英文原文:JVM: How to analyze Thread Dump
在这篇文章里我将教会你如何分析JVM的线程堆栈以及如何从堆栈信息中找出问题的根因。在我看来线程堆栈分析技术是Java EE产品支持工程师所必须掌握的一门技术。在线程堆栈中存储的信息,通常远超出你的想象,我们可以在工作中善加利用这些信息。
我的目标是分享我过去十几年来在线程分析中积累的知识和经验。这些知识和经验是在各种版本的JVM以及各厂商的JVM供应商的深入分析中获得的,在这个过程中我也总结出大量的通用问题模板。
那么,准备好了么,现在就把这篇文章加入书签,在后续几周中我会给大家带来这一系列的专题文章。还等什么,请赶紧给你的同事和朋友分享这个线程分析培训计划吧。
听上去是不错,我确实是应该提升我的线程堆栈分析技能...但我要从哪里开始呢?
我的建议是跟随我来完成这个线程分析培训计划。下面是我们会覆盖到的培训内容。同时,我会把我处理过的实际案例分享给大家,以便与大家学习和理解。
1) 线程堆栈概述及基础知识
2) 线程堆栈的生成原理以及相关工具
3) 不同JVM线程堆栈的格式的差异(Sun HotSpot、IBM JRE、Oracal JRockit)
4) 线程堆栈日志介绍以及解析方法
5) 线程堆栈的分析和相关的技术
6) 常见的问题模板(线程竟态、死锁、IO调用挂死、垃圾回收/OutOfMemoryError问题、死循环等)
7) 线程堆栈问题实例分析
我希望这一系列的培训能给你带来确实的帮助,所以请持续关注每周的文章更新。
但是如果我在学习过程中有疑问或者无法理解文章中的内容该怎么办?
不用担心,把我当做你的导师就好。任何关于线程堆栈的问题都可以咨询我(前提是问题不能太low)。请随意选择下面的几种方式与我取得联系:
1) 直接本文下面发表评论(不好意思的话可以匿名)
2) 将你的线程堆栈数据提交到Root Cause Analysis forum
3) 发Email给我,地址是 @phcharbonneau@hotmail.com
能帮我分析我们产品上遇到的问题么?
当然可以,如果你愿意的话可以把你的堆栈现场数据通过邮件或论坛 Root Cause Analysis forum发给我。处理实际问题是才是学习提升技能的王道。
我真心期望大家能够喜欢这个培训。所以我会尽我所能去为你提供高质量的材料,并回答大家的各种问题。
在介绍线程堆栈分析技术和问题模式之前,先要给大家讲讲基础的内容。所以在这篇帖子里,我将先覆盖到最基本的内容,这样大家就能更好的去理解JVM、中间件、以及Java EE容器之间的交互。
Java VM 概述
Java虚拟机是Jave EE 平台的基础。它是中间件和应用程序被部署和运行的地方。
JVM向中间件软件和你的Java/Java EE程序提供了下面这些东西:
– (二进制形式的)Java / Java EE 程序运行环境
– 一些程序功能特性和工具 (IO 基础设施,数据结构,线程管理,安全,监控 等等.)
– 借助垃圾回收的动态内存分配与管理
你的JVM可以驻留在许多的操作系统 (Solaris, AIX, Windows 等等.)之上,并且能根据你的物理服务器配置,你可以在每台物理/虚拟服务器上安装1到多个JVM进程.
JVM与中间件之间的交互
下面这张图展示了JVM、中间件和应用程序之间的高层交互模型。
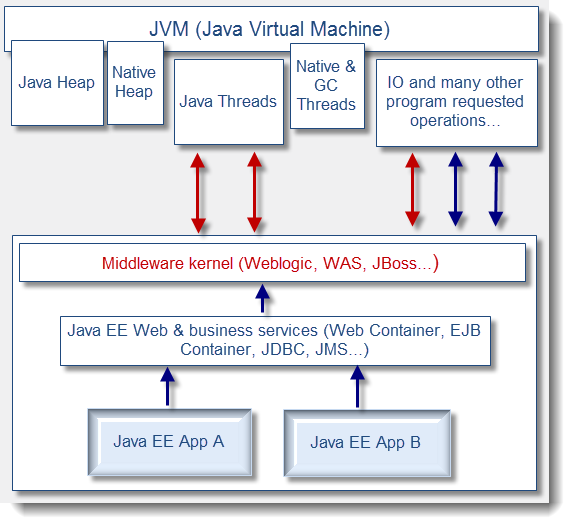
图中展示的JVM、中间件和应用程序件之间的一些简单和典型的交互。如你所见,标准Java EE应用程序的线程的分配实在中间件内核与JVM之间完成的。(当然也有例外,应用程序可以直接调用API来创建线程,这种做法并不常见,而且在使用的过程中也要特别的小心)
同时,请注意一些线程是由JVM内部来进行管理的,典型的例子就是垃圾回收线程,JVM内部使用这个线程来做并行的垃圾回收处理。
因为大多数的线程分配都是由Java EE容器完成的,所以能够理解和认识线程堆栈跟踪,并能从线程堆栈数据中识别出它来,对你而言很重要. 这可以让你能够快速的知道Java EE容器正要执行的是什么类型的请求.
从一个线程转储堆栈的分析角度来看,你将能了解从JVM发现的线程池之间的不同,并识别出请求的类型.
最后一节会向你提供对于HotSop VM而言什么是JVM线程堆栈的一个概述,还有你将会遇到的各种不同的线程. 而对 IBM VM 线程堆栈形式详细内容将会在第四节向你提供.
请注意你可以从根本原因分析论坛获得针对本文的线程堆栈示例.
JVM 线程堆栈——它是什么?
JVM线程堆栈是一个给定时间的快照,它能向你提供所有被创建出来的Java线程的完整清单.
每一个被发现的Java线程都会给你如下信息:
– 线程的名称;经常被中间件厂商用来识别线程的标识,一般还会带上被分配的线程池名称以及状态 (运行,阻塞等等.)
– 线程类型 & 优先级,例如 : daemon prio=3 ** 中间件程序一般以后台守护的形式创建他们的线程,这意味着这些线程是在后台运行的;它们会向它们的用户提供服务,例如:向你的Java EE应用程序 **
– Java线程ID,例如 : tid=0x000000011e52a800 ** 这是通过 java.lang.Thread.getId() 获得的Java线程ID,它常常用自增长的长整形 1..n** 实现
– 原生线程ID,例如 : nid=0x251c** ,之所以关键是因为原生线程ID可以让你获得诸如从操作系统的角度来看那个线程在你的JVM中使用了大部分的CPU时间等这样的相关信息. **
– Java线程状态和详细信息,例如: waiting for monitor entry [0xfffffffea5afb000] java.lang.Thread.State: BLOCKED (on object monitor)
** 可以快速的了解到线程状态极其当前阻塞的可能原因 **
– Java线程栈跟踪;这是目前为止你能从线程堆栈中找到的最重要的数据. 这也是你花费最多分析时间的地方,因为Java栈跟踪向提供了你将会在稍后的练习环节了解到的导致诸多类型的问题的根本原因,所需要的90%的信息。
– Java 堆内存分解; 从HotSpot VM 1.6版本开始,在线程堆栈的末尾处可以看到HotSpot的内存使用情况,比如说Java的堆内存(YoungGen, OldGen) & PermGen 空间。这个信息对分析由于频繁GC而引起的问题时,是很有用的。你可以使用已知的线程数据或模式做一个快速的定位。
|
1
2
3
4
5
6
7
8
9
|
HeapPSYoungGen total 466944K, used 178734K [0xffffffff45c00000, 0xffffffff70800000, 0xffffffff70800000)eden space 233472K, 76% used [0xffffffff45c00000,0xffffffff50ab7c50,0xffffffff54000000)from space 233472K, 0% used [0xffffffff62400000,0xffffffff62400000,0xffffffff70800000)to space 233472K, 0% used [0xffffffff54000000,0xffffffff54000000,0xffffffff62400000)PSOldGen total 1400832K, used 1400831K [0xfffffffef0400000, 0xffffffff45c00000, 0xffffffff45c00000)object space 1400832K, 99% used [0xfffffffef0400000,0xffffffff45bfffb8,0xffffffff45c00000)PSPermGen total 262144K, used 248475K [0xfffffffed0400000, 0xfffffffee0400000, 0xfffffffef0400000)object space 262144K, 94% used [0xfffffffed0400000,0xfffffffedf6a6f08,0xfffffffee0400000) |
线程堆栈信息大拆解
为了让大家更好的理解,给大家提供了下面的这张图,在这张图中将HotSpot VM上的线程堆栈信息和线程池做了详细的拆解,如下图所示:

上图中可以看出线程堆栈是由多个不同部分组成的。这些信息对问题分析都很重要,但对不同的问题模式的分析会使用不同的部分(问题模式会在后面的文章中做模拟和演示。)
现在通过这个分析样例,给大家详细解释一下HoteSpot上线程堆栈信息中的各个组成部分:
# Full thread dump标示符
“Full thread dump”是一个全局唯一的关键字,你可以在中间件和单机版本Java的线程堆栈信息的输出日志中找到它(比如说在UNIX下使用:kill -3 <PID> )。这是线程堆栈快照的开始部分。
|
1
|
Full thread dump Java HotSpot(TM) 64-Bit Server VM (20.0-b11 mixed mode): |
# Java EE 中间件,第三方以及自定义应用软件中的线程
这个部分是整个线程堆栈的核心部分,也是通常需要花费最多分析时间的部分。堆栈中线程的个数取决你使用的中间件,第三方库(可能会有独立线程)以及你的应用程序(如果创建自定义线程,这通常不是一个很好的实践)。
在我们的示例线程堆栈中,WebLogic是我们所使用的中间件。从Weblogic 9.2开始, 会使用一个用“’weblogic.kernel.Default (self-tuning)”唯一标识的能自行管理的线程池
|
1
2
3
4
5
6
7
8
|
"[STANDBY] ExecuteThread: '414' for queue: 'weblogic.kernel.Default (self-tuning)'" daemon prio=3 tid=0x000000010916a800 nid=0x2613 in Object.wait() [0xfffffffe9edff000] java.lang.Thread.State: WAITING (on object monitor) at java.lang.Object.wait(Native Method) - waiting on <0xffffffff27d44de0> (a weblogic.work.ExecuteThread) at java.lang.Object.wait(Object.java:485) at weblogic.work.ExecuteThread.waitForRequest(ExecuteThread.java:160) - locked <0xffffffff27d44de0> (a weblogic.work.ExecuteThread) at weblogic.work.ExecuteThread.run(ExecuteThread.java:181) |
# HotSpot VM 线程
这是一个有Hotspot VM管理的内部线程,用于执行内部的原生操作。一般你不用对此操太多心,除非你(通过相关的线程堆栈以及 prstat或者原生线程Id)发现很高的CPU占用率.
|
1
|
"VM Periodic Task Thread" prio=3 tid=0x0000000101238800 nid=0x19 waiting on condition |
# HotSpot GC 线程
当使用 HotSpot 进行并行 GC (如今在使用多个物理核心的环境下很常见), 默认创建的HotSpot VM 或者每个JVM管理一个有特定标识的GC线程时. 这些GC线程可以让VM以并行的方式执行其周期性的GC清理, 这会导致GC时间的总体减少;与此同时的代价是CPU的使用时间会增加.
|
1
2
3
|
"GC task thread#0 (ParallelGC)" prio=3 tid=0x0000000100120000 nid=0x3 runnable"GC task thread#1 (ParallelGC)" prio=3 tid=0x0000000100131000 nid=0x4 runnable……………………………………………………………………………………………………………………………………………………………… |
这事非常关键的数据,因为当你遇到跟GC有关的问题,诸如过度GC、内存泄露等问题是,你将可以利用这些线程的原生Id值关联的操作系统或者Java线程,进而发现任何对CPI时间的高占用. 未来的文章你将会了解到如何识别并诊断这样的问题.
# JNI 全局引用计数
JNI (Java 本地接口)的全局引用就是从本地代码到由Java垃圾收集器管理的Java对象的基本的对象引用. 它的角色就是阻止对仍然在被本地代码使用,但是技术上已经不是Java代码中的“活动的”引用了的对象的垃圾收集.
同时为了侦测JNI相关的泄露而留意JNI引用也很重要. 如果你的程序直接使用了JNI,或者像监听器这样的第三方工具,就容易造成本地的内存泄露.
|
1
|
JNI global references: 1925 |
# Java 堆栈使用视图
这些数据被添加回了 JDK 1 .6 ,向你提供有关Hotspot堆栈的一个简短而快速的视图. 我发现它在当我处理带有过高CPU占用的GC相关的问题时非常有用,你可以在一个单独的快照中同时看到线程堆栈以及Java堆的信息,让你当时就可以在一个特定的Java堆内存空间中解析(或者排除)出任何的关键点. 你如在我们的示例线程堆栈中所见,Java 的堆 OldGen 超出了最大值!
|
1
2
3
4
5
6
7
8
9
|
Heap PSYoungGen total 466944K, used 178734K [0xffffffff45c00000, 0xffffffff70800000, 0xffffffff70800000) eden space 233472K, 76% used [0xffffffff45c00000,0xffffffff50ab7c50,0xffffffff54000000) from space 233472K, 0% used [0xffffffff62400000,0xffffffff62400000,0xffffffff70800000) to space 233472K, 0% used [0xffffffff54000000,0xffffffff54000000,0xffffffff62400000) PSOldGen total 1400832K, used 1400831K [0xfffffffef0400000, 0xffffffff45c00000, 0xffffffff45c00000) object space 1400832K, 99% used [0xfffffffef0400000,0xffffffff45bfffb8,0xffffffff45c00000) PSPermGen total 262144K, used 248475K [0xfffffffed0400000, 0xfffffffee0400000, 0xfffffffef0400000) object space 262144K, 94% used [0xfffffffed0400000,0xfffffffedf6a6f08,0xfffffffee0400000) |
我希望这篇文章能对你理解Hotspot VM线程堆栈的基本信息有所帮助。下一篇文章将会向你提供有关IBM VM的线程堆栈概述和分析.
请自由的向本文发表观点或疑问.
引用: 如何分析线程堆栈 —— 第一部分, 如何分析线程堆栈——第二部分 & 如何分析线程堆栈——第三部分 来自我们的Java EE Support Patterns & Java Tutorial 博客上的 JCG 合作者Hugues Charbonneau.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号