
sql 调优
1. 建立索引
在经常需要进行检索的字段上创建索引,如 WHERE,JOIN ,ORDER BY。
索引并不是越多越好。索引固然可以提高相应的 select 效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引。
避免在索引上使用计算。
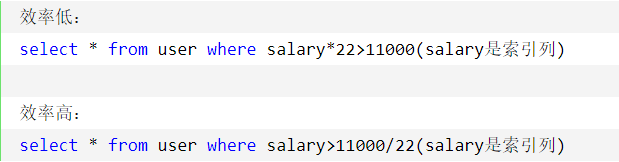
2. where 顺序
过滤掉最大数量记录在前。
3. 避免全表扫描
SELECT * ×
LIMIT 1 √( 明知只有一条查询结果时使用)
4. 对于连续的数值,能用 between 就不要用 in。
eg: select id from t where num in(1,2,3) >>> select id from t where num between 1 and 3
5. 避免前置百分号。
eg:select id from t where name like ‘%abc%’
若要提高效率,可以考虑全文检索:https://www.cnblogs.com/zzm96/p/12747029.html
6. 使用预编译
如存储过程、视图。
7. 使用临时表暂存中间结果
将临时结果暂存在临时表,后面的查询就在 tempdb 中了。这可以避免程序中多次扫描主表,也大大减少了程序执行中 "共享锁" 阻塞 "更新锁",减少了阻塞,提高了并发性能。
但是也得避免频繁创建和删除临时表,以减少系统表资源的消耗。
8. 尽量将多条 sql 压缩到一条 sql 语句之中
每次执行 sql 的时候都要建立网络连接、进行权限校验、进行SQL语句的查询优化、发送执行结果,这个过程是非常耗时的。
9. 用 where 代替 having
因为 having 只会在检索出所有记录之后才对结果集进行过滤,而 where 则是在聚合前筛选记录。
但 having 可以结合聚合函数使用,where 不行。
10. 使用表的别名
如联表查询时,可以减少解析的时间。
11. union all 代替 union
如果可以判断检索结果中不会有重复的记录时候,应该用 union all。
12. 尽量不要用游标。
游标详解:https://www.cnblogs.com/jdzhang/p/7576520.html
13. 使用 varchar/nvarchar 代替 char/nchar。
为列选择合适的数据类型,磁盘和内存消耗越小越好。
14. 更新 update 语句优化。
如果只更改 1、2 个字段,不要 update 全部字段,否则频繁调用会引起明显的性能消耗,同时带来大量日志。
15. with(nolock):查询时不锁定表,从而达到提高查询速度。
缺点:
可能造成脏读。
使用场景:
数据量特别大的表,牺牲数据安全性来提升性能;
允许出现脏读现象的业务逻辑;
数据不经常修改的表。
16. explain 命令查看 sql 执行计划,详解:https://www.cnblogs.com/tufujie/p/9413852.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号