机器学习十讲——第八讲学习总结
维度灾难:随着维度(如特征或自由度)的增多,问题的复杂性(或计算算代价)呈指数级增长的现象。
高维空间的反直觉示例:单位球体积:

一维,二维,三维的 长度/面积/体积 都有公式计算,而高维的计算公式是这样的:
d维空间半径为r的球体体积公式: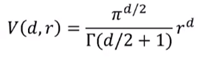
单位球体积与维度之间的关系图示:

在高维空间中,球体内部的体积与表面积处的体积相比可以忽略不计,大部分体积都是分布在边界的:

高维空间中的欧式距离:d维空间样本x1和x2的欧式距离为: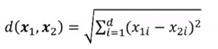
随着维数增加,单个维度对距离的影响越来越小,任意样本间的距离趋于相同:

由于距离在高维空间中不再有效,因此一些基于距离的机器学习模型就会收到影响。
基于距离的机器学习模型:K近邻(样本间距离),支持向量机(样本到决策面距离),K-Means(样本到聚类中心距离),层次聚类(不同簇之间的距离),推荐系统(商品或用户相似度),信息检索(查询和文档之前的相似度)。
稀疏性与过度拟合:
过度拟合:模型对已知数据拟合较好,新的数据拟合较差。极端例子:训练集准确率越来越高,而使用测试集测试模型准确率依然维持在0.5左右。
稀疏性:高维空间中样本变得极度稀疏,容易会造成过度拟合问题。
Hughes现象:随着维度增大,分类器性能不断提升直到达到最佳维度,继续增加维度分类器性能会下降。
高维空间计算复杂度指数增长,因此只能近似求解,得到局部最优解而非全局最优解。
举例——决策树:选择切分点对空间进行划分。每个特征m个取值,候选划分数量m^d(维度灾难)
举例——朴素贝叶斯:

应对维度灾难:特征选择和降维
特征选择:选取特征子集。
降维:使用一定变换,将高维数据转换为低维数据,PCA,流形学习,t-SNE等。
正则化:减少泛化误差而不是训练误差

核技巧:

判断机器学习模型是否存在维度灾难问题:

不存在维度灾难问题的模型:随机特征模型,两层神经网络,残差神经网络等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号