机器学习十讲——第四讲学习总结
本讲主要讲了三个算法:决策树,随机森林,AdaBoost
模型误差的来源

非线性模型
线性回归:多项式回归
支持向量机:给定的核函数组合,基本属于“猜测”
决策树:空间划分的思想来处理非线性数据
深度学习
感知机:线性回归+简单的非线性映射
多层感知机:多层神经元的组合,多个简单非线性函数的复合
深度学习:层数很大
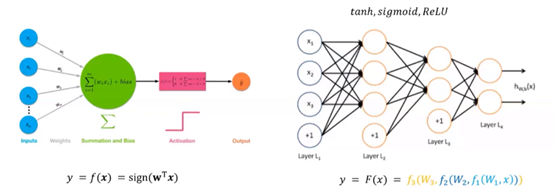
sign:神经元
结合上面估计误差那张图来看,深度学习可以“拓宽”估计误差范围,更容易找到适合的f。
模型集成
思路:训练多个弱模型,组合成一个“强”模型。
为什么可以提高效果:增强模型的表达能力;降低误差(概率角度)。
模型介绍
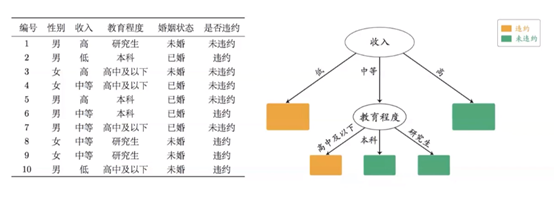
决策树:
把问题问到点子上。(如银行放贷决策)
空间的方块划分(优化目标:每个空间的不纯度越低越好):
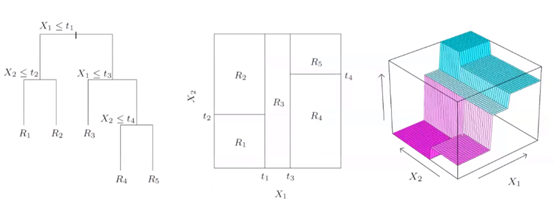
决策树生成:从根节点开始选择节点对应特征(如年龄…);选择节点特征分割点,根据分割点分裂节点(如年龄50)。
核心问题:如何选择节点属性和属性分割点。
概念引入——不纯度:
定义:表示落在当前节点的样本类别分布的均衡程度。
说明:节点分裂后,节点不纯度应该更低(类分布更不均衡);选择特征及对应的分割点,使得分裂前后的不纯度下降最大。
不纯度度量方法:
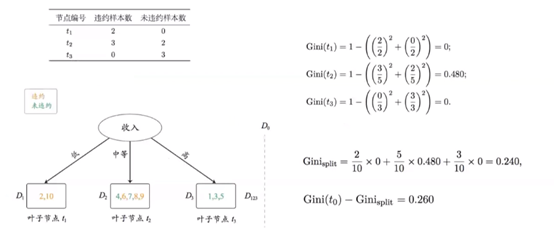
Gini指数:

计算示例:
信息熵:

误分率:
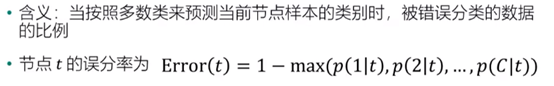
三种度量方法的图示比较:
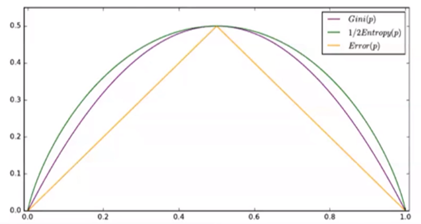
可以看到Gini指数和信息熵更平滑一些。
决策树中可以使用叶子节点来做预测。
随机森林:
Bagging算法(典型):“随机”是核心,“森林”指组合多组决策树来构建模型。
主要特点:对样本进行有放回抽样;对特征进行随机抽样。
算法流程:

算法分析:
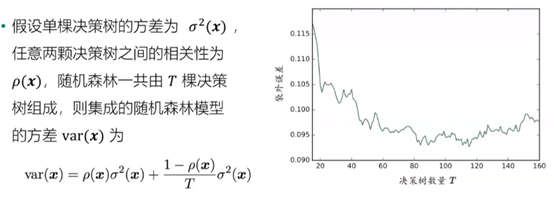
可以理解为随机抽取样本减少数据集的相关性。
在随机森林中每组数据集都是独立的,可变形的,更加灵活(如可使用多台电脑进行不同的数据集分析)
AdaBoost:
基本思想:通过改变样本权重串行地训练多个基分类器,每个基分类器带权重样本集下进行训练,根据其在训练样本中的加权误差来确定基分类器模型的权重,后一个分类器更加关注前一个分类器分错的样本。
算法流程:

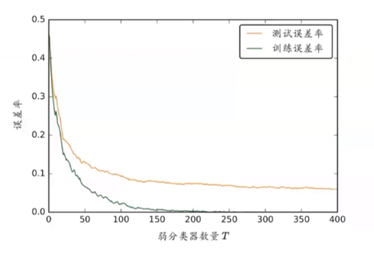
算法优点:不容易过度拟合。因为理论上随着弱分类器数目T的增大,泛化误差上界会增大。如图所示: