
requests(1):基本用法
requests中可以使用get()方法来实现与urlopen()相同的操作,得到Response对象。
也可以使用其他的方法:post()、put()、delete()等方法来实现post、put、delete等请求。
1.构建一个最简单的GET请求。
代码:
import requests r=requests.get('http://httpbin.org/get') print(r.text)
运行结果:
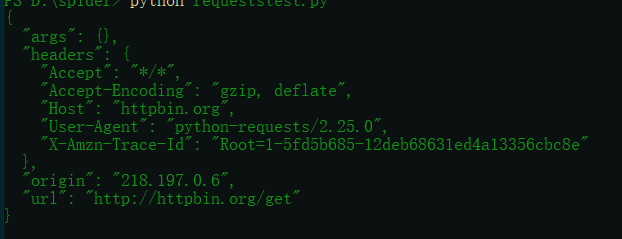
如果要附加额外的信息,使用params这个参数。
代码:
import requests data={ 'name':'germe', 'age':'22' } r=requests.get('http://httpbin.org/get',params=data) print(r.text)
运行结果:
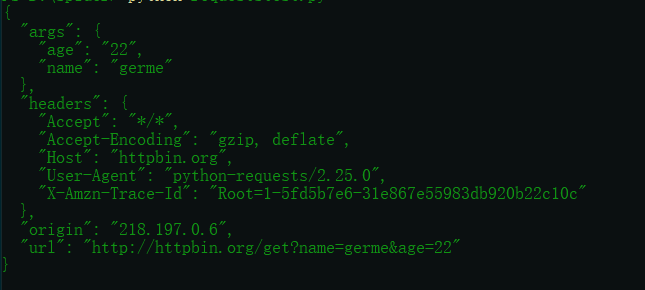
从结果可以看出,请求的结果被自动构造成了:http://httpbin.org/get?name=germe&age=22
网页的返回类型实际上是str类型,但是是JSON格式,如果想直接得到解析返回的结果,得到一个字典格式的话,可以调用json()方法。
代码:
import requests r=requests.get('http://httpbin.org/get') print(type(r.text)) print(r.json()) print(type(r.json()))
运行结果:

2.抓取网页
代码:
import requests import re headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.60' } r=requests.get("https://www.zhihu.com/explore",headers=headers) pattern=re.compile('explore-feed.*?question_link.*?>(.*?)</a>',re.S) titles=re.findall(pattern,r.text) print(titles)
运行结果:输出
[]
(还不清楚原因,书上不是这样,代码应该没问题,猜测是知乎网站的问题)
3.抓取二进制数据
图片、音频、视频这些文件本质上都是由二进制码组成的。以GitHub的站点图标为例。
代码:
import requests r=requests.get("https://github.com/favicon.ico") print(r.text) print(r.content)
运行结果:输出
出现乱码和bytes类型的数据
将提取到的图片保存下来
代码:
import requests r=requests.get("https://github.com/favicon.ico") with open('favicon.ioc','wb') as f: #open()第二个参数,以二进制写的形式打开 f.write(r.content)
运行结果:
在文件夹出现favicon.ico的图标,为GitHub网站的图标。
4.添加headers
同 抓取网页
5.POST请求
代码:
import requests data={ 'name':'germe', 'age':'22' } r=requests.post('http://httpbin.org/post',data=data) print(r.text)
运行结果:输出
{ "args": {}, "data": "", "files": {}, "form": { "age": "22", "name": "germe" }, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Content-Length": "17", "Content-Type": "application/x-www-form-urlencoded", "Host": "httpbin.org", "User-Agent": "python-requests/2.25.0", "X-Amzn-Trace-Id": "Root=1-5fd8a291-5a34daa963976ae238f4a04c" }, "json": null, "origin": "183.95.212.198", "url": "http://httpbin.org/post" }
6.响应
获得响应的其他信息,如状态码、响应头,Cookies等。
代码:
import requests headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.60' }#如果不设置User-Agent会出现403 r=requests.get("https://www.jianshu.com",headers=headers) print(type(r.status_code),r.status_code)#显示状态码 print(type(r.headers),r.headers) print(type(r.cookies),r.cookies) print(type(r.url),r.url) print(type(r.history),r.history)
运行结果:输出
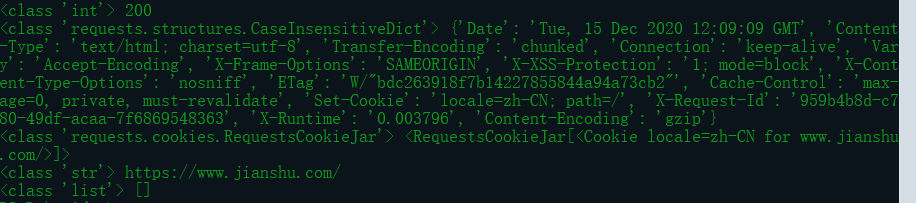
状态码常用来判断请求是否成功,requests提供一个内置的状态码查询对象requests.codes。
代码:
import requests headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.60' } r=requests.get("https://www.jianshu.com",headers=headers) exit() if not r.status_code == requests.codes.ok else print('Request Successfully')
运行结果:若成功,输出
Request Successfully
参考用书《python3网络爬虫开发实战》

