LangChain SQL介绍以及使用Qwen1.5执行SQL查询教程
LangChain SQL
该模块可以让我们向LLM提问时从数据库中查询数据并做出回答。
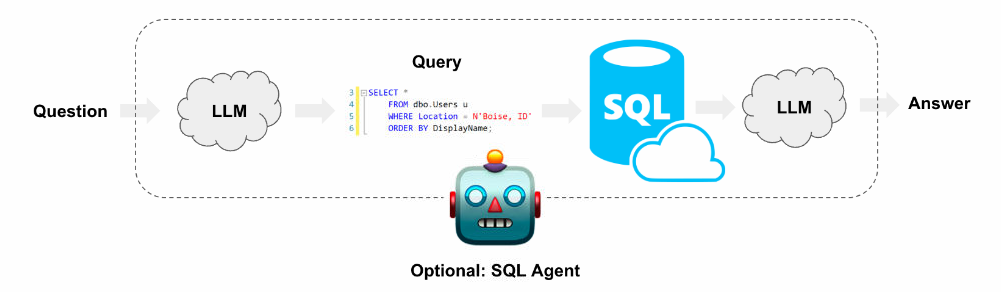
架构
SQL chain和agent的高层抽象架构:
- 问题转查询SQL:使用LLM将用户输入转成SQL查询
- 执行SQL查询:执行SQL语句
- 回答问题:LLM根据数据库查询结果返回回答内容
环境安装
安装必要环境和包
pip install --upgrade --quiet langchain langchain-community langchain-openai
在本文章中默认使用openai的模型
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Uncomment the below to use LangSmith. Not required.
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
下面的例子均使用SQLite连接Chinook数据库,按照这些安装步骤创建一个Chinook.db文件在当前目录下
- 将该文件 保存成
Chinook_Sqlite.sql - 运行
sqlite3 Chinook.db - 运行
.read Chinook_Sqlite.sql - 测试
SELECT * FROM Artist LIMIT 10;
现在,Chinhook.db已经在我们的目录中,我们可以使用基于SQLAlchemy的 SQLDatabase 类与它进行交互:
from langchain_community.utilities import SQLDatabase
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
print(db.dialect)
print(db.get_usable_table_names())
db.run("SELECT * FROM Artist LIMIT 10;")
sqlite
['Album', 'Artist', 'Customer', 'Employee', 'Genre', 'Invoice', 'InvoiceLine', 'MediaType', 'Playlist', 'PlaylistTrack', 'Track']
"[(1, 'AC/DC'), (2, 'Accept'), (3, 'Aerosmith'), (4, 'Alanis Morissette'), (5, 'Alice In Chains'), (6, 'Antônio Carlos Jobim'), (7, 'Apocalyptica'), (8, 'Audioslave'), (9, 'BackBeat'), (10, 'Billy Cobham')]"
Chain
让我们创建一个简单的Chain,它接收一个问题,将其转换成SQL查询,执行该查询,并将结果用于回答原始问题。
将问题转换为SQL查询
SQL链条或代理的第一步是接收用户输入并将其转换为SQL查询。LangChain内置了用于此目的的链条:create_sql_query_chain
from langchain.chains import create_sql_query_chain
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
chain = create_sql_query_chain(llm, db)
response = chain.invoke({"question": "How many employees are there"})
response
'SELECT COUNT(*) FROM Employee'
db.run(response)
'[(8,)]'
我们可以查看 LangSmith 的跟踪以更好地理解这个链在做什么。我们也可以直接检查链的提示。从下面的提示中,我们可以看到它是:
方言特定的。在这种情况下,它明确引用了 SQLite。
具有所有可用表的定义。
每个表都有三个示例行。
这种技术受到了像这样的论文的启发,这些论文建议展示示例行并明确表格可以提高性能。我们也可以这样检查完整的提示:
回答问题
现在我们已经有了自动生成和执行查询的方法,我们只需要将原始问题和SQL查询结果结合起来生成最终答案。我们可以再次将问题和结果传递给LLM来完成这个过程。
from operator import itemgetter
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnablePassthrough
answer_prompt = PromptTemplate.from_template(
"""Given the following user question, corresponding SQL query, and SQL result, answer the user question.
Question: {question}
SQL Query: {query}
SQL Result: {result}
Answer: """
)
answer = answer_prompt | llm | StrOutputParser()
chain = (
RunnablePassthrough.assign(query=write_query).assign(
result=itemgetter("query") | execute_query
)
| answer
)
chain.invoke({"question": "How many employees are there"})
'There are 8 employees.'
下一步
对于更复杂的查询生成,我们可能需要创建少样本提示或添加查询检查步骤。要了解更多关于此类高级技术,请查看以下内容:
Agent
LangChain的SQL Agent是一个设计用于与SQL数据库进行更灵活交互的工具。它的主要优点包括:
-
基于数据库模式和内容回答问题:SQL Agent不仅能理解并回答有关数据库模式的问题(例如描述一个特定表的结构),还能基于数据库的实际内容回答问题。
-
错误恢复能力:通过执行生成的查询,如果遇到错误,它可以捕获错误信息(traceback),然后正确地重新生成查询,从而实现从错误中恢复的能力。
-
处理依赖多个查询的问题:对于需要多个步骤和依赖不同查询结果的问题,SQL Agent能够有效地管理和执行这些依赖的查询。
-
节省令牌(tokens):通过仅考虑相关表的模式,SQL Agent能够更有效地使用令牌,减少不必要的令牌消耗。
使用create_sql_agent函数可以初始化这个代理。这个代理包含了SQLDatabaseToolkit,它提供了一系列工具来:
- 创建和执行查询
- 检查查询语法
- 检索表描述
- ...等等
这意味着,通过使用SQL Agent和内置的SQLDatabaseToolkit,开发者能够更加灵活和高效地与SQL数据库进行交互,无论是执行复杂的查询,还是处理和维护数据库,都能够得到简化和加速。这对于需要频繁与数据库交互的应用程序来说是一个很大的优势,尤其是在需要动态生成查询语句或处理复杂数据库交互逻辑的时候。
初始化Agent
from langchain_community.agent_toolkits import create_sql_agent
agent_executor = create_sql_agent(llm, db=db, agent_type="openai-tools", verbose=True)
agent_executor.invoke(
{
"input": "List the total sales per country. Which country's customers spent the most?"
}
)
> Entering new AgentExecutor chain...
Invoking: `sql_db_list_tables` with `{}`
Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track
Invoking: `sql_db_schema` with `Invoice,Customer`
CREATE TABLE "Customer" (
"CustomerId" INTEGER NOT NULL,
"FirstName" NVARCHAR(40) NOT NULL,
"LastName" NVARCHAR(20) NOT NULL,
"Company" NVARCHAR(80),
"Address" NVARCHAR(70),
"City" NVARCHAR(40),
"State" NVARCHAR(40),
"Country" NVARCHAR(40),
"PostalCode" NVARCHAR(10),
"Phone" NVARCHAR(24),
"Fax" NVARCHAR(24),
"Email" NVARCHAR(60) NOT NULL,
"SupportRepId" INTEGER,
PRIMARY KEY ("CustomerId"),
FOREIGN KEY("SupportRepId") REFERENCES "Employee" ("EmployeeId")
)
/*
3 rows from Customer table:
CustomerId FirstName LastName Company Address City State Country PostalCode Phone Fax Email SupportRepId
1 Luís Gonçalves Embraer - Empresa Brasileira de Aeronáutica S.A. Av. Brigadeiro Faria Lima, 2170 São José dos Campos SP Brazil 12227-000 +55 (12) 3923-5555 +55 (12) 3923-5566 luisg@embraer.com.br 3
2 Leonie Köhler None Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 +49 0711 2842222 None leonekohler@surfeu.de 5
3 François Tremblay None 1498 rue Bélanger Montréal QC Canada H2G 1A7 +1 (514) 721-4711 None ftremblay@gmail.com 3
*/
CREATE TABLE "Invoice" (
"InvoiceId" INTEGER NOT NULL,
"CustomerId" INTEGER NOT NULL,
"InvoiceDate" DATETIME NOT NULL,
"BillingAddress" NVARCHAR(70),
"BillingCity" NVARCHAR(40),
"BillingState" NVARCHAR(40),
"BillingCountry" NVARCHAR(40),
"BillingPostalCode" NVARCHAR(10),
"Total" NUMERIC(10, 2) NOT NULL,
PRIMARY KEY ("InvoiceId"),
FOREIGN KEY("CustomerId") REFERENCES "Customer" ("CustomerId")
)
/*
3 rows from Invoice table:
InvoiceId CustomerId InvoiceDate BillingAddress BillingCity BillingState BillingCountry BillingPostalCode Total
1 2 2009-01-01 00:00:00 Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 1.98
2 4 2009-01-02 00:00:00 Ullevålsveien 14 Oslo None Norway 0171 3.96
3 8 2009-01-03 00:00:00 Grétrystraat 63 Brussels None Belgium 1000 5.94
*/
Invoking: `sql_db_query` with `SELECT c.Country, SUM(i.Total) AS TotalSales FROM Invoice i JOIN Customer c ON i.CustomerId = c.CustomerId GROUP BY c.Country ORDER BY TotalSales DESC LIMIT 10;`
responded: To list the total sales per country, I can query the "Invoice" and "Customer" tables. I will join these tables on the "CustomerId" column and group the results by the "BillingCountry" column. Then, I will calculate the sum of the "Total" column to get the total sales per country. Finally, I will order the results in descending order of the total sales.
Here is the SQL query:
```sql
SELECT c.Country, SUM(i.Total) AS TotalSales
FROM Invoice i
JOIN Customer c ON i.CustomerId = c.CustomerId
GROUP BY c.Country
ORDER BY TotalSales DESC
LIMIT 10;
```
Now, I will execute this query to get the total sales per country.
[('USA', 523.0600000000003), ('Canada', 303.9599999999999), ('France', 195.09999999999994), ('Brazil', 190.09999999999997), ('Germany', 156.48), ('United Kingdom', 112.85999999999999), ('Czech Republic', 90.24000000000001), ('Portugal', 77.23999999999998), ('India', 75.25999999999999), ('Chile', 46.62)]The total sales per country are as follows:
1. USA: $523.06
2. Canada: $303.96
3. France: $195.10
4. Brazil: $190.10
5. Germany: $156.48
6. United Kingdom: $112.86
7. Czech Republic: $90.24
8. Portugal: $77.24
9. India: $75.26
10. Chile: $46.62
To answer the second question, the country whose customers spent the most is the USA, with a total sales of $523.06.
> Finished chain.
Qwen1.5连接Hive并查表Demo
需要提前安装pyhive相关环境以及xinference
https://blog.csdn.net/qq_54378261/article/details/137387404
# sasl 环境依赖
sudo apt-get install libsasl2-dev
pip install --upgrade langchain langchain-community langchain-openai -i https://pypi.mirrors.ustc.edu.cn/simple
pip install sasl thrift thrift-sasl pyhive xinference faiss-cpu jupyter -i https://pypi.mirrors.ustc.edu.cn/simple
建立数据库连接
from langchain_community.utilities import SQLDatabase
db = SQLDatabase.from_uri("hive://user:password@hive-server.example.com:10000/mydatabase")
print(db.dialect)
print(db.get_usable_table_names())
db.run("SELECT * FROM dim_static.dim_loan_part_number_df LIMIT 10")
xinference启动Qwen1.5
from langchain.chains import create_sql_query_chain
from langchain_openai import ChatOpenAI
from langchain.llms import Xinference
from langchain.prompts import PromptTemplate
llm = Xinference(server_url="http://localhost:9997", model_uid="Qwen1.5-14B-Chat",temperature=0.3)
chain = create_sql_query_chain(llm, db)
response = chain.invoke({"question": "How many employer are there"})
response
db.run(response)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号