将 Amazon EC2 到 Amazon S3 的数据传输推向100Gbps 线速
前言
天下武功唯快不破,在很多应用场景中,如机器学习、数据分析、高性能计算等,应用需要高速加载大量数据后进行本地计算。
试想一下,您在亚马逊云科技上启动了一台 p4d.24xlarge (8 x NVIDIA A100 Tensor Core GPUs) 的实例,您立即拥有了一尊有 PetaFLOPS 级处理能力的性能怪兽,为了喂饱这个家伙,您在 Amazon Simple Storage Service (Amazon S3) 上准备了 TB 级的基础数据,按200 GiB 一个对象拆分后存放。如果按照万兆10 G 网络的理论速度 1.16 GiB/s 的峰值性能来下载数据到本地,200 GiB 的单个对象需要大约172秒 ≈ 2.8分钟,那就意味着下载1 TiB 数据集总共需要等待14分钟左右,p4d.24xlarge 的按需实例报价大约是32.7/小时,也就是说,每小时里花了7.63等待数据到来后,您才能真正开始计算任务。
亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库!
改善数据等待的方法有很多,优化工作流程、调整数据 pipeline、边下载边计算都可以部分缓解这个问题,但随之而来的是需要更复杂的工作流程和更智慧的调度算法。
但是,如果我们找到问题的核心,让数据下载更快,那一切都会直接变得简单了。经常有客户会问到: 把我存储在 Amazon Simple Storage Service (Amazon S3) 上的数据下载到 Amazon Elastic Compute Cloud (Amazon EC2) 上,速度能有多快?
答案是非常肯定的:在全球任何一个亚马逊云科技的区域里,Amazon EC2 到 Amazon S3 的默认数据传输带宽都可以最高达到100 Gbps(https://aws.amazon.com/cn/premiumsupport/knowledge-center/s3-maximum-transfer-speed-ec2/?trk=cndc-detail)。
“100 Gbps?! ” “在云上可以达到10万兆网络的传输速度?”
那么接下去的问题是:需要怎么做才能达到这么高的传输带宽?
本文希望通过梳理在云上进行高性能数据传输的一些背景知识和具体方法,帮助大家达成进行接近100 Gbps 线速的数据传输目标。为了验证最高的带宽,我们给自己设定了一个难题:将1个200 GiB 的对象存储在 S3 上,使用单进程应用,以最快的速度把这个对象下载到 EC2 上。
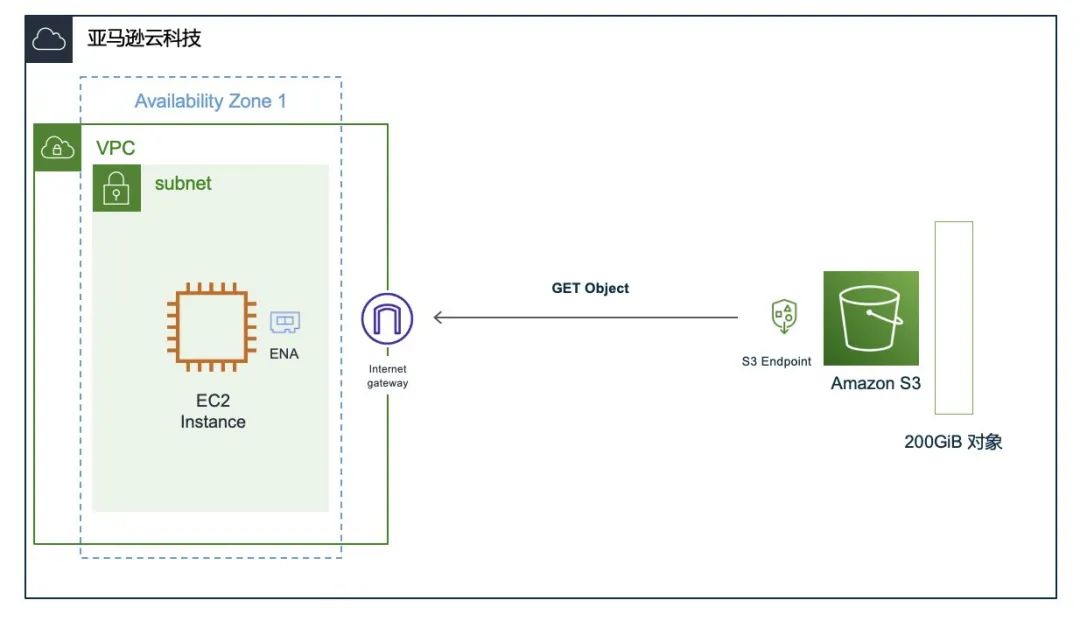
图:整体架构
为了达到我们设定的目标,我们先要回顾几个重要的关于亚马逊云科技服务和性能的知识点:
知识点1 Amazon S3
Amazon S3 是亚马逊云科技在2006年发布的第一个云服务,面向互联网海量用户同时使用的对象存储,在2021 pi day 上披露的数据显示(https://aws.amazon.com/cn/blogs/aws/amazon-s3s-15th-birthday-it-is-still-day-1-after-5475-days-100-trillion-objects/?trk=cndc-detail),S3 已经存储了超过 100 万亿个对象,达到每秒数千万个请求的经常性峰值。S3 为存储在上面的数据提供11个9的持久性和99.99%的可用性。
用户与 S3 的所有交互通过基于 HTTP 的 S3 REST API 来实现,因为存取使用方便,提供很高的可用性与可靠性,按需计费,并且价格也很便宜,因此 S3 是客户长期持久化海量数据的首选服务。如今以 S3 为中心的数据湖架构也应用得越来越广泛,S3 持续发挥着作为互联网基石的作用。
图:Amazon S3
知识点2 Amazon 的 VPC 网络
S3 和 EC2 在服务的网络上有很大不同,简而言之,EC2 的网络归属于用户的 VPC 中,通过 IP 网络与其他 EC2 或者亚马逊云科技的其他服务进行通讯和交互,而 S3 是一个独立服务并不存在于任何一个用户的 VPC 中,EC2 通过 S3 提供的 Endpoint 与 S3 进行通讯。
从下面的架构图中我们可以看到,从 EC2 到 S3 的网络流量需要经过 EC2 的本机网卡 ENA(1) → 用户 VPC →网关(2) → S3 Endpoint(3)。
在这个数据传输链路中,我们需要注意:
- 每款 EC2 实例类型都有可达到的最高带宽;
- 部分实例有基线带宽和突增带宽,通过网络 I/O 的 credits 机制控制可突增的时长。
因此在构建数据传输之前,您需要了解您使用实例的网络性能上限,有关 EC2 实例网络带宽的更详细的介绍可以参看文档:
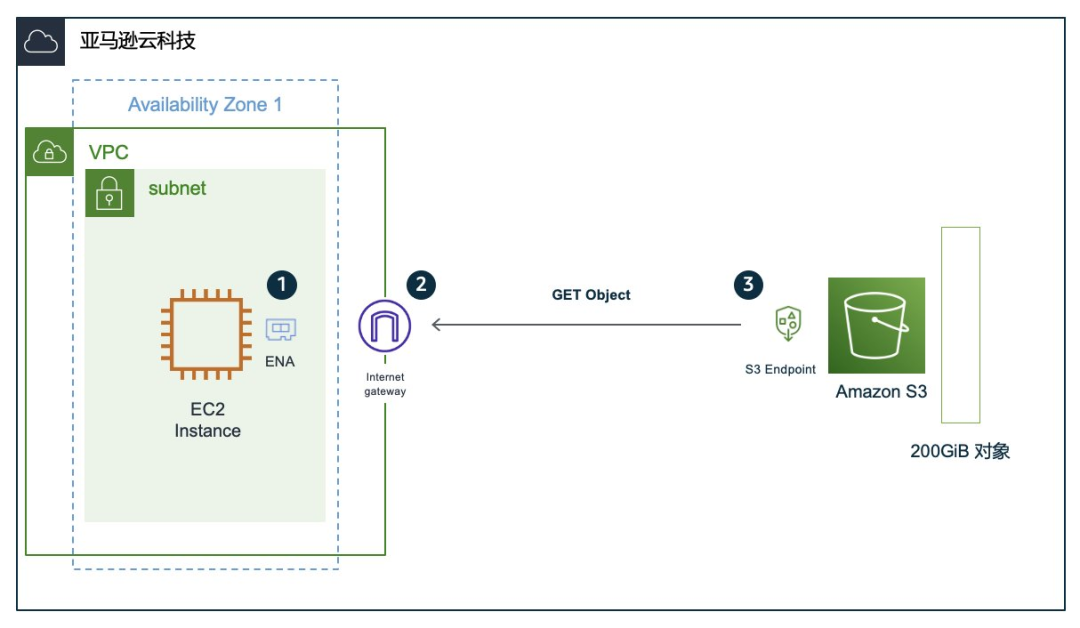
图:EC2 到 S3 的网络结构
知识点3 并发
在现代计算机的性能模型中,提高并发度是达成高性能的关键技术。并发的方式有多种多样,如线程级的并发、进程级的并发、节点级的并发,每一种并发的方式都有自己的并发模型,并与之配套有相应的同步机制和 I/O 请求模式。
为了实现更好的整体性能,高性能应用通常会采用事件循环+非阻塞 I/O 的方式,相比传统应用的线程/进程+阻塞 I/O 的方式,前者可以极大提高单节点上的 I/O 处理能力。比如,大家熟悉的 redis, nginx 等都采用了事件循环的架构来实现高性能。
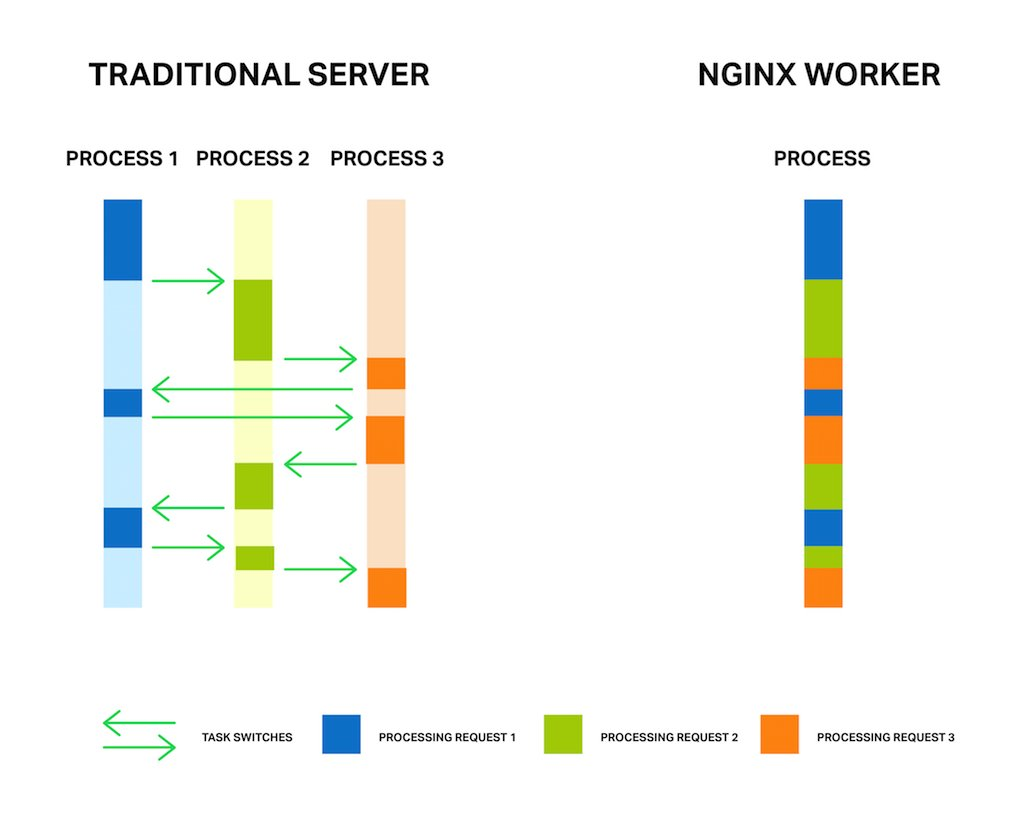
图:Nginx Event Loop 介绍
引用自: https://www.nginx.com/blog/thread-pools-boost-performance-9x/?trk=cndc-detail
我们的既定目标是:“将1个200 GiB 的对象存储在 S3 上,使用单进程应用,以最快的速度把这个对象下载到 EC2 上。”
那么如果只有一个目标对象,如何能够实现并发访问或下载呢?
知识点4 并发访问 S3
对于 S3 来说在上传和下载路径都可以对单个对象进行分片操作,在上传路径,S3 通过 Multipart Upload 实现单个大对象的分片上传。
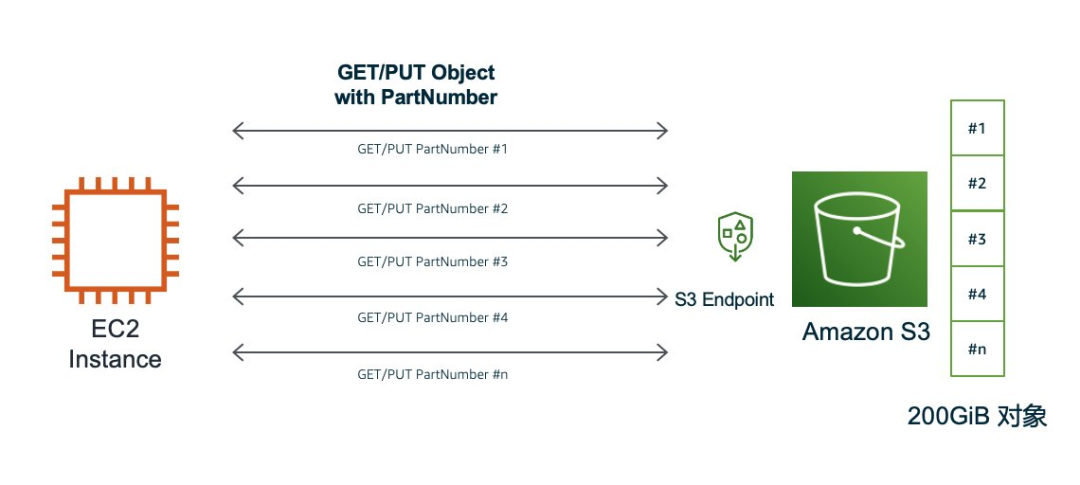
图:S3 对象分段上传下载
在下载路径上,S3 支持两种方式的分片下载。
第一种,如果对象是以分片的方式进行上传的,那下载时可以按照原来分片上传的各个部分 (part) 来进行下载。
第二种,S3 API 提供了 Bytes Range 的方式,可以自由指定一个对象中的某一段来进行下载。
第一种方式略有局限,因为上传时的分片设置并不一定完全适合下载时使用,并且有时候我们可能仅需要一个对象中的某一小部分,而在 Bytes Range 的方式下,一次 API 请求可以指定对象的某一个连续区间进行下载,方便用户根据应用的需要进行适当调整。

图:S3 对象按字节区间 (Byte Range) 下载
为了应对全网海量用户的同时访问请求,在接入层,S3 的 Endpoint 提供了单一域名对应多个 IP 地址的方式来实现接入层的负载均衡。在实践中,通过 DNS 解析 S3 的 Endpoint 域名,大约每隔几秒钟会得到一个不同的 A 记录 (IPv 4地址)。因为 S3 提供了强一致性,所以用户可以放心从 Endpoint 解析出来的多个 IP 同时访问 S3。
为了尽可能增加下载的并发度,以使传输能够达到最大的传输带宽,我们采取按 Bytes Range 分片下载对象,并尽可能把对每个分片下载请求发送到不同的 S3 Endpoint IP 地址上的方式来发起请求。因此,我们的数据请求模型变成了以下的模式。
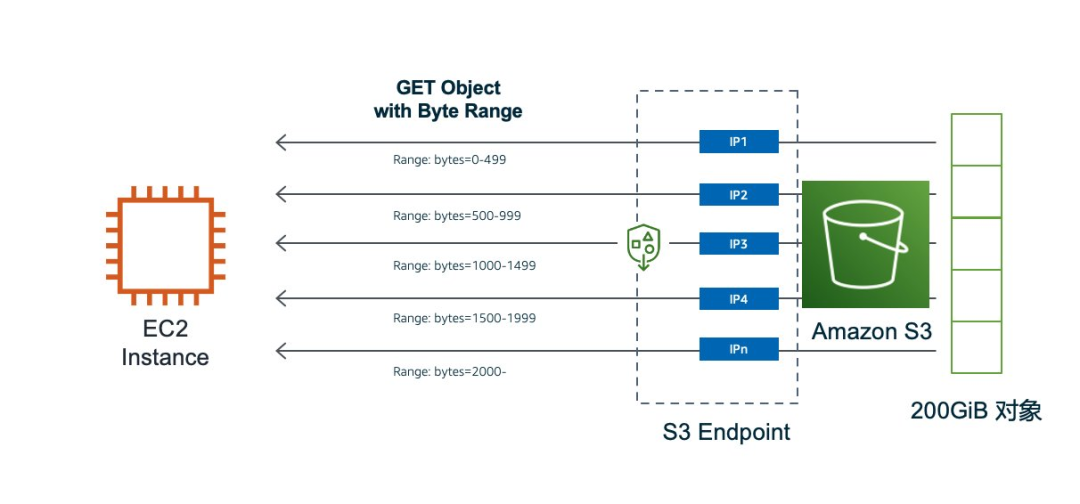
图:使用多个 IP 地址从 S3 按字节区间下载对象
知识点5 关于数据落盘
以100 Gbps 为例,如果您要在本机上保留下载数据的副本,那意味着您需要以 11.64 GiB/s 的速度在本地磁盘上保存这些数据。在实际场景中这是需要注意的:必须为计算节点配置与下载速率相匹配的本地存储。当然您如果采用流式计算或者不需要持久化数据到本地,那您可以忽略这部分内容。
最后,在动手构建之前,我们还需要回答如下问题:
- 没有现成的工具可以达到我们的预设目标吗?
- 对于 S3 上的数据管理和使用,亚马逊云科技已经提供了完善的工具集, 包括了 Web Console, Amazon Command Line Interface (Amazon CLI) 工具以及各种语言的 Amazon SDK 等,使用现有的这些工具能否达到最高的带宽呢?
答案是:可能非常困难。以 Amazon CLI 为例,默认情况下,使用 Amazon s3 cp 命令下载 S3 上的对象能够达到几百 MB/s 的级别。
很多客户会有疑问,为什么亚马逊云科技自己提供的工具不能提供极限的性能?
这里需要特别说明:
Amazon CLI 提供了对亚马逊云科技所有服务 API 调用的命令行工具,针对 S3 这个服务,不但提供了相对底层,针对每个 S3 的 API 的命令行工具 (Amazon s3api) ,还进行了高级功能的封装 (Amazon s3) ,在 Amazon S3 命令集中实现了诸如目录同步等高级功能,因此 Amazon CLI 的重点在于提供简便高效的命令行工具,帮助客户轻松完成对亚马逊云科技服务的管理工作,并且工具自身能够快速迭代,紧跟亚马逊云科技新服务新特性的发布,而从 S3 上高性能下载数据,并非 Amazon CLI 的首要目标。
其次,Amazon CLI 基于 python 语言实现,python 在多线程并发存在一定的局限性 ,接下来我们会详述。
当然通过调整一些 Amazon CLI 的配置,我们还是可以让 Amazon CLI 的下载速度更快。比如,调整 CLI 的并发参数(默认10):
aws configure set default.s3.max_concurrent_requests 100
下载速度得到很大提升,详细可以参考: https://docs.aws.amazon.com/cli/latest/topic/s3-config.html?trk=cndc-detail
同时,采用多个 Amazon CLI 进程同时运行,并行下载多个对象,这也是平时我们常用的方法,同样能够提高整体的下载速率。在大部分场景下,如我们前面所述进程级的并发已经可以满足应用的需要。
再来谈谈程序员们接触最多的 Amazon SDK,亚马逊云科技为所有的服务提供了丰富的计算语言 SDK 的支持,Amazon SDK 是对亚马逊云科技服务 API 的特定计算机语言的接口封装和实现,并提供了一些高级的功能简化开发人员的使用,但 SDK 需要维护自身的兼容性,并考虑对语言更广泛的支持,因此 SDK 通常不提供程序的运行时 (runtime) 、I/O 模型、线程模型等这些对极致性能至关重要的部分,这部分需要依赖程序员自己来实现。
说到这里,要实现一个能够逼近线速下载的高性能应用的确不是一件很容易的事情,对于10万兆网络来说,普通应用使用的线程模型和 I/O 模型已经没法来应付了。接下去出场的是真正的主角:Amazon Common Runtime (CRT) 为了帮助我们的客户构建高性能的应用,亚马逊云科技提供的一套完整功能的应用基础库 Amazon Common Runtime (CRT)。
https://docs.aws.amazon.com/sdkref/latest/guide/common-runtime.html?trk=cndc-detail C 语言实现、模块化设计、Event Loop、线程/同步原语、内存管理等等。
Amazon CRT 提供了构建一个高性能应用所需的一切轮子,并且基于这些基础的底层库,Amazon CRT 还重新实现应用经常会用到的模块, 包括 http 协议、checksum 校验算法、mqtt 协议、S3 协议等,为了提供更大的使用灵活性,Amazon CRT 也提供了与其他编程语言的 Bindings(语言接口绑定),目前已经集成的语言包括:C++, Java, python, ruby, nodejs, swift, c#, php, Kotlin,客户可以在 Amazon CRT 之上构建自己的高性能应用客户端或者服务端。
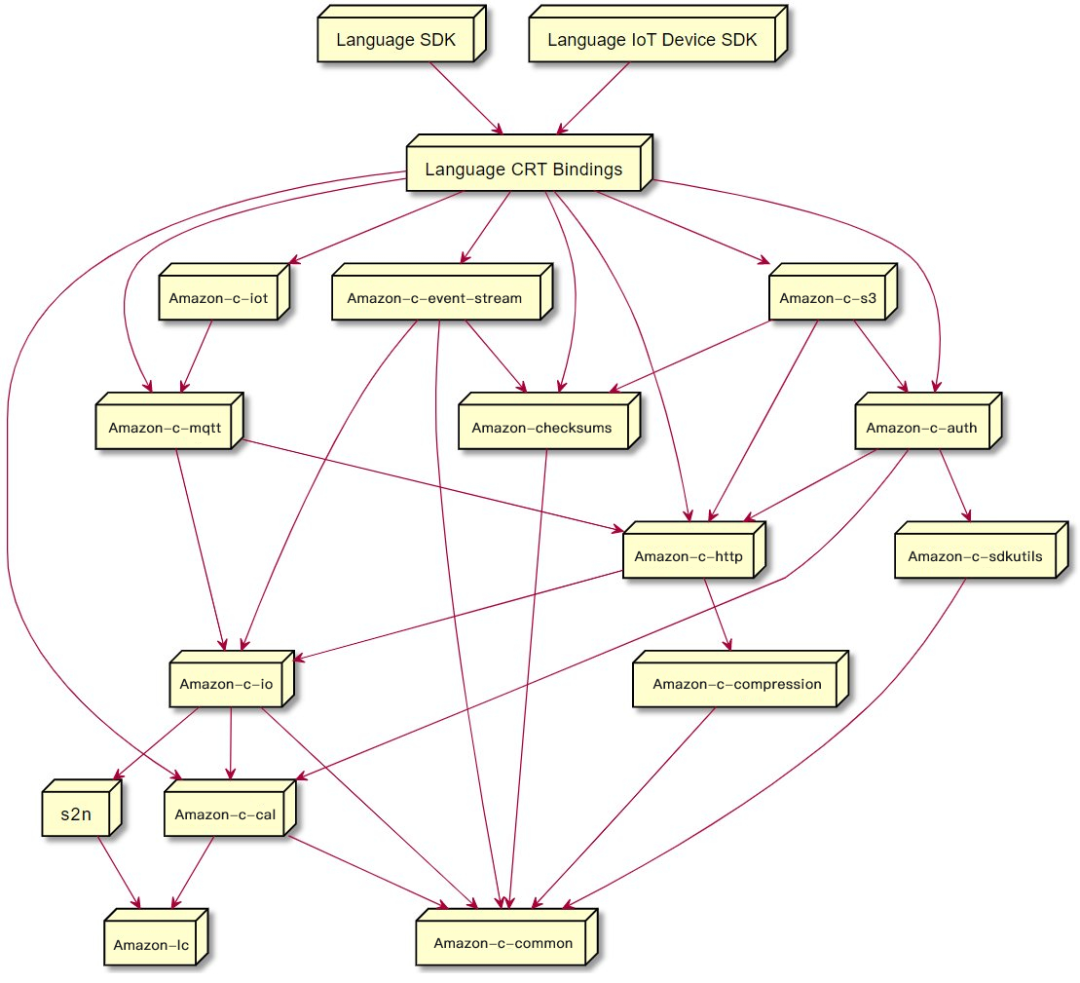
图:Amazon CRT 模块结构 您可能会问:为什么没有看到目前最火热两门高性能语言 Rust 与 Go?
其实 FFI for Amazon CRT(Rust 语言绑定)已经有了,只是目前完成集成的功能还比较有限。总的来说,Rust 和 Go 在语言特性上已经提供高性能应用所必需的并发处理、同步原语等机制,为这两种语言提供一个高性能应用框架集成的迫切性并没有这么高,接下去的演示中我们也会使用亚马逊云科技原生的 Rust SDK 来实现对 S3 数据的并发下载来做对比。
基于上面一系列的原因,为了突破现有应用框架带来的瓶颈,我们选择使用 Amazon CRT 来构建一个高性能的 S3 下载程序。
接下去,请各位绑好安全带,开启我们的100 Gbps 极速高性能之旅吧!
为了达到100 Gbps 的目标,我们选择 c5n.18xlarge 的 EC2 实例,在 EC2 实例家族中带 n 的实例都具有更高的网络性能,这款 c5n.18xlarge 的网络性能就可以达到100 Gbps,它的基本配置为:

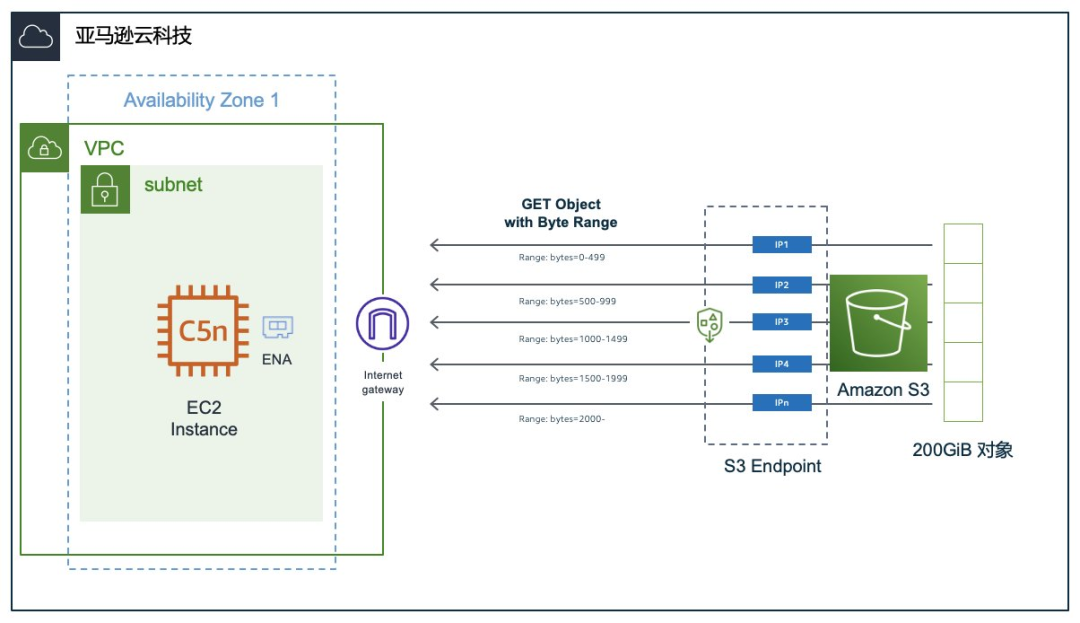
图:完整的验证架构 使用 Amazon CRT 来构建一个高并发 S3 下载程序的基本逻辑和示例代码可以在 Amazon CRT 的 samples 里找到: https://github.com/awslabs/aws-c-s3/tree/main/samples/s3?trk=cndc-detail
为了达到我们的测试目标,即获得最高的下载速率,我们基于 Amazon CRT 构建了一个特殊版本的测试程序,主要的不同有:
- 取消了数据下载后落盘的动作,避免数据落盘成为测试的瓶颈。
- 在每个分片下载完成后,记录下载完成的时间和完成的下载总量,用于计算下载所花的时间。
- 参数化分片大小和并发数量,用以调整以获得最高的性能。
此外,
这里有一个小细节,我们前面提到,通过使用多个 S3 Endpoint IP 地址来分散 S3 的请求压力,Amazon CRT 其实也考虑到了这个问题,Amazon CRT 实现了一个 host resolver 模块,可以用来解析并缓存同一个域名的多个 A 记录,供应用在执行中循环使用,这个动作叫做 DNS 预热。
进行 DNS 预热需要花一定的时间,而我们的验证程序希望能每次快速执行,快速验证并调整各种参数来比较结果,因此,我们的验证代码没有使用 Amazon CRT 的 host resolver,而是在测试实例上通过代码预先获取了一定数量的 S3 Endpoint 的 A 记录列表,并通过 dnsmasq 在本机提供域名解析服务的方式实现地址解析。但这并非生产环境中的最佳实践,作为一个大规模的云服务,S3 随时可能调整对外服务的 IP 地址,因此,实际应用当中请尽量从 DNS 服务器获取最新的 A 记录,避免某些 IP 地址失效影响应用正常执行。
介绍到此完毕,let’s go build ! 完整的验证代码如下:
#include <fcntl.h>
#include <unistd.h>
#include <aws/auth/credentials.h>
#include <aws/common/condition_variable.h>
#include <aws/common/mutex.h>
#include <aws/common/zero.h>
#include <aws/io/channel_bootstrap.h>
#include <aws/io/event_loop.h>
#include <aws/io/logging.h>
#include <aws/http/request_response.h>
#include <aws/s3/s3.h>
#include <aws/s3/s3_client.h>
#include <aws/common/private/thread_shared.h>
#include <aws/common/clock.h>
#define TEST_REGION "ap-northeast-1"
#define TEST_S3_EP "testbucket.s3.ap-northeast-1.amazonaws.com"
#define TEST_MAIN_EP "s3.ap-northeast-1.amazonaws.com"
#define TEST_FILE "200G_test.file"
#define TEST_RESULT_FILE "test_stats.result"
#define TEST_RANGE_SIZE 8 * 1024 * 1024
struct perf_item {
uint64_t ns;
uint64_t len;
} __attribute__((packed, aligned(8)));
static const struct aws_byte_cursor g_host_header_name = AWS_BYTE_CUR_INIT_FROM_STRING_LITERAL("Host");
struct app_ctx {
struct aws_allocator *allocator;
struct aws_s3_client *client;
struct aws_credentials_provider *credentials_provider;
struct aws_client_bootstrap *client_bootstrap;
struct aws_logger logger;
struct aws_mutex mutex;
struct aws_condition_variable c_var;
bool execution_completed;
struct aws_signing_config_aws signing_config;
const char *region;
enum aws_log_level log_level;
bool help_requested;
void *sub_command_data;
size_t expected_transfers;
size_t completed_transfers;
};
struct transfer_ctx {
struct aws_s3_meta_request *meta_request;
struct app_ctx *app_ctx;
struct aws_atomic_var bytes_done;
struct aws_atomic_var index;
struct perf_item *stats;
};
void s_get_request_finished(
struct aws_s3_meta_request *meta_request,
const struct aws_s3_meta_request_result *meta_request_result,
void *user_data) {
struct transfer_ctx *transfer_ctx = user_data;
struct perf_item *items = transfer_ctx->stats;
int i = 0;
uint32_t x = aws_atomic_load_int(&transfer_ctx->index);
uint64_t total_ns = last - first;
double total_ms = total_ns / 1000.0 / 1000.0;
printf("first: %ld, last: %ld, total ms: %.2lf\n", first, last, total_ms);
ssize_t total_bytes = aws_atomic_load_int(&transfer_ctx->bytes_done);
double gbps = ((total_bytes / total_ms) * 1000) * 8 / 1000 / 1000 / 1000;
printf("total bytes downloaded: %ld, line speed: %.2lf Gbps\n", total_bytes, gbps);
/* write test stats */
int fd;
fd = open(TEST_RESULT_FILE, O_CREAT | O_TRUNC | O_WRONLY);
write(fd, items, sizeof(struct perf_item) * x);
close(fd);
transfer_ctx->app_ctx->completed_transfers++;
aws_condition_variable_notify_one(&transfer_ctx->app_ctx->c_var);
aws_s3_meta_request_release(transfer_ctx->meta_request);
aws_mem_release(transfer_ctx->app_ctx->allocator, transfer_ctx->stats);
aws_mem_release(transfer_ctx->app_ctx->allocator, transfer_ctx);
return;
}
int s_get_body_callback(
struct aws_s3_meta_request *meta_request,
const struct aws_byte_cursor *body,
uint64_t range_start,
void *user_data) {
struct transfer_ctx *transfer_ctx = user_data;
uint64_t now;
size_t index;
aws_high_res_clock_get_ticks(&now);
index = aws_atomic_fetch_add(&transfer_ctx->index, 1);
(transfer_ctx->stats)[index].ns = now;
(transfer_ctx->stats)[index].len = body->len;
aws_atomic_fetch_add(&transfer_ctx->bytes_done, body->len);
return AWS_OP_SUCCESS;
}
bool s_are_all_transfers_done(void *arg) {
struct app_ctx *app_ctx = arg;
return app_ctx->expected_transfers == app_ctx->completed_transfers;
}
int s3_get(struct app_ctx *app_ctx, struct aws_s3_client *client) {
char source_endpoint[1024];
AWS_ZERO_ARRAY(source_endpoint);
sprintf(source_endpoint, TEST_S3_EP);
char main_endpoint[1024];
AWS_ZERO_ARRAY(main_endpoint);
sprintf(main_endpoint, TEST_MAIN_EP);
struct aws_byte_cursor slash_cur = aws_byte_cursor_from_c_str("/");
struct aws_byte_cursor keyname = aws_byte_cursor_from_c_str(TEST_FILE);
struct aws_byte_cursor *key = &keyname;
struct transfer_ctx *xfer_ctx = aws_mem_calloc(app_ctx->allocator, 1, sizeof(struct transfer_ctx));
xfer_ctx->app_ctx = app_ctx;
xfer_ctx->stats = aws_mem_calloc(app_ctx->allocator, 1000000, sizeof(struct perf_item));
aws_atomic_init_int(&xfer_ctx->bytes_done, 0);
aws_atomic_init_int(&xfer_ctx->index, 0);
struct aws_s3_meta_request_options request_options = {
.user_data = xfer_ctx,
.signing_config = &app_ctx->signing_config,
.type = AWS_S3_META_REQUEST_TYPE_GET_OBJECT,
.finish_callback = s_get_request_finished,
.body_callback = s_get_body_callback,
.headers_callback = NULL,
.shutdown_callback = NULL,
.progress_callback = NULL,
};
struct aws_http_header host_header = {
.name = g_host_header_name,
.value = aws_byte_cursor_from_c_str(source_endpoint),
};
struct aws_http_header accept_header = {
.name = aws_byte_cursor_from_c_str("accept"),
.value = aws_byte_cursor_from_c_str("*/*"),
};
struct aws_http_header user_agent_header = {
.name = aws_byte_cursor_from_c_str("user-agent"),
.value = aws_byte_cursor_from_c_str("AWS common runtime command-line client"),
};
request_options.message = aws_http_message_new_request(app_ctx->allocator);
aws_http_message_add_header(request_options.message, host_header);
aws_http_message_add_header(request_options.message, accept_header);
aws_http_message_add_header(request_options.message, user_agent_header);
aws_http_message_set_request_method(request_options.message, aws_http_method_get);
struct aws_byte_buf path_buf;