)
由于P(A1=0|C=C1)...P(A6=0|C=C1) 这些数据可以从刚才对训练集的计算中得出,我们就可以得出p(C=C1)和 p(C=C2)具体的值,然后我们比较大小就可得出,该人更偏向概率大的类别
接下来我们说一下理论:
我们分类的任务是给定一个样例d计算它的后验概率 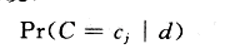
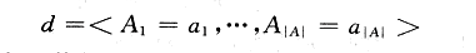
C表示所需分类的类别
A1...A|A|表示样例d的属性值 .
a表示该属性的可能的取值
根据贝叶斯公式:
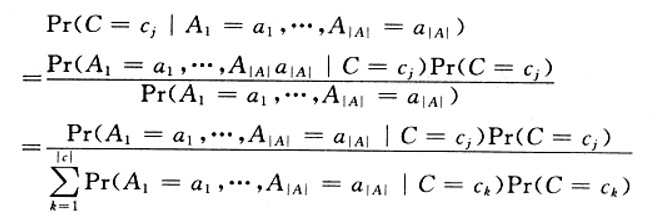
由于我们仅关心分类,所以我们分母均相同,我们将分子展开为:
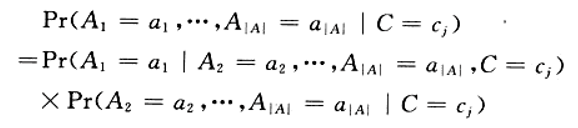
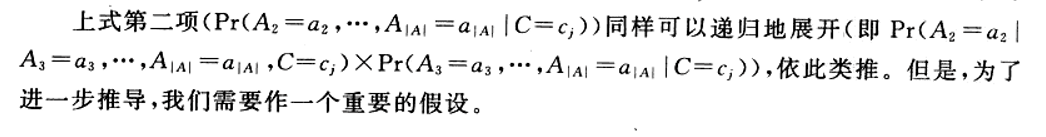
假设所有属性Ai都是互不影响的。即:
Pr (A1=a1|A2=a2,...A|A| =a|A| ,C=Cj)=Pr(A1=a1|C=Cj)
于是
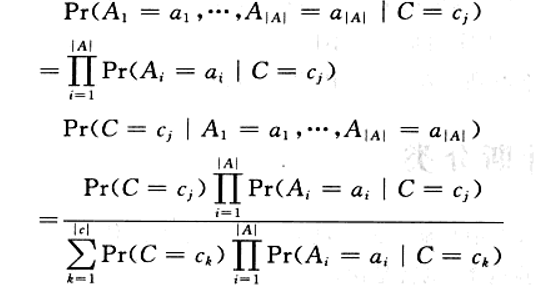
而Pr(C=cj)和Pr(Ai=ai|C=Cj)都由已知样本得出:

所以我们只需求
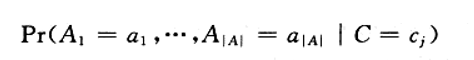 在每个Cj中最大的概率值,那个最大概率值所属的类别既是样本最有可能属于的类别
在每个Cj中最大的概率值,那个最大概率值所属的类别既是样本最有可能属于的类别

 浙公网安备 33010602011771号
浙公网安备 33010602011771号