Computer Vision_18_Image Stitching:Automatic Panoramic Image Stitching using Invariant Features——2007
此部分是计算机视觉部分,主要侧重在底层特征提取,视频分析,跟踪,目标检测和识别方面等方面。对于自己不太熟悉的领域比如摄像机标定和立体视觉,仅仅列出上google上引用次数比较多的文献。有一些刚刚出版的文章,个人非常喜欢,也列出来了。
18. Image Stitching
图像拼接,另一个相关的词是Panoramic。在Computer Vision: Algorithms and Applications一书中,有专门一章是讨论这个问题。这里的两面文章一篇是综述,一篇是这方面很经典的文章。
[2006 Fnd] Image Alignment and Stitching A Tutorial
[2007 IJCV] Automatic Panoramic Image Stitching using Invariant Features
若引用文献:Brown M , Lowe D G . Automatic Panoramic Image Stitching using Invariant Features[J]. International Journal of Computer Vision, 2007, 74(1):59-73.
翻译
使用不变特征自动全景图像拼接——http://tongtianta.site/paper/38233
作者:MATTHEW BROWN AND DAVID G. LOWE
摘要 -本文涉及全自动全景图像拼接的问题。虽然很好地研究了1D问题(单轴旋转),但2D或多行拼接更加困难。先前的方法已经使用人类输入或对图像序列的限制来建立匹配图像。在这项工作中,我们将拼接表示为多图像匹配问题,并使用不变的局部特征来找到所有图像之间的匹配。因此,我们的方法对输入图像的排序,方向,比例和照明不敏感。它对不属于全景图的噪声图像也不敏感,并且可以识别无序图像数据集中的多个全景图。除了提供更多细节之外,本文还通过引入增益补偿和自动矫直步骤扩展了我们之前在该领域的工作(Brown和Lowe,2003)。
关键词:多图像匹配,拼接,识别
1.简介
全景图像拼接有广泛的研究文献(Szeliski,2004; Milgram,1975; Brown和Lowe,2003)和几个商业应用(Chen,1995; Realviz,http://www.realviz.com;
http://www.microsoft.com/products/imaging)。问题的基本几何形状是很好理解的,包括估计每个图像的3×3相机矩阵或单应性(Hartley和Zisserman,2004; Szeliski和Shum,1997)。该估计过程需要初始化,其通常由用户输入提供以近似对准图像,或者固定图像排序。例如,与佳能数码相机捆绑在一起的PhotoStitch软件需要水平或垂直扫描或方形图像矩阵。REALVIZ Stitcher版本4(http://www.realviz.com)具有用户界面,用于在自动注册进行之前用鼠标粗略定位图像。我们的工作很新颖,因为我们不需要提供这样的初始化。
在研究文献中,自动图像对齐和拼接的方法大致分为两类 - 直接(Szeliski和Kang,1995; Irani和Anandan,1999; Sawhney和Kumar,1999; Shum和Szeliski,2000)和基于特征(Zoghlami等,1997; Capel和Zisserman,1998; McLauchlan和Jaenicke,2002)。直接方法的优点是它们使用所有可用的图像数据,因此可以提供非常准确的配准,但它们需要密切初始化。基于特征的配准不需要初始化,但是传统的特征匹配方法(例如,Harris角落周围的图像块的相关性(Harris,1992; Shi和Tomasi,1994))缺乏实现任意全景图像序列的可靠匹配所需的不变性。
在本文中,我们描述了一种基于不变特征的全自动全景图像拼接方法。这比以前的方法有几个优点。首先,尽管输入图像中的旋转,变焦和光照变化,但我们使用不变特征使得能够可靠地匹配全景图像序列。其次,通过将图像拼接视为多图像匹配问题,我们可以自动发现图像之间的匹配关系,并识别无序数据集中的全景图。第三,我们使用多波段混合生成高质量的结果,以呈现无缝的输出全景图。本文通过引入增益补偿和自动矫直步骤,扩展了我们在该领域的早期工作(Brown和Lowe,2003)。我们还描述了一个有效的束调整实现,并展示了如何对具有任意数量的波段的多个重叠图像执行多波段混合。
在本文的其余结构如下。第2节开发了问题的几何形状,并激发了我们对不变特征的选择。第3节描述了我们的图像匹配方法(RANSAC)和图像匹配验证的概率模型。在第4节中,我们描述了我们的图像对齐算法(束调整),它共同优化了每个摄像机的参数。第5-7节描述了渲染管道,包括自动拉直,增益补偿和多频段混合。在第9节中,我们提出了未来工作的结论和想法。
2.特征匹配
全景识别算法的第一步是在所有图像之间提取和匹配SIFT(Lowe,2004)特征。SIFT特征位于高斯函数差的尺度 - 空间最大值/最小值处。在每个特征位置,建立特征尺度和方向。这给出了相似性不变的帧,在其中进行测量。尽管在该帧中简单地采样强度值将是相似性不变量,但实际上通过在方向直方图中累积局部梯度来计算不变量描述符。这允许边缘在不改变描述符向量的情况下稍微移动,从而为远程变化提供一些鲁棒性。这种空间累积对于移位不变性也很重要,因为兴趣点位置通常仅在0-3像素范围内准确(Brown等,2005; Sivic和Zisserman,2003)。通过使用梯度(消除偏差)和归一化描述符矢量(消除增益)来实现照明不变性。
由于SIFT特征在旋转和比例变化下是不变的,因此我们的系统可以处理具有不同方向和缩放的图像(参见图8)。请注意,使用传统的特征匹配技术(例如Harris角落周围的图像块的相关性)是不可能的。普通(平移)相关在旋转下不是不变的,Harris角对于尺度的变化不是不变的。
假设相机围绕其光学中心旋转,图像可能经历的变换组是一组特殊的单应性。我们通过旋转矢量θ= [θ1, θ2, θ3]和焦距f对每个摄像机进行参数设置。这给出了成对的单应性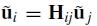 其中
其中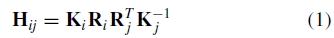
并且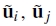 是均匀图像位置(
是均匀图像位置(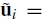
 ,其中ui是二维图像位置)。 4参数相机型号由定义
,其中ui是二维图像位置)。 4参数相机型号由定义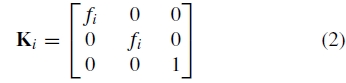
和(使用旋转的指数表示)
理想情况下,人们会使用在这组变换下不变的图像特征。但是,对于图像位置的微小变化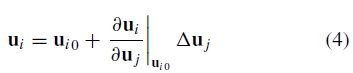
或者相当于 ,其中
,其中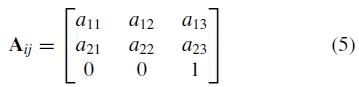
是通过线性化关于ui0的单应性获得的一种自然变换。这意味着每个小图像补丁都会经历一次有限的变换,并且可以使用SIFT特征,这些特征在不确定的变化下是部分不变的。
一旦从所有n个图像中提取特征(线性时间),就必须匹配它们。由于多个图像可能与单个光线重叠,因此每个特征与特征空间中的k个最近邻居匹配(我们使用k = 4)。这可以在O(n log n)时间内通过使用k-d树来找到近似的最近邻居(Beis和Lowe,1997)。k-d树是轴对齐的二进制空间分区,其在具有最高方差的维度中以均值递归地划分特征空间。
3.图像匹配
在这个阶段,目标是找到所有匹配(即重叠)的图像。连接的图像匹配组稍后将成为全景图。由于每个图像可能与每个图像可能匹配,因此该问题首先出现在图像数量的二次方。然而,仅需要将每个图像与少量重叠图像匹配,以便获得图像几何形状的良好解决方案。
从特征匹配步骤,我们已经识别出具有大量匹配的图像。我们考虑一个恒定数量的m个图像,它们与当前图像具有最多的特征匹配,因为潜在的图像匹配(我们使用m = 6)。首先,我们使用RANSAC选择一组与图像之间的单应性兼容的内点。接下来,我们应用概率模型来验证匹配。
3.1 使用RANSAC进行稳健的单应性估计
RANSAC(随机样本共识)(Fischler和Bolles,1981)是一种稳健的估计程序,它使用最小的随机采样对应集来估计图像变换参数,并找到与数据具有最佳共识的解决方案。在全景图的情况下,我们选择r = 4个特征对应的集合,并使用直接线性变换(DLT)方法计算它们之间的单应性H(Hartley和Zisserman,2004)。我们用n = 500次试验重复这一点,并选择具有最大内点数的解(其投影在公差ε像素内与H一致),见图1。鉴于一对匹配图像之间特征匹配正确的概率(内部概率)是pi,在n次试验之后找到正确变换的概率是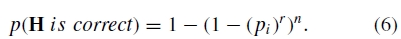
经过大量试验后,发现正确单应性的概率非常高。例如,对于inlier概率pi = 0.5,在500次试验后未发现正确单应性的概率约为1×10-14。
RANSAC本质上是一种估算H的抽样方法。如果不是最大化内部数量而是最大化对数似然的总和,则结果是最大似然估计(MLE)。此外,如果转换参数的先验可用,则可以计算最大后验估计(MAP)。这些算法分别称为MLESAC和MAPSAC(Torr,2002)。

图1.从所有图像中提取SIFT特征。在使用k-d树匹配所有特征之后,检查具有与给定图像匹配的最大特征数量的m个图像以进行图像匹配。首先执行RANSAC以计算单应性,然后调用概率模型以基于内部数量来验证图像匹配。在此示例中,输入图像是517×374像素,并且有247个正确的特征匹配
3.2 图像匹配验证的概率模型
对于每对可能匹配的图像,我们有一组几何一致的特征匹配(RANSAC内点)和一组在重叠区域内但不一致的特征(RANSAC异常值)。我们的验证模型的想法是比较通过正确的图像匹配或错误的图像匹配生成这组内部/异常值的概率。
对于给定图像,我们表示重叠区域nf 中的特征总数和内部数ni。该图像正确/不正确匹配的事件由二进制变量mε{ 0,1}表示。第i个特征匹配f(i) ε{0,1}的事件是一个内部/异常值,假设是独立的伯努利,因此内部的总数是二项式的
其中p1是在给定正确的图像匹配的情况下特征是内部的概率,并且p0是在给定假图像匹配的情况下特征是内部的概率。一组特征匹配变量{f(i),i = 1,2,。 ,n f}表示为f(1:nf)。内点的数量 和B(·)是二项分布
和B(·)是二项分布
我们选择值p1 = 0.6和p0 = 0.1。我们现在可以使用贝叶斯规则评估图像匹配正确的后验概率
如果p(m = 1 | f(1:nf))> pmin,我们接受图像匹配
选择值p(m = 1)= 10-6和pmin = 0.999给出条件
对于正确的图像匹配,其中α= 8.0和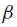 = 0.3。虽然在实践中我们选择了p0,p1,p(m = 0),p(m = 1)和pmin的值,但原则上它们可以从数据中学习。例如,可以通过计算与大数据集上的正确单应性一致的匹配分数来估计p1。
= 0.3。虽然在实践中我们选择了p0,p1,p(m = 0),p(m = 1)和pmin的值,但原则上它们可以从数据中学习。例如,可以通过计算与大数据集上的正确单应性一致的匹配分数来估计p1。
一旦在图像之间建立了成对匹配,我们就可以将全景序列找到连接的匹配图像集。这使我们能够识别一组图像中的多个全景图,并拒绝与其他图像不匹配的噪声图像(参见图(2))。

图2.识别全景图。给定一组嘈杂的特征匹配,我们使用RANSAC和概率验证程序来找到一致的图像匹配(a)。一对图像之间的每个箭头表示在该对之间找到了一组一致的特征匹配。检测图像匹配的连接分量(b)并缝合成全景图(c)。请注意,该算法对不属于全景图的噪声图像(大小为1的图像的连接组件)不敏感。
4.捆绑调整
给定图像之间的一组几何一致的匹配,我们使用束调整(Triggs等,1999)来联合求解所有相机参数。这是必要的步骤,因为成对单应性的连接将导致累积误差并忽略图像之间的多个约束,例如,全景图的末端应该连接起来。图像被逐一添加到束调整器中,在每一步添加最佳匹配图像(最大匹配数)。初始化新图像的旋转和焦距与其最佳匹配的图像相同。然后使用Levenberg-Marquardt更新参数。
我们使用的目标函数是一个robusti fi ed和平方投影误差。也就是说,将每个特征投影到其匹配的所有图像中,并且相对于相机参数最小化平方图像距离的总和。 (注意,也可以(并且实际上在统计上最佳)明确地表示未知射线方向X,并且与摄像机参数一起估计它们。如果使用稀疏束调整方法,这不会增加算法的复杂性(Triggs等,1999)。)给定对应关系uki↔ulj(uki表示图像i中第k个特征的位置),残差为
其中pkij是从图像j到对应于uki的点的图像i的投影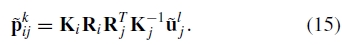
误差函数是所有残留错误图像的总和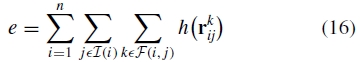
其中n是图像的数量, 是与图像i匹配的图像集合,F(i,j)是图像i和j之间的特征匹配集合。我们使用Huber鲁棒误差函数(Huber,1981)
是与图像i匹配的图像集合,F(i,j)是图像i和j之间的特征匹配集合。我们使用Huber鲁棒误差函数(Huber,1981)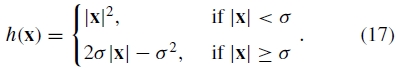
该误差函数结合了内点的L 2范数优化方案的快速收敛特性(距离小于σ),以及对于异常值(距离大于σ)的L 1范数方案的鲁棒性。我们在初始化期间使用离群距离σ=∝,在最终解决方案中使用σ= 2像素。
这是我们使用Levenberg-Marquardt算法求解的非线性最小二乘问题。每个迭代步骤都是这种形式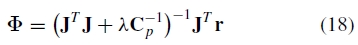
其中Φ是所有参数,r是残差和J = 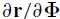 。我们编码了关于(对角线)协方差矩阵C p中的参数变化的先验信念
。我们编码了关于(对角线)协方差矩阵C p中的参数变化的先验信念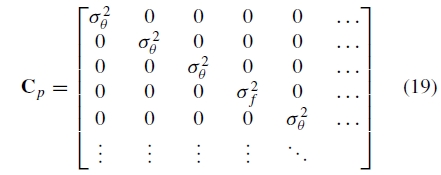
这被设置成使得角度的标准偏差是σ=Π/ 16并且焦距σf=¯f / 10(其中¯f是到目前为止估计的焦距的平均值)。这有助于选择合适的步长,从而加速收敛。例如,如果使用球面协方差矩阵,则旋转中1弧度的变化将等同于焦距参数中1个像素的变化。最后,在每次迭代时改变λ参数以确保等式16的目标函数实际上确实减小。
例如,通过链规则分析地计算导数
其中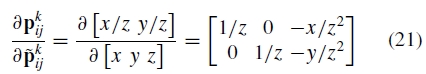
和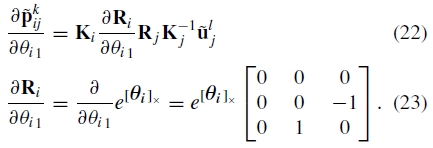
4.1 线性系统直接计算的快速求解
由于矩阵J是稀疏的,通过明确地将J乘以其转置来形成JTJ是无效的。实际上,这将是束调整中最昂贵的步骤,对于M×N矩阵J(M是测量数量的两倍并且N是参数的数量)的成本为O(MN2)。由于每个图像通常仅匹配其他图像的一小部分,因此产生稀疏性。这意味着在实践中,JTJ的每个元素可以在远小于M次乘法的情况下计算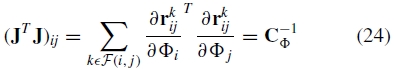
即,相机i和j之间的逆协方差仅取决于i和j之间的特征匹配的残差。
类似地,JTr不需要显式计算,但可以通过计算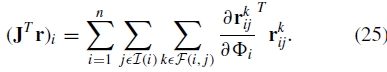
在两种情况下,如果每个特征与每个单个图像匹配,则每个求和将需要M次乘法,但实际上,给定图像的特征匹配的数量远小于此。因此,束调整的每次迭代是O(N 3),这是求解N×N线性系统的成本。参数N的数量是图像数量的4倍,并且通常M大约是N的100倍。
5.自动全景矫直
使用第2-4节的步骤进行的图像配准给出了相机之间的相对旋转,但是对于选定的世界坐标系仍然存在未知的3D旋转。如果我们简单地假设其中一个图像的R = I,我们通常会在输出全景图中找到波浪效果。这是因为真正的相机不太可能是完美的水平和不倾斜。我们可以通过利用关于人们通常拍摄全景图像的方式的启发式来纠正这种波浪输出并自动拉直全景。这个想法是人们很少相对于地平线扭曲相机,因此相机X矢量(水平轴)通常位于一个平面内(见图3)。通过找到摄像机X向量的协方差矩阵的零向量,我们可以找到“向上矢量”u(垂直于包含摄像机中心和地平线的平面)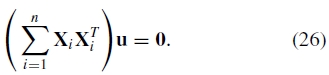

图3.查找向上的向量u。一个良好的启发式对齐波浪全景是要注意人们很少相对于地平线扭曲相机。因此,尽管倾斜(b)和旋转(c),相机X矢量通常位于平面中。向上矢量u(与重力方向相反)是垂直于该平面的矢量。
应用全局旋转使得向上矢量u是垂直的(在渲染帧中)有效地从输出全景图中消除波浪效果,如图4所示。

图4.自动全景矫直。使用用户很少相对于地平线扭曲相机的启发式算法允许我们通过计算向上矢量(垂直于包含地平线和相机中心的平面)来拉直波浪全景图。
6.获得补偿
在前面的部分中,我们描述了一种计算每个摄像机的几何参数(方向和焦距)的方法。在本节中,我们将展示如何求解光度参数,即图像之间的整体增益。这是以类似的方式设置的,在所有图像上定义了错误功能。误差函数是所有重叠像素的增益归一化强度误差之和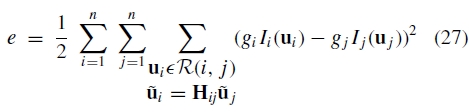
其中gi,gj是增益,R(i,j)是图像i和j之间的重叠区域。在实践中,我们通过每个重叠区域 中的平均值来近似I(ui)
中的平均值来近似I(ui)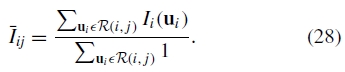
这简化了计算并且给出了异常值的一些鲁棒性,这可能由于图像之间的小的配准不良而产生。此外,由于g = 0是问题的最佳解决方案,我们添加一个先前项以保持增益接近于1。因此错误功能变为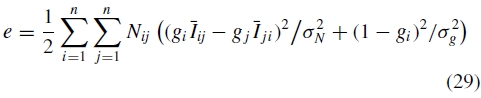
其中Nij =| R(i,j)| 等于图像i中在图像j中重叠的像素数。参数σN和σg分别是归一化强度误差和增益的标准偏差。我们选择值σN= 10.0,(I ε {0,255})和σg= 0.1。这是增益参数g中的二次目标函数,可以通过将导数设置为0来以闭合形式求解(参见图5)。

图5.增益补偿。请注意,如果未应用增益补偿(a) - (b),则可以看到图像之间亮度的较大变化。在增益补偿之后,由于诸如渐晕(c)之类的未模型化效果,一些图像边缘仍然可见。使用多波段混合(d)可以有效地平滑这些。

图6.多频段混合。对于k = 1,2,3的带通图像Bkσ(θ,ϕ)显示在左侧,右侧显示相应的混合权重Wkσ(θ,ϕ)。初始混合权重分配给1,其中每个图像具有最大权重。为了获得每个混合函数,权重在空间频率σ处被模糊,并且形成相同空间频率的带通图像。使用基于混合权重的加权和将带通图像混合在一起(注意:为了清晰起见,这些图中的混合宽度被夸大了)。
7.多波段混合
理想情况下,沿着光线的每个样本(像素)在与其相交的每个图像中具有相同的强度,但实际上情况并非如此。即使在增益补偿之后,由于许多未模型化的效果,例如渐晕(强度朝向图像边缘减小),由于光学中心的不希望的运动导致的视差效应,由于误差导致的错误配准误差,一些图像边缘仍然可见。 - 相机的模型,径向变形等。因此,良好的混合策略很重要。
从前面的步骤我们得到n个图像I i(x,y)(i ε{1,n}),给定已知的配准,它可以用公共(球形)坐标系统表示为I i(θ,ϕ)。为了组合来自多个图像的信息,我们为每个图像分配权重函数W(x,y)=w(x)w(y)其中w(x)从图像中心的1到边缘处的0线性变化。 。权重函数也在球面坐标W i(θ,ϕ)中重新采样。混合的简单方法是使用这些权重函数沿每条射线执行图像强度的加权和
其中I linear(θ,ϕ)是使用线性混合形成的复合球形图像。然而,如果存在小的配准误差,这种方法可能导致高频细节的模糊(参见图7)。为了防止这种情况,我们使用Burt和Adelson(1983)的多频带混合算法。多频段混合背后的想法是在很大的空间范围内混合低频,在短距离内混合高频。

图7.线性和多波段混合的比较。使用5波段和σ= 5像素的多波段混合来混合右侧的图像。左边的图像是线性混合的。在这种情况下,在移动的人上的匹配导致图像之间的小的重合失调,这导致线性混合的结果中的模糊,但是多波段混合图像是清楚的。
我们通过找出图像i最负责的点集来初始化每个图像的混合权重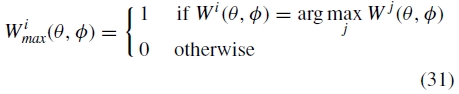
即W imax(θ,ϕ)对于(θ,ϕ)值为1,其中图像i 具有最大权重和0,其中一些其他图像具有更高权重。这些最大权重映射被连续模糊以形成每个频带的混合权重。
形成渲染图像的高通版本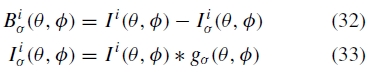
其中gσ(θ,ϕ)是标准偏差σ的高斯,而*运算符表示卷积。Bσ(θ,ϕ)表示波长范围λ ε [0,σ ]中的空间频率。我们使用通过模糊该图像的最大权重图形成的混合权重在图像之间混合该带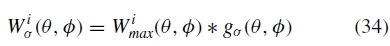
其中Wiσ(θ,ϕ)是波长λ ε [0,σ ]波段的混合权重。使用较低频带通图像混合后续频带,并进一步模糊混合权重,即k≥1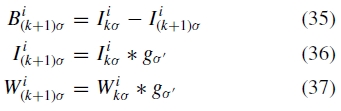
其中设置高斯模糊核 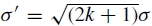 的标准偏差,使得后续频带具有相同的波长范围。
的标准偏差,使得后续频带具有相同的波长范围。
对于每个波段,使用相应的混合权重线性组合重叠图像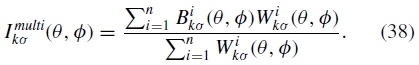
算法:自动全景拼接
输入:n无序图像
I.从所有n个图像中提取SIFT特征
II.使用k-d树为每个要素找到k个最近邻居
III.对于每个图像:(i)选择与该图像具有最多特征匹配的m个候选匹配图像
(ii)使用RANSAC找出几何一致的特征匹配,以求解图像对之间的单应性
(iii)使用概率模型验证图像匹配
IV 查找图像匹配的连接组件
V.对于每个连接的组件:(i)执行束调整以解决所有摄像机的旋转θ1 θ2 θ3和焦距f
(ii)使用多波段混合渲染全景
输出:全景图像

这导致高频带(小kσ)在短距离内混合,而低频带(大kσ)在较大范围内混合(见图(6))。
请注意,我们选择以球坐标θ,ϕ渲染全景图。原则上,可以选择视点周围的表面的任何二维参数化以进行渲染。一个很好的选择是渲染到三角形球体,在图像平面中构建混合权重。这将具有均匀处理所有图像的优点,并且还允许容易地重新采样到其他表面(在图形硬件中)。请注意,θ,ϕ参数化存在极点的奇点。

图8.使用旋转和缩放进行拼接。尽管输入图像中的旋转,变焦和光照变化,但我们使用不变特征可以实现拼接。这里塔底和顶端的插图图像是其他图像比例的4倍。

图9.带有径向变形的缝合。该图显示了对一阶径向畸变x' = (1 +κ |x| 2)x的拼接效果,其中κ在κ ε[-0.5,0.5]范围内(图像高度归一化为单位长度)。请注意,在我们的算法中没有建模径向失真。我们使用了44个图像的测试序列,并应用了20个κ值的径向畸变。图(d) - (h)给出了失真图像的例子。为了评估缝合的性能,我们计算了RANSAC后一致匹配的数量,结果如图(a)所示。尽管在最坏的情况下每个特征的匹配数量减少了大约三分之一,但正确的特征匹配数仍然很高(每个图像大约500个),因此图像仍然可以成功匹配。然而,如图(b) - (c)所示,径向畸变会导致渲染中出现明显的伪影,并且在束调整和渲染阶段对此进行校正对于高质量的全景拼接非常重要。

图10.困难的拼接问题。这个例子(来自纽约时代广场)包含许多移动物体和图像之间亮度的大变化。尽管存在这些挑战,我们的方法仍能够找到一致的不变特征集,并正确地注册图像。未来的自动图像拼接器可以检测运动物体,并计算场景的高动态范围辐射图。这将使用户能够使用不同的曝光设置和移动的对象来“重新拍摄”场景。
8.结果
图2显示了全景识别算法的典型操作。输入包含4个全景图和4个噪声图像的一组图像。该算法检测图像匹配和不匹配图像的连通分量,并输出4个混合全景图。
图5显示了一个更大的例子。这个序列是使用相机的自动模式拍摄的,这样可以使光圈和曝光时间发生变化,并且可以在某些图像上显示闪光。尽管照明发生了这些变化,但SIFT功能可以很好地匹配,并且多频段混合策略可以产生无缝的全景。输出为360 * 100°,并以球面坐标(θ,ϕ)渲染。所有57个图像完全自动匹配,无用户输入,并且最终注册解决了4×57 = 228参数优化问题。2272×1704像素输入图像在60秒内匹配并记录,并且再拍摄15分钟以呈现8908×2552(23百万像素)输出全景。在57秒内渲染了2000×573预览。测试是在1.6 GHz Pentium M上进行的。
9.结论
本文介绍了一种全新的全自动全景拼接系统。我们使用不变的局部特征和概率模型来验证图像匹配,这使我们能够识别无序图像集中的多个全景图,并在没有用户输入的情况下完全自动缝合它们。该系统对于相机变焦,输入图像的方向以及由闪光和曝光/光圈设置引起的照明变化非常稳健。多频段混合方案确保了图像之间的平滑过渡,尽管存在照明差异,同时保留了高频细节。
未来的工作
未来工作的可能领域包括补偿相机和场景中的运动,以及更高级的相机几何和光度特性建模:
相机运动。由于光学中心的小运动,全景图经常遭受视差错误。在从中心点重新渲染之前,可以通过求解场景中的相机平移和深度来移除这些。使用的良好表现可能是平面上的平面加上视差(Rother和Carlsson,2002)。虽然粗略的相机运动会导致视差伪影,但拍摄期间的小动作会导致运动模糊。运动模糊图像可以使用附近的焦点图像进行去模糊,如Bascle等人所述。 (1996)。类似的技术也可用于生成超分辨率图像(Capel和Zisserman,1998)。
场景动作。尽管我们的多波段混合策略在许多情况下运行良好,但是当在多个图像之间进行混合时,场景中的大对象运动会导致可见的伪影(参见图10)。另一种方法是基于图像之间的差异区域自动找到最佳接缝线(Davis,1998; Uyttendaele等,2001; Agarwala等,2004)。
高级相机建模。大多数相机中不包括在投影相机模型中(保留直线)的一个重要特征是径向失真(Brown,1971)。虽然我们的算法没有明确地建模,但我们有在适度的径向变形量下测试了性能(见图9)。虽然在我们的实验中全景识别和近似对齐对于径向失真是稳健的,但是在渲染结果中存在明显的伪像。因此,高质量图像拼接应用将需要至少在束调整和渲染阶段中包括径向畸变参数。理想的图像拼接器还将支持多个运动模型,例如,围绕点旋转(例如全景图),观察平面(例如白板)和欧几里德变换(例如对齐扫描图像)。还可以渲染多种表面类型,例如球形,圆柱形,平面。
光度建模。原则上,还应该可以估计相机的许多光度参数。渐晕(朝向图像边缘的强度降低)是伪影的常见来源,特别是在诸如天空的均匀颜色区域中(Goldman和Chen,2005)。人们还可以从重叠图像区域获得高动态范围(Debevec和Malik,1997; Seetzen等,2004)信息,并渲染色调映射或合成曝光图像。
我们开发了一个C++ 实现本文所述的算法,称为Autostitch。该程序的演示可以从http://www.autostitch.net下载。
参考文献
Agarwala, A., Dontcheva, M., Agarwala, M., Drucker, S., Colburn, A., Curless, B., Salesin, D., and Cohen, M. 2004. Interactive digital photomontage. In ACM Transactions on Graphics (SIGGRAPH’04).
Burt, P. and Adelson, E. 1983. A multiresolution spline with application to image mosaics. ACM Transactions on Graphics, 2(4):217–236.
Bascle, B., Blake, A., and Zisserman, A. 1996. Motion deblurring and super-resolution from and image sequence. In Proceedings of the 4th European Conference on Computer Vision (ECCV96). Springer-Verlag, pp. 312–320.
Beis, J. and Lowe, D. 1997. Shape indexing using approximate nearestneighbor search in high-dimensional spaces. In Proceedings of the Interational Conference on Computer Vision and Pattern Recognition (CVPR97), pp. 1000–1006.
Brown, M. and Lowe, D. 2003. Recognising panoramas. In Proceedings
of the 9th International Conference on Computer Vision (ICCV03). Nice, vol. 2, pp. 1218–1225.
Brown, D. 1971. Close-range camera calibration. Photogrammetric Engineering, 37(8):855–866.
Brown, M., Szeliski, R., and Winder, S. 2005. Multi-image matching using multi-scale oriented patches. In Proceedings of the Interational Conference on Computer Vision and Pattern Recognition (CVPR05).San Diego.
Chen, S. 1995. Quick Time VR—An image-based approach to virtual environment navigation. In SIGGRAPH’95, vol. 29, pp. 29–38.
Capel, D. and Zisserman, A. 1998. Automated mosaicing with superresolution zoom. In Proceedings of the Interational Conference on Computer Vision and Pattern Recognition (CVPR98), pp. 885–891.
Davis, J. 1998. Mosaics of scenes with moving objects. In Proceedings of the Interational Conference on Computer Vision and Pattern Recognition (CVPR98), pp. 354–360.
Debevec, P. and Malik, J. 1997. Recovering high dynamic range radiance maps from photographs. Computer Graphics, 31:369–378.
Fischler, M. and Bolles, R. 1981. Random sample consensus: A paradigm for model fitting with application to image analysis and automated cartography. Communications of the ACM, 24:381–395.
Goldman, D.B. and Chen, J.H. 2005 Vignette and exposure calibation and compensation. In Proceedings of the 10th International Conference on Computer Vision (ICCV05), pp. I:899–906.
Harris, C. 1992. Geometry from visual motion. In Blake, A. and Yuille, A., (eds.), Active Vision. MIT Press, pp. 263–284.
Huber P.J. 1981. Robust Statistics. Wiley.
Hartley, R. and Zisserman, A. 2004. Multiple View Geometry in Computer Vision, 2nd edn. Cambridge University Press, ISBN:0521540518.
Irani, M. and Anandan, P. 1999. About direct methods. In Triggs, B., Zisserman, A., and Szeliski, R. (eds.), Vision Algorithms: Theory and Practice, number 1883 in LNCS. Springer-Verlag, Corfu, Greece, pp. 267–277.
Lowe, D. 2004. Distinctive image features from scale-invariant keypoints.International Journal of Computer Vision, 60(2):91–110.
Meehan, J. 1990. Panoramic Photography. Amphoto Books.
Milgram, D. 1975. Computer methods for creating photomosaics. IEEE Transactions on Computers, C-24 (11):1113–1119.
McLauchlan, P. and Jaenicke, A. 2002. Image mosaicing using sequential bundle adjustment. Image and Vision Computing, 20(9–10):751–759.
Microsoft Digital Image Pro. http://www.microsoft.com/products/imaging.
Rother, C. and Carlsson, S. 2002. Linear multi view reconstruction and camera recovery using a reference plane. International Journal of Computer Vision, 49(2/3):117–141. Realviz. http://www.realviz.com.
Seetzen, H., Heidrich, W., Stuerzlinger, W., Ward, G., Whitehead, L., Trentacoste, M., Ghosh, A., and Vorozcovs, A. 2004. High dynamic range display systems. In ACM Transactions on Graphics (SIGGRAPH’04).
Szeliski, R. and Kang, S. 1995. Direct methods for visual scene reconstruction. In IEEE Workshop on Representations of Visual Scenes. Cambridge, MA, pp. 26–33.
Sawhney, H. and Kumar, R. 1999. True multi-image alignment and its application to mosaicing and lens distortion correction. IEEE Transactios on Pattern Analysis and Machine Intelligence, 21(3):235–243.
Szeliski, R. and Shum, H. 1997. Creating full view panoramic image mosaics and environment maps. Computer Graphics (SIGGRAPH’97), 31(Annual Conference Series):251–258.
Shum, H. and Szeliski, R. 2000. Construction of panoramic mosaics with global and local alignment. International Journal of Computer Vision, 36(2):101–130.
Shi, J. and Tomasi, C. 1994. Good features to track. In Proceedings of the Interational Conference on Computer Vision and Pattern Recognition (CVPR94). Seattle.
Sivic, J. and Zisserman, A. 2003. Video Google: A text retrieval approach to object matching in videos. In Proceedings of the 9th International Conference on Computer Vision (ICCV03).
Szeliski, R. 2004. Image alignment and stitching: A tutorial. Technical Report MSR-TR-2004-92, Microsoft Research.
Triggs, W., McLauchlan, P., Hartley, R., and Fitzgibbon, A. 1999. Bundle adjustment: A modern synthesis. In Vision Algorithms: Theory and Practice, number 1883 in LNCS. Springer-Verlag. Corfu, Greece, pp. 298–373.
Torr, P. 2002. Bayesian model estimation and selection for epipolar geometry and generic manifold fitting. International Journal of Computer Vision, 50(1):35–61.
Uyttendaele, M., Eden, A., and Szeliski, R. 2001. Eliminating ghosting and exposure artifacts in image mosaics. In Proceedings of the Interational Conference on Computer Vision and Pattern Recognition (CVPR01). Kauai, Hawaii, vol. 2, pp. 509–516.
Zoghlami, I., Faugeras, O., and Deriche, R. 1997. Using geometric corners to build a 2D mosaic from a set of images. In Proceedings of the International Conference on Computer Vision and Pattern Recognition, Puerto Rico. IEEE.
posted on 2019-10-08 11:12 Alliswell_WP 阅读(767) 评论(1) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号