LangChain+Qwen1.5MoE国内开源大模型调用知识库QuickStart
在这个快速入门教程中,我们将指导您如何:
- 安装并配置LangChain、LangSmith和LangServe。
- 使用LangChain中最基础且常用的组件:提示模板、模型和输出解析器。
- 应用LangChain表达式语言(LangChain Expression Language),这是构建LangChain的基础协议,用于实现组件链式调用。
- 利用LangChain构建一个简易应用程序。
- 利用LangSmith对您的应用程序进行跟踪调试。
- 通过LangServe部署并运行您的应用程序。
以上涵盖了诸多内容,现在让我们深入探索吧。
LangSmith
使用LangChain构建的许多应用程序将包含多个步骤,并多次调用LLM调用。随着这些应用程序变得越来越复杂,能够检查您的链或代理内部到底发生了什么变得至关重要。最好的方法是与LangSmith合作。
请注意,LangSmith不是必须的,但它很有帮助。如果您确实想使用LangSmith,在您在上面的链接注册之后,请确保设置您的环境变量以开始记录跟踪:
export LANGCHAIN_TRACING_V2="true"
export LANGCHAIN_API_Key="..."
import os
# 设置环境变量
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGCHAIN_API_Key'] = 'ls__fb7e5766809148aab8dd1d50cc8b13e4'
使用LangChain构建
LangChain使得能够连接外部数据和计算源到预训练语言模型(LLMs)。在这个快速入门教程中,我们将了解几种实现方法。我们从一个简单的LLM链开始,它仅依赖于提示模板中的信息来响应。接下来,我们将构建一个检索链,该链从单独的数据库获取数据,并将其传递到提示模板中。然后,我们将添加聊天记录,以创建会话检索链。这使您可以以聊天方式与这个LLM交互,以便它能记住先前的问题。最后,我们将构建一个代理,该代理利用LLM来决定是否需要获取数据来回答问题。我们将对这些内容进行概述,但所有这些都包含很多细节!我们会链接到相关的文档供您深入了解。
LLM Chain
我们首先介绍如何使用通过API提供的模型,如OpenAI,以及使用Ollama等集成工具访问本地开源模型。
OpenAI
- 首先,确保已安装OpenAI集成包。
pip install langchain-openai
import os
from langchain_openai import ChatOpenAI
# 设置url xinference的url加上v1
os.environ["OPENAI_BASE_URL"] = "http://127.0.0.1:9111/v1"
# 设置密钥
os.environ["OPENAI_API_KEY"] = "not empty"
llm = ChatOpenAI(model="qwen1.5moe-lKXA7djv", temperature="0.3")
llm.invoke("中国的首都是哪里")
AIMessage(content='中国的首都是北京。', response_metadata={'token_usage': {'completion_tokens': 6, 'prompt_tokens': 23, 'total_tokens': 29}, 'model_name': 'qwen1.5moe-lKXA7djv', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None}, id='run-2deb0885-96f2-4e34-8043-8b726e655b8b-0')
HuggingFace
离线加载模型
from langchain_community.llms.huggingface_pipeline import HuggingFacePipeline
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
import torch
# 检查是否有可用的GPU
if torch.cuda.is_available():
device = torch.device("cuda")
print(f"有 {torch.cuda.device_count()} 个GPU可用.")
else:
device = torch.device("cpu")
print("使用CPU.")
model_dir = '/home/jupiter/model/qwen/Qwen1___5-1___8B'
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
torch_dtype="auto",
device_map="auto"
)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_length=512,
temperature=0.8,
top_p=1,
repetition_penalty=1.15
)
llm = HuggingFacePipeline(pipeline=pipe)
安装并初始化了您选择的语言模型后,我们可以尝试使用它!让我们询问它什么是LangSmith——这不在其训练数据中,所以它的回答可能不会很准确。
llm.invoke("how can langsmith help with testing?")
AIMessage(content="Langsmith can help with testing in several ways:\n\n1. **Code Review**: Langsmith's code review feature allows developers to review and comment on code changes, which can help catch bugs and ensure code quality. This can be particularly useful during the testing phase to identify potential issues before they make it to production.\n\n2. **Code Coverage Analysis**: Langsmith can provide detailed code coverage reports, which show how much of your code is being tested. This helps ensure that all code paths are being exercised during testing, reducing the risk of undetected bugs.\n\n3. **Test Case Management**: Langsmith can help manage and track test cases, ensuring that all necessary tests are being run and that no important tests are being skipped. This can be especially helpful for large projects with many tests.\n\n4. **Automated Testing**: Langsmith supports various automated testing frameworks, such as JUnit, pytest, and Selenium, which can help automate the testing process and reduce the manual effort required.\n\n5. **Test Data Management**: Langsmith can help manage and generate test data, ensuring that the test environment matches the production environment as closely as possible. This can help prevent issues caused by differences in data.\n\n6. **Performance Testing**: Langsmith can help with performance testing, including load testing, stress testing, and endurance testing, to ensure that your application can handle the expected load and perform well under stress.\n\n7. **Integration Testing**: Langsmith can help with integration testing, ensuring that different components of your application work together as expected.\n\n8. **Debugging and Error Tracking**: Langsmith's debugging tools can help identify issues in your code, making it easier to fix bugs and ensure that they are caught early in the development process.\n\n9. **Code Formatting and Style Consistency**: Langsmith can enforce coding standards and style guidelines, ensuring that your code is consistent and easy to read, which can help catch bugs and improve maintainability.\n\n10. **Continuous Integration and Continuous Deployment (CI/CD)**: Langsmith can integrate with CI/CD tools, such as Jenkins, to automatically run tests as part of your build process, ensuring that new code changes don't introduce bugs.\n\nIn summary, Langsmith can help with various aspects of testing, from managing test cases to ensuring code quality, and can integrate with other tools to provide a comprehensive testing solution for your project.", response_metadata={'token_usage': {'completion_tokens': 475, 'prompt_tokens': 27, 'total_tokens': 502}, 'model_name': 'qwen1.5moe', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None}, id='run-1cde7d88-91f8-4919-8b27-867fb620c402-0')
我们还可以通过提示模板引导它的回复。提示模板将原始用户输入转换为更适合输入给LLM的形式。
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", "You are world class technical documentation writer."),
("user", "{input}")
])
这段代码定义了一个简单的提示模板,其中包含一条系统消息和一条用户消息的模板。在实际应用中,可以根据需要调整模板中的对话内容。
现在我们可以将它们结合到一个简单的LLM链中:
chain = prompt | llm
现在调用该链并询问同一个问题。它仍然不知道答案,但它应该能以更符合技术作家规范的方式进行回应!
print(chain.invoke({"input": "how can langsmith help with testing?"}))
content="Langsmith is a platform that provides a wide range of language and AI capabilities, including testing. Here are a few ways Langsmith can help with testing:\n\n1. Automated Testing: Langsmith can assist in automating the testing process, including unit testing, integration testing, and regression testing. This can help ensure that your code is functioning as expected and that changes to the code don't break existing functionality.\n2. Code Review: Langsmith can analyze your code and provide feedback on potential issues, such as bugs, security vulnerabilities, and code quality. This can help you catch issues before they become bigger problems and improve the overall quality of your code.\n3. Performance Testing: Langsmith can help you test the performance of your application under different loads and conditions, which can help you optimize the speed and efficiency of your system.\n4. Test Automation: Langsmith can help you create and maintain test automation scripts, reducing the need for manual testing and ensuring consistent testing across different environments.\n5. Test Data Management: Langsmith can assist in generating test data, which is essential for testing complex systems and edge cases. This can help you create realistic test scenarios and avoid issues caused by incomplete or unrealistic test data.\n6. Test Case Management: Langsmith can help you manage your test cases, including organizing them, tracking their execution, and generating reports. This can help you keep track of the progress of your testing efforts and ensure that all necessary tests are being performed.\n7. API Testing: Langsmith can help you test APIs, ensuring that they are functioning correctly and that they meet the required specifications. This is particularly useful for testing APIs that are part of a larger system.\n\nBy leveraging Langsmith's testing capabilities, you can improve the quality of your code, reduce the time and effort required for testing, and ensure that your applications are robust and reliable." response_metadata={'token_usage': {'completion_tokens': 371, 'prompt_tokens': 29, 'total_tokens': 400}, 'model_name': 'qwen1.5moe-PqfiaYTI', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None} id='run-30c9e8fe-85be-461e-a354-2dddd940d71d-0'
ChatModel(因此也包括此链)的输出是消息格式。然而,通常处理字符串要方便得多。让我们添加一个简单的输出解析器,将聊天消息转换为字符串。
from langchain_core.output_parsers import StrOutputParser
output_parser = StrOutputParser()
接着,我们可以把这个解析器加入到之前创建的链中:
chain = prompt | llm | output_parser
这样,当我们再次调用它并提出同样的问题时,答案将会是以字符串形式呈现(而非ChatMessage)。
print(chain.invoke({"input": "how can langsmith help with testing?"}))
LangSmith can help with testing in several ways:
1. Automated Testing: LangSmith can generate automated tests for your code, which can help you catch bugs and regressions early in the development process. This can save you time and effort in the long run, as it allows you to focus on fixing issues rather than writing tests.
2. Code Review: LangSmith can review your code and provide feedback on potential issues, such as security vulnerabilities, performance problems, and code smells. This can help you improve the quality of your code and make it more maintainable.
3. Test Automation: LangSmith can help you set up a test automation framework that can run tests automatically on a regular basis, ensuring that your code continues to work as expected. This can save you time and reduce the risk of human error in the testing process.
4. Test Case Generation: LangSmith can generate test cases based on your documentation, helping you to create comprehensive and effective test plans. This can ensure that all aspects of your software are thoroughly tested and that no important functionality is overlooked.
5. Test Data Management: LangSmith can help you manage test data, including creating and organizing test data sets, and generating test data for different scenarios. This can help you ensure that your tests are as realistic as possible and that they cover a wide range of use cases.
Overall, LangSmith can help you improve the quality of your code and testing process by providing tools and services that automate and streamline the testing process, making it easier for you to catch bugs and ensure that your software is reliable and maintainable.
检索链(Retrieval Chain)
为了正确回答原问题("langsmith 如何帮助进行测试?"),我们需要为LLM提供更多的上下文。可以通过检索来做到这一点。检索在直接将大量数据传递给LLM时非常有用。然后,您可以使用检索器仅获取最相关的内容,并将其传递进去。
在这个过程中,我们将从检索器中检索相关文档,然后将这些文档传递给提示。检索器可以基于任何内容实现 - 一个SQL表、互联网等 - 但在这种情况下,我们将使用向量存储,并将其用作检索器。关于向量存储的更多信息,请参阅此文档。
首先,我们需要加载要索引的数据。为此,我们将使用WebBaseLoader。这需要安装BeautifulSoup。
pip install beautifulsoup4
之后,我们就可以导入并使用WebBase Player了。
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://docs.smith.langchain.com/user_guide")
docs = loader.load()
接下来,我们需要将其索引到向量存储中。这需要一些组件,即嵌入模型和向量存储。
对于嵌入模型,我们再次提供通过API访问或运行本地模型的示例。
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model='bge_large_zh_v1.5')
现在,我们可以使用此嵌入模型将文档录入向量数据库。为了简洁起见,我们将使用简单的本地向量数据库FAISS。
首先,我们需要安装用于此目的的所需软件包:
pip install faiss-cpu
然后就可以建立我们的索引
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter()
documents = text_splitter.split_documents(docs)
vector = FAISS.from_documents(documents, embeddings)
既然我们已经将这些数据通过向量数据库整理好了,我们将建立一个检索链。这个链会将一个接收到的问题,相关文档查找,然后把那些文档以及原问题传递给大型语言模型,指令它回答原问题。
首先,让我们设定一个将问题和检索到的文档一起生成答案的链。
from langchain.chains.combine_documents import create_stuff_documents_chain
prompt = ChatPromptTemplate.from_template("""Answer the following question based only on the provided context:
<context>
{context}
</context>
Question: {input}""")
document_chain = create_stuff_documents_chain(llm, prompt)
如果我们愿意的话,我们可以自己直接传递文档来运行:
from langchain_core.documents import Document
document_chain.invoke({
"input": "how can langsmith help with testing?",
"context": [Document(page_content="langsmith can let you visualize test results")]
})
'Based on the provided context, Langsmith can help with testing by allowing you to visualize test results. This means that it provides a graphical or interactive representation of the outcomes or statuses of tests, enabling users to easily understand and analyze the results. By visualizing the test results, it becomes simpler to identify patterns, track progress, and draw insights, which can be useful for debugging, assessing the effectiveness of test strategies, and making data-driven decisions in the testing process.'
但是,我们希望文档首先来自我们刚刚设置的检索器。这样,我们就可以使用检索器动态地选择最相关的文档,并为给定的问题传递这些文档。
from langchain.chains import create_retrieval_chain
retriever = vector.as_retriever()
retrieval_chain = create_retrieval_chain(retriever, document_chain)
我们现在可以调用这个链。这返回一个字典-来自LLM的响应位于答案键中
response = retrieval_chain.invoke({"input": "how can langsmith help with testing?"})
print(response["answer"])
# LangSmith offers several features that can help with testing:...
LangSmith is a platform for LLM (Large Language Model) application development, monitoring, and testing. It provides a variety of features to help with testing, including:
1. Tracing: LangSmith logs every application run, which can be used to create test cases or compare with other runs. This helps in tracking the performance of the application across multiple turns.
2. Feedback collection: When launching an application to a set of users, it's important to gather human feedback on the responses it's producing. LangSmith allows attaching feedback scores to logged traces, which can be filtered by specific tags and scores. This helps identify problematic responses and highlights edge cases.
3. Trace annotation: Users can send runs to annotation queues, where annotators can closely inspect interesting traces and annotate them with respect to different criteria. This is helpful for catching regressions across important evaluation criteria.
4. Adding runs to datasets: As the application progresses through the testing phase, LangSmith enables adding runs as examples to datasets, expanding test coverage on real-world scenarios. This is a key benefit in having a logging and evaluation system in the same platform.
5. Production monitoring: LangSmith provides monitoring charts to track key metrics over time, including latency, cost, and feedback scores. This helps ensure the application is delivering desirable results at scale.
6. Thread grouping: The platform provides a threads view that groups traces from a single conversation, making it easier to track the performance of the application across multiple turns.
7. Automation: LangSmith allows for near real-time processing and scoring of production traces, as well as sending traces to annotation queues or datasets. Automations can be defined with filter conditions, sampling rates, and actions.
8. Comparison view: When testing different versions of the application, it's essential to see if there are regressions with respect to initial test cases. LangSmith provides a user-friendly comparison view to track and diagnose test score regressions.
9. Playground: LangSmith offers a playground environment for rapid iteration and experimentation, allowing users to test different prompts and models quickly.
Overall, LangSmith helps with testing by providing a comprehensive platform for logging, tracking, and evaluating LLM application performance at different stages of development, from prototyping to production.
这个回答会非常精准
对话检索链(Conversation Retrieval Chain)
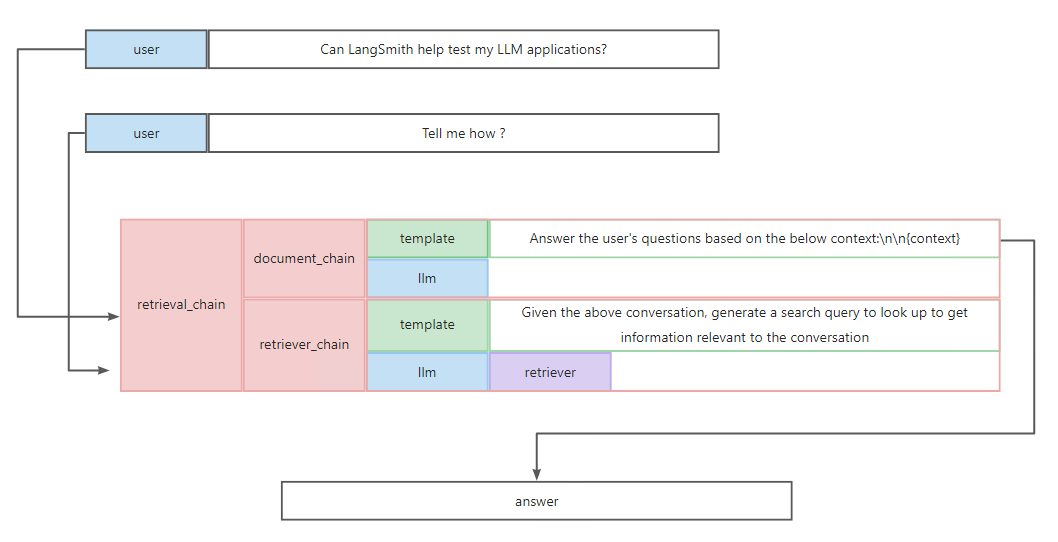
我们迄今为止创建的链条只能回答单个问题。人们正在开发的LLM的主要类型之一是聊天机器人。那么,我们如何将这个链条转换为能够回答后续问题的链条呢?
我们仍然可以使用create_retrieval_chain函数,但是需要进行两项更改:
- 检索方法现在不仅应针对最新输入工作,而应该考虑整个历史记录。
- 最终的LLM链也应考虑整个历史记录
更新检索
要更新检索,我们将创建一个新的链条。这个链条将接收最新输入(输入)和对话历史(chat_history),并使用LRMS生成一个搜索查询。
from langchain.chains import create_history_aware_retriever
from langchain_core.prompts import MessagesPlaceholder
# First we need a prompt that we can pass into an LLM to generate this search query
prompt = ChatPromptTemplate.from_messages([
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
("user", "Given the above conversation, generate a search query to look up to get information relevant to the conversation")
])
retriever_chain = create_history_aware_retriever(llm, retriever, prompt)
我们可以使用传入一个用户问后续问题的实例来进行测试。
from langchain_core.messages import HumanMessage, AIMessage
chat_history = [HumanMessage(content="Can LangSmith help test my LLM applications?"), AIMessage(content="Yes!")]
retriever_chain.invoke({
"chat_history": chat_history,
"input": "Tell me how"
})
你应该看到,这将返回关于LangSmith测试的信息。这是因为LLM生成了新的查询,将交互历史与后续问题结合在一起。
现在我们有了这个新的检索器,我们可以创建一个新链条,将这些检索到的文档考虑在内,继续我们的对话。
prompt = ChatPromptTemplate.from_messages([
("system", "Answer the user's questions based on the below context:\n\n{context}"),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
])
document_chain = create_stuff_documents_chain(llm, prompt)
retrieval_chain = create_retrieval_chain(retriever_chain, document_chain)
现在,我们可以进行全面测试:
chat_history = [HumanMessage(content="Can LangSmith help test my LLM applications?"), AIMessage(content="Yes!")]
retrieval_chain.invoke({
"chat_history": chat_history,
"input": "Tell me how"
})
我们可以看到这给出了一个连贯的答案--我们已经成功地将我们的检索链变成了聊天机器人!
Agent
到目前为止,我们已经创建了链式结构的例子,其中每一步都是预先知道的。最后,我们将创建一个代理,其中LLM将决定采取哪些步骤。
注:在本示例中,我们只展示如何使用OpenAI模型创建代理,因为本地模型的可靠性还不够。
建立代理的第一步是决定代理应具备哪些工具。对于这个示例,我们将向代理提供两种工具:
- 我们刚创建的检索器。这将使其能够轻松回答关于LangSmith的问题
- 一个搜索工具。这将使其能够轻松回答需要最新信息的问题。
首先,让我们为刚创建的检索器设置一个工具:
from langchain.tools.retriever import create_retriever_tool
retriever_tool = create_retriever_tool(
retriever,
"langsmith_search",
"Search for information about LangSmith. For any questions about LangSmith, you must use this tool!",
)
我们将使用的搜索工具是Tavily。这需要API密钥(他们有慷慨的免费级别)。在他们的平台上创建它后,您需要将其设置为环境变量:
export TAVILY_API_KEY=...
如果您不想设置API密钥,则可以跳过创建此工具。
from langchain_community.tools.tavily_search import TavilySearchResults
search = TavilySearchResults()
我们现在可以创建想要使用的工具列表:
tools = [retriever_tool, search]
有了这些工具,我们就可以创建一个代理来使用它们。我们将快速地进行,更深入地了解正在发生的事情,可以查看【代理入门指南】获取更多信息。
首先,我们得使用langchain_hub安装代理的基础库。
pip install langchainhub
安装 langchain-openai 库,以便与OpenAI交互,我们需使用 langchain-openai,它与OpenAI SDK相连通。【OpenAI SDK】的链接是【https://github.com/langchain-ai/langchain/tree/master/libs/partners/openai】。
pip install langchain-openai
现在,我们可以利用它来获取预定义的提示
from langchain_openai import ChatOpenAI
from langchain import hub
from langchain.agents import create_openai_functions_agent
from langchain.agents import AgentExecutor
# Get the prompt to use - you can modify this!
prompt = hub.pull("hwchase17/openai-functions-agent")
# You need to set OPENAI_API_KEY environment variable or pass it as argument `api_key`.
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
agent = create_openai_functions_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
我们现已成功地调用了代理并测试了它的响应!我们可以问它有关LangSmith的问题:“如何利用LangSmith进行测试?”我们也可以询问天气情况:
agent_executor.invoke({"input": "what is the weather in SF?"})
我们可以与它进行对话:
chat_history = [HumanMessage(content="Can LangSmith help test my LLM applications?"), AIMessage(content="Yes!")]
agent_executor.invoke({
"chat_history": chat_history,
"input": "Tell me more"
})
深度探索
我们会成功地设置了一个基本的代理。我们仅浅聊一下提到的基本的代理——对于本指南的这部分所涉及的所有内容,这篇文档详细介绍了它们。
参考文献
https://python.langchain.com/docs/get_started/quickstart/#agent

 浙公网安备 33010602011771号
浙公网安备 33010602011771号