
2023数据采集与融合技术实践作业3
2023数据采集与融合技术实践作业3
作业1
- 要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn/(要求:指定--个网站,爬取这个网站中的所有的所有图片,例如中国气象网)
- 输出信息:将下载的url信息在控制台输出,并将下载的图片存储在images子文件夹中,并给出截图
- code
myspider代码
import scrapy
from demo1.items import picItem
from bs4 import UnicodeDammit
class MySpider(scrapy.Spider):
name = "mySpider1"
start_urls = 'http://www.weather.com.cn/'
def start_requests(self):
url = MySpider.start_urls
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
pics = selector.xpath("//img[@src]")
for pic in pics:
item = picItem()
item['url'] = pic.xpath("./@src").extract_first()
print(item['url'])
yield item
except Exception as err:
print(err)
items代码
import scrapy
class picItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
url = scrapy.Field()
pass
settings代码
ITEM_PIPELINES = {
"demo1.pipelines.pic_urlPipeline": 300,
# "demo1.pipelines.stockPipeline": 300,
# "demo1.pipelines.currencyPipeline": 300,
}
pipelines代码
class pic_urlPipeline:
count = 0
def process_item(self, item, spider):
try:
img_url = item['url']
pic_urlPipeline.count+=1
with open(f".\pic_ofWeather\{pic_urlPipeline.count}.{img_url.split('.')[-1]}", "wb") as f:
content = requests.get(img_url)
f.write(content.content)
print("下载成功!")
except Exception as err:
print(err)
return item
run代码
from scrapy import cmdline
cmdline.execute("scrapy crawl mySpider1 -s LOG_ENABLED=False".split())
- 若实现多线程则将settings.py中
CONCURRENT_REQUESTS = 32注释取消掉 - github链接🔗:https://gitee.com/Alynyn/crawl_project/tree/master/作业3
- 运行结果截图:
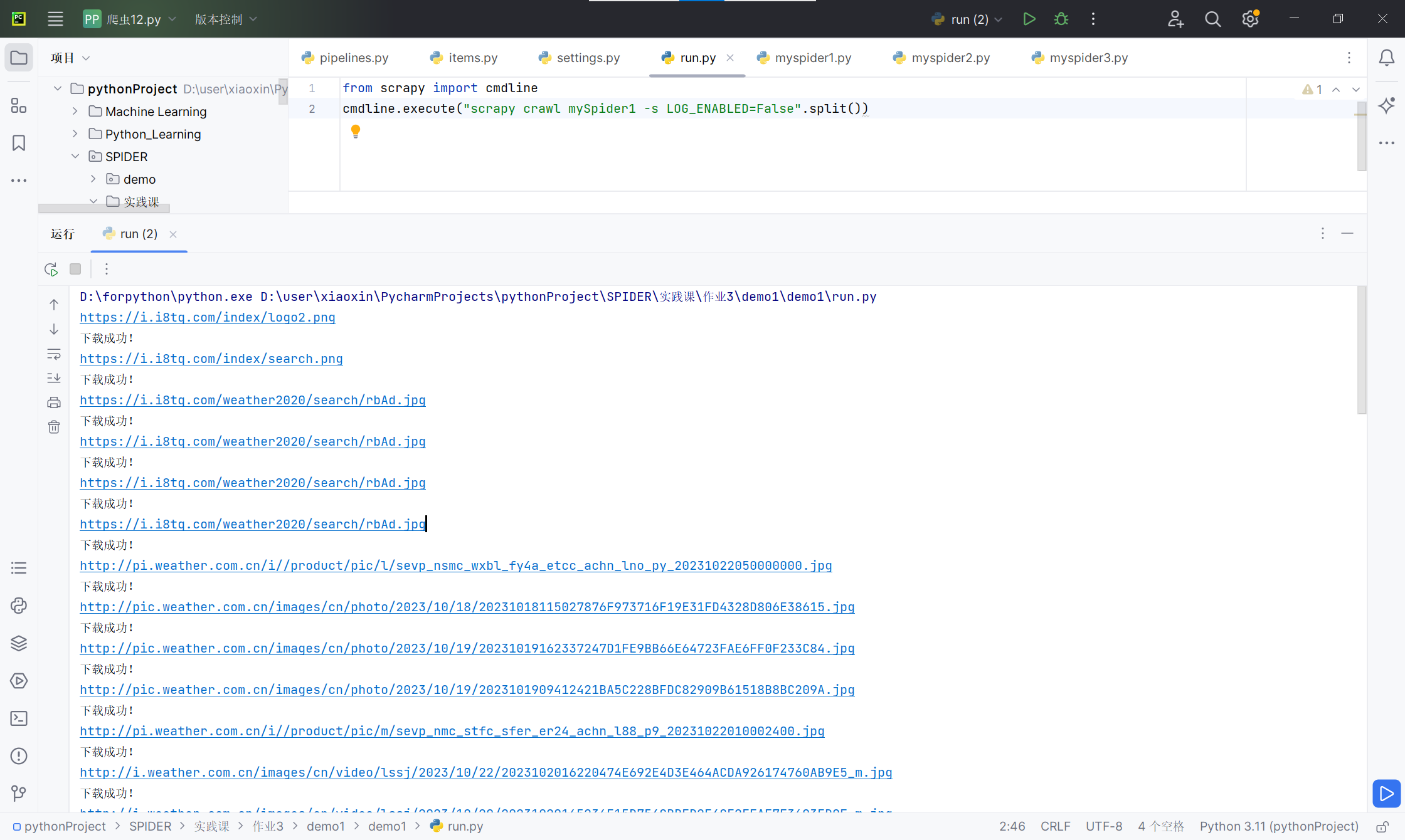
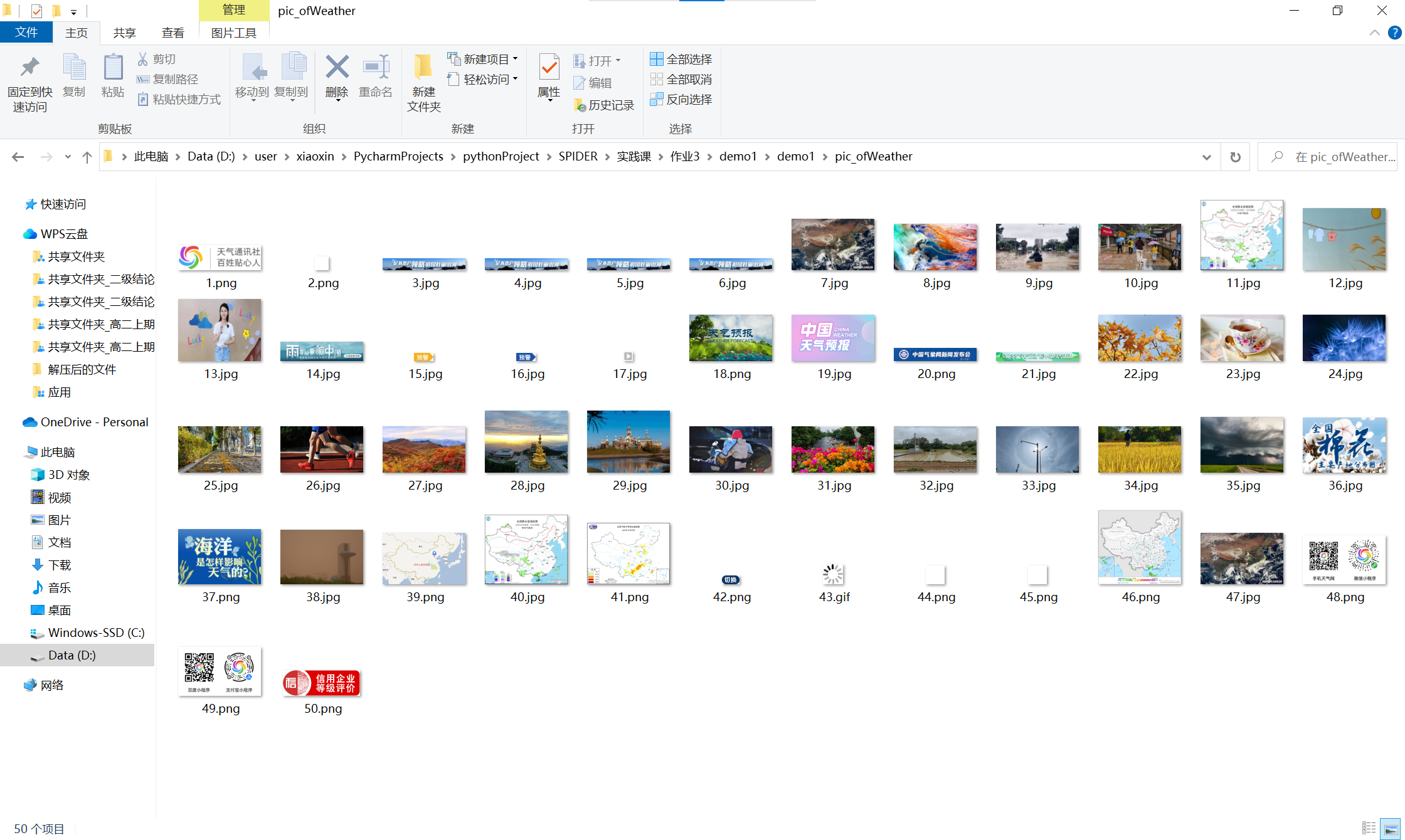
- 实验心得:对利用scrapy框架进行爬虫有更深入的了解,同时可以利用该框架进行更多题目的爬虫,进行调整即可,省略较多繁琐步骤。
作业2
- 要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网: https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/ - 输出信息:MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计

- code
myspider代码
import scrapy
from demo1.items import stockItem
from bs4 import UnicodeDammit
import requests
class MySpider(scrapy.Spider):
name = "mySpider2"
start_urls = ('http://quote.eastmoney.com/center/gridlist.html#hs_a_board')
def start_requests(self):
url = MySpider.start_urls
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
try:
url = 'http://88.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112404431204739941166_1697868056653&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f2,f3,f4,f5,f6,f7,f12,f14,f15,f16,f17,f18&_=1697868056654'
html = requests.get(url, timeout=30)
html.raise_for_status()
html.encoding = html.apparent_encoding
html = html.text
answer = html.split('[')[1].split(']')[0]
answer = answer.split('}')
# print(answer)
data = []
for i in answer:
if i != ',' and i != ' ':
data.append(i.strip(' ').strip(',') + '}')
else:
continue
data.pop(-1) # 去除结尾无用信息
for i in data:
messege = eval(i) # str -> dict
# print(messege)
item = stockItem()
item['code'] = messege['f12']
item['title'] = messege['f14']
item['rec_price'] = messege['f2']
item['updown_percent'] = str(messege['f3'])+'%'
item['updown_sum'] = messege['f4']
item['deal_amount'] = messege['f5']
item['deal_sum'] = messege['f6']
item['swing'] = str(messege['f7'])+'%'
item['max'] = messege['f15']
item['min'] = messege['f16']
item['today'] = messege['f17']
item['yesterday'] = messege['f18']
print(item)
yield item
except Exception as err:
print('')
items代码
class stockItem(scrapy.Item):
code = scrapy.Field() #代码
title = scrapy.Field() #名称
rec_price = scrapy.Field() #最新报价
updown_percent = scrapy.Field() #涨跌幅
updown_sum = scrapy.Field() #涨跌额
deal_amount = scrapy.Field() #成交量
deal_sum = scrapy.Field() #成交额
swing = scrapy.Field() #振幅
max = scrapy.Field() #最高
min = scrapy.Field() #最低
today = scrapy.Field() #今开
yesterday = scrapy.Field() #昨放
pass
settings代码
ITEM_PIPELINES = {
# "demo1.pipelines.pic_urlPipeline": 300,
"demo1.pipelines.stockPipeline": 300,
# "demo1.pipelines.currencyPipeline": 300,
}
pipelines代码
class stockPipeline:
def open_spider(self,spider):
self.mydb = pymysql.connect(
host="192.168.91.1",
port=3306,
user="root",
password="123456",
database="spider",
charset='utf8'
)
self.cursor = self.mydb.cursor()
self.cursor.execute('''CREATE TABLE IF NOT EXISTS stock
(code VARCHAR(256),
title VARCHAR(256),
rec_price VARCHAR(256),
updown_percent VARCHAR(256),
updown_sum VARCHAR(256),
deal_amount VARCHAR(256),
deal_sum VARCHAR(256),
swing VARCHAR(256),
max VARCHAR(256),
min VARCHAR(256),
today VARCHAR(256),
yesterday VARCHAR(256)
)''')
self.mydb.commit()
def process_item(self, item, spider):
sql="insert into stock values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
self.cursor.execute(sql,(item.get("code"),item.get("title"),item.get("rec_price"),item.get("updown_percent"),item.get("updown_sum"),item.get("deal_amount"),item.get("deal_sum"),item.get("swing"),item.get("max"),item.get("min"),item.get("today"),item.get("yesterday")))
self.mydb.commit()
return item
def close_spider(self,spider):
self.mydb.close()
run代码
from scrapy import cmdline
cmdline.execute("scrapy crawl mySpider2 -s LOG_ENABLED=False".split())
- github链接🔗:https://gitee.com/Alynyn/crawl_project/tree/master/作业3
- 运行结果截图:
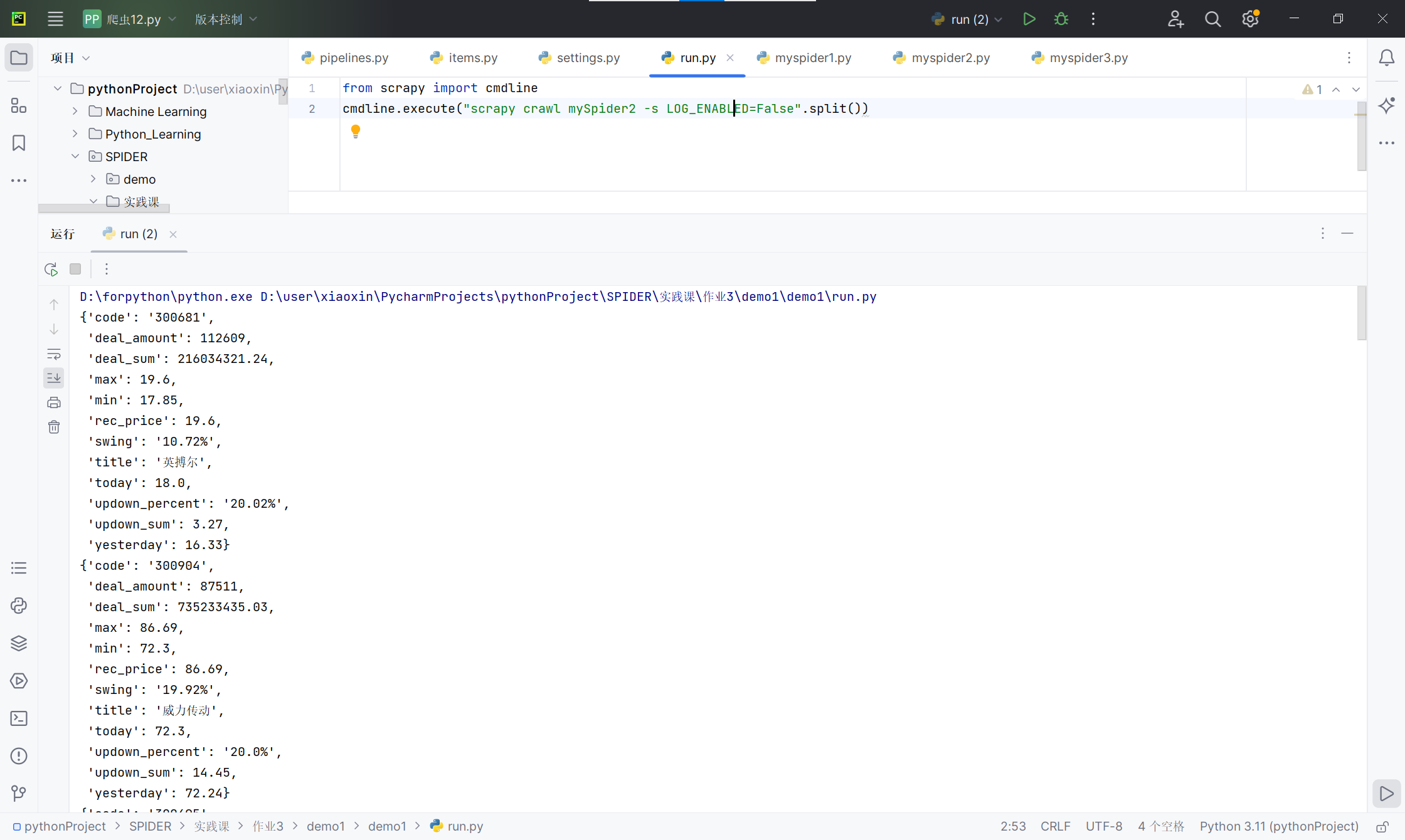
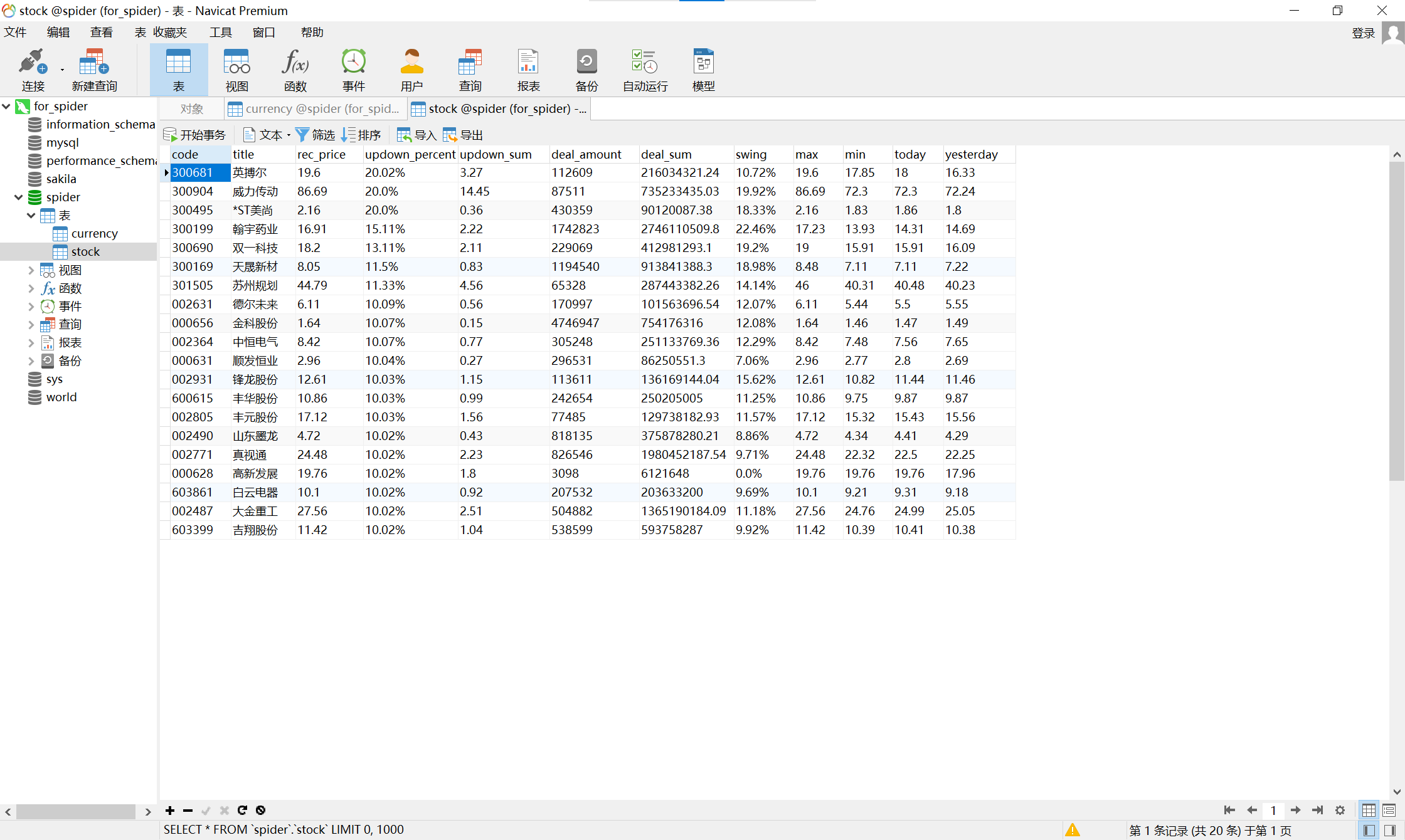
- 实验心得:通过直接获取网页html进行的scrapy爬虫不一定会成功,需要借鉴上次作业进行抓包处理。
作业3
- 要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:招商银行网:https://www.boc.cn/sourcedb/whpj/ - 输出信息:(MySQL数据库存储和输出格式)

- code
myspider代码
import scrapy
from demo1.items import currencyItem
from bs4 import UnicodeDammit
class MySpider(scrapy.Spider):
name = "mySpider3"
start_urls = 'https://www.boc.cn/sourcedb/whpj/'
def start_requests(self):
url = MySpider.start_urls
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
trs = selector.xpath("//table/tr")
trs = trs[2:len(trs)-2]
for tr in trs:
item = currencyItem()
# print(tr.xpath("./td[1]/text()").extract())
item['currency'] = tr.xpath("./td[1]/text()").extract()
item['TBP'] = tr.xpath("./td[2]/text()").extract()
item['CBP'] = tr.xpath("./td[3]/text()").extract()
item['TSP'] = tr.xpath("./td[4]/text()").extract()
item['CSP'] = tr.xpath("./td[5]/text()").extract()
item['Time'] = tr.xpath("./td[8]/text()").extract()
print(item)
yield item
except Exception as err:
print(err)
items代码
class currencyItem(scrapy.Item):
currency = scrapy.Field() #货币名称
TBP = scrapy.Field() #现汇买入价
CBP = scrapy.Field() #现钞买入价
TSP = scrapy.Field() #现汇卖出价
CSP = scrapy.Field() #现钞卖出价
Time = scrapy.Field() #发布时间
pass
settings代码
ITEM_PIPELINES = {
# "demo1.pipelines.pic_urlPipeline": 300,
# "demo1.pipelines.stockPipeline": 300,
"demo1.pipelines.currencyPipeline": 300,
}
pipelines代码
class currencyPipeline:
def open_spider(self,spider):
self.mydb = pymysql.connect(
host="192.168.91.1",
port=3306,
user="root",
password="123456",
database="spider",
charset='utf8'
)
self.cursor = self.mydb.cursor()
self.cursor.execute('''CREATE TABLE IF NOT EXISTS currency
(Currency VARCHAR(256),
TBP VARCHAR(256),
CBP VARCHAR(256),
TSP VARCHAR(256),
CSP VARCHAR(256),
Times VARCHAR(256)
)''')
self.mydb.commit()
def process_item(self, item, spider):
print(item.get("currency"))
sql="INSERT INTO currency (Currency,TBP,CBP,TSP,CSP,Times) VALUES (%s,%s,%s,%s,%s,%s)"
self.cursor.execute(sql,(item.get("currency"),item.get("TBP"),item.get("CBP"),item.get("TSP"),item.get("CSP"),item.get("Time")))
self.mydb.commit()
return item
def close_spider(self,spider):
self.cursor.close()
self.mydb.close()
run代码
from scrapy import cmdline
cmdline.execute("scrapy crawl mySpider3 -s LOG_ENABLED=False".split())
-
github链接🔗:https://gitee.com/Alynyn/crawl_project/tree/master/作业3
-
运行结果截图:
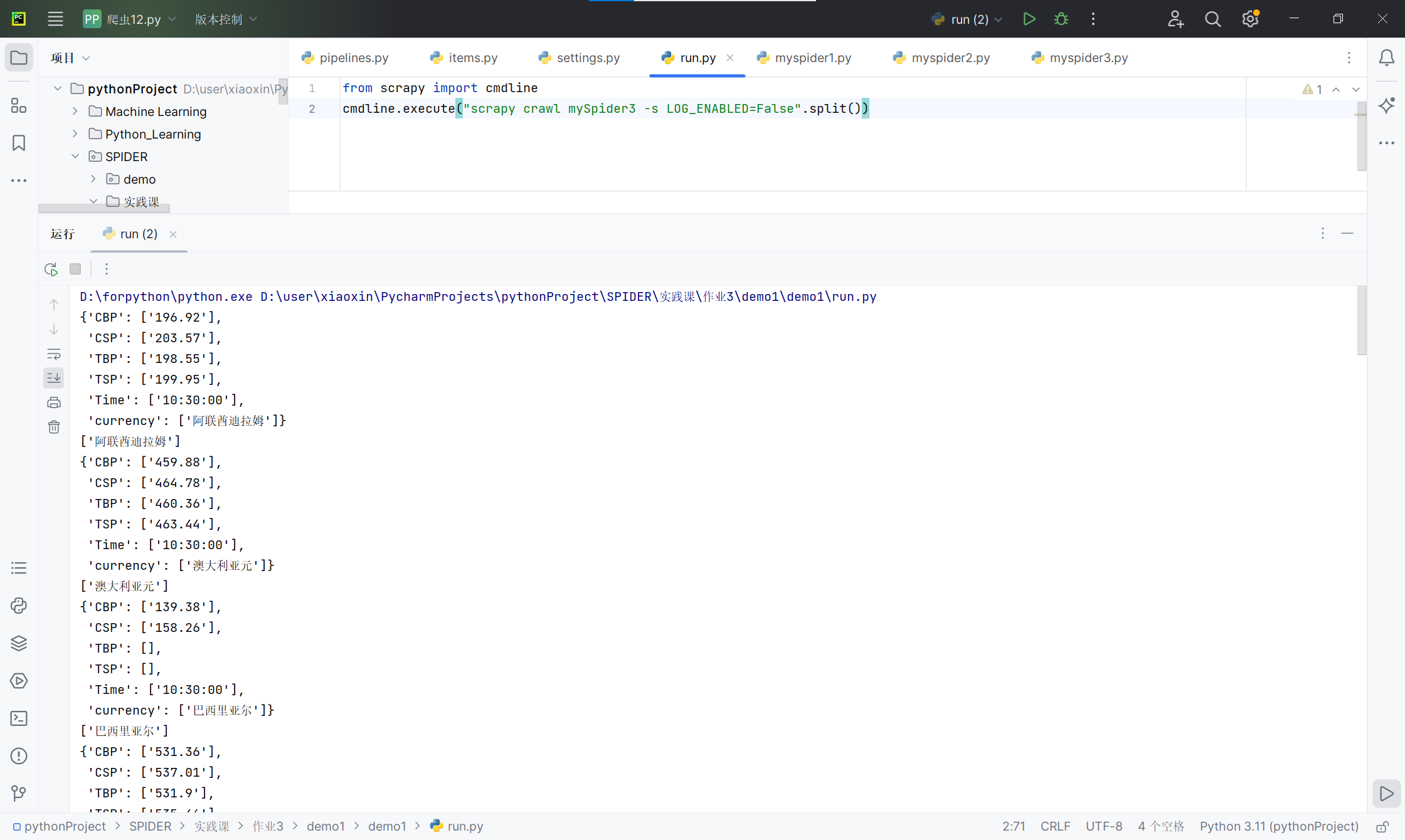
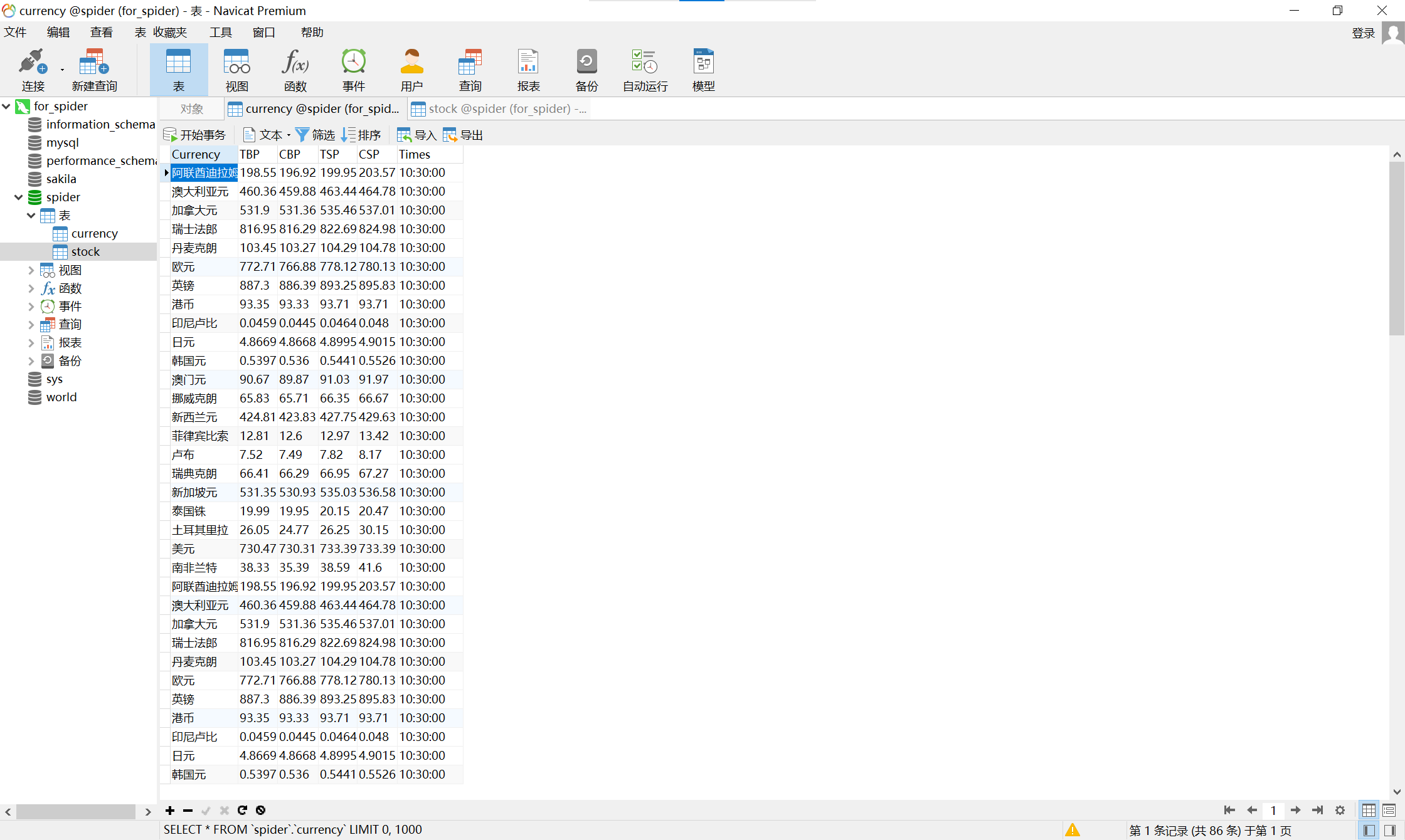
-
实验心得:对关于pycharm中通过pymysql对mysql数据库的调用有了更深的理解,通过实践进行学科相关知识的巩固!
