数据库编程——Oracle SQL
在学习数据库编程总结了笔记,并分享出来。有问题请及时联系博主:Alliswell_WP,转载请注明出处。
09-数据库编程day02(oracle sql)
目录:
一、学习目标
二、复习
三、Oracle SQL语句
1、多表查询的理论基础
2、等值连接、不等值连接
3、外连接
4、自连接
5、子查询
6、plsqldevloper介绍
7、集合运算
8、新增数据
9、修改和删除数据
10、delete与truncate
11、事务相关的概念
12、事务控制
13、练习及答案
一、学习目标
1.多表查询编写
2.子查询编写
3.集合运算
4.数据的增删改操作
5.top-N问题解决
6.事务的相关概念
二、复习
1、安装的注意事项:目录不能有中文和空格
2、oracle的体系结构:实例+数据文件, 实例-- 用户(方案) --- 表
》oracle登录不了,排查问题:
--Windows查看两个服务:
OracleServiceORCL c:\app\administrator\product\11.2.0\dbhome_1\bin\ORACLE.EXE
ORCL OracleOraDb11g_home1TNSListener C:\app\Administrator\product\11.2.0\dbhome_1\BIN \TNSLSNR
--Linux查看:
登录管理员:
oracle用户:sqlplus / as sysdba
SQL>startup (启动实例)
shell:lsnrctl start (启动监听)
连接命令:sqlplus scott/11@//ip/orcl
3、登录说明

上图为配置了tns配置文件的登录方式,orcl00为网络实例别名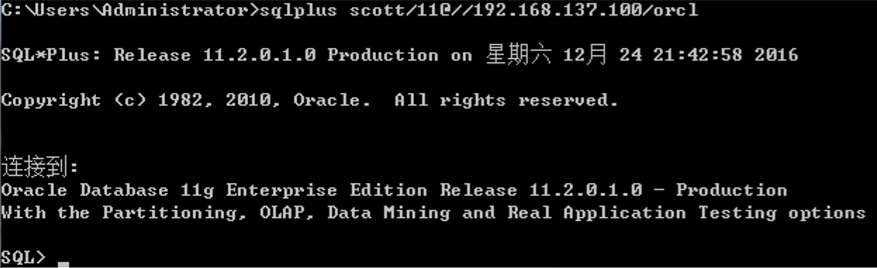
上图为比较直接登录网络服务器的方式@后指定了对应的主机192.168.137.100 的对应实例 orcl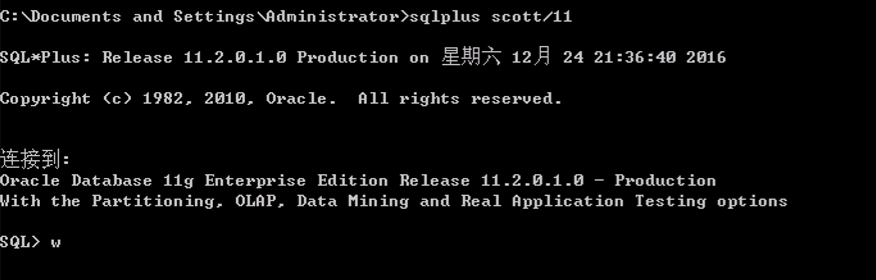
上图为在服务器本机的连接方式,此时可以不走侦听,所以后面不用加@
4、查询
(1)select 查询可以全部列,部分列,表达式,别名
(2)distinct的作用:去除重复行
(3)where 条件过滤:比较运算符(!= <> ),逻辑运算符(and or ),在集合中
(4)(not in 的集合中不能有null),模糊查询(like % _ escape)
(5)between and的特点:闭区间,从小到大
(6)order by 排序可以按列名,别名,表达式,序号(序号为排序结果的第几列)
(7)asc 和 desc 的作用和说明:升序和降序,asc默认,作用域,它之前的 一个字段
(8)group by 分组的要求:在select中出现的非组函数的列,必须在group中 出现
(9)having 的作用:和group一起使用,对分组的数据进行过滤 . where后不 能使用组函数.如果都能用的情况用where.
5、 null的总结
○ 表达式与null运算结果为null
○ 不能用= 或者!=
○ not in的集合中不能有null
○ null无穷大,排序默认在最后nvl(a,b) 如果a为null,返回b,否则返回a
○ 组函数自动过滤空
6、回顾练习
(1)求10号部门的最低薪水和最高薪水
SQL>select min(sal),max(sal) from emp where deptno=10;
(2)求1980年12月17日入职的员工信息
SQL>select * from emp where hiredate=to_date('1980-12-17','yyyy-mm-dd');
SQL>select * from emp where to_char(hiredate,'yyyy-mm-dd')='1980-12-17';
(3)求当前日期所在的月份的最后一天和第一天,显示格式为:yyyymmdd
SQL>select to_char(last_day(sysdate),'yyyymmdd'),to_char(sysdate,'yyyymm')||'01' from dual;
(4)查询名字中有字母A,并且是 MANAGER 的员工
SQL>select * from emp where ename like '%A%' and job='MANAGER';
(5)将员工信息按照部门倒序,薪水升序排列
SQL>select * from emp order by deptno desc,sal asc;
(6)求薪资在1200以上的员工数
SQL>select count(*) from emp where sal > 1200;
三、Oracle SQL语句
1、多表查询的理论基础
》笛卡尔集:
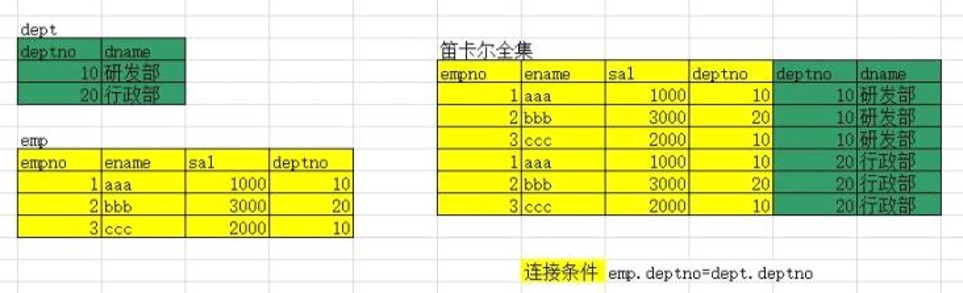
笛卡尔集行数= 表1的行数 * 表2的行数
列数 = 表1的列数 + 表2的列数
2张表的连接条件需要一个
N张表的连接条件需要N-1
2、等值连接、不等值连接
》需求:查询员工信息:员工号 姓名 月薪(emp)和部门名称(dept)
多表查询的写法:
○ 表名.列名
○ 给表起个别名,别名.列名
--等值连接
select empno, ename, sal, dname from emp e, dept d where e.deptno = d.deptno;
select e.empno, ename, sal, dname,e.deptno from emp e, dept d where e.deptno = d.deptno
--不等值连接
--查询员工信息:员工号 姓名 月薪 和 薪水级别(salgrade表)
select e.empno,e.ename,e.sal,s.grade from emp e,salgrade s where e.sal >= s.losal and e.sal <= s.hisal;
--between and的写法 select e.empno,e.ename,e.sal,s.grade from emp e,salgrade s where e.sal between s.losal and s.hisal
3、外连接
》需求:按部门统计员工人数,显示如下信息:部门号 部门名称 人数
select d.deptno,d.dname,count(*) from emp e,dept d where e.deptno=d.deptno group by d.deptno,d.dname
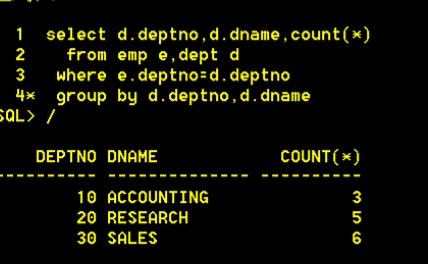
上述结果缺少40 部门的信息,由于没有40号部门,怎么解决?
》使用外连接:当等值连接条件不成立的时候,想保留等号一边的 数据
外连接写法:
--右外连接 ——想保留等号右边的数据,在等号左边添加 (+)
select d.deptno,d.dname,count(e.empno) from emp e,dept d where e.deptno(+)=d.deptno group by d.deptno,d.dname order by 1
--左外连接
select d.deptno,d.dname,count(e.empno) from emp e,dept d where d.deptno=e.deptno(+) group by d.deptno,d.dname order by 1
4、自连接
》需求:查询员工信息:xxx的老板是yyy
需要使用自连接
○ 数据都在同一个表
○ 数据不在同一行
》口诀:当成2张表,员工表和老板表,员工表的老板是老板表的 员工
select e.ename||'''s boss is '||b.ename from emp e,emp b where e.mgr = b.empno
上述写法缺少大老板,使用外连接,保留等号左边数据
select e.ename||'''s boss is '||nvl(b.ename,'himself') from emp e,emp b where e.mgr = b.empno(+)
》自连接有何弊端?
○笛卡尔集会平方的增长
○尽量避免使用
5、子查询
》需求:查询比scott工资高的员工信息?
可以分步做
○ 得到scott的工资 select sal from emp where ename ='SCOTT';
○ 查询大于这个工资的员工 select * from emp where sal > 3000;
要求一次搞定:使用子查询技术
子查询写法:
select * from emp where sal > (select sal from emp where ename ='SCOTT');
子查询的本质:sql嵌套sql,解决一次查询不能返回的问题
*****子查询10点注意事项*****
1)合理的书写风格(如上例,当写一个较复杂的子查询的时候,要合理的添加换行、缩进)
2)小括号( )
3)主查询和子查询可以是不同表,只要子查询返回的结果主查询可以使用即可
--查询部门名称是“SALES”的员工信息
分步做:1.先得到部门编号 2.通过部门编号得到员工信息
select deptno from dept where dname ='SALES';
select * from emp where deptno=30;
===>变成子查询 select * from emp where deptno=(select deptno from dept where dname ='SALES');
4)可以在主查询的where、select、having、from后都可以放置子查询
select …
from …
where …
group by … err报错(即err报错处不能写)
having …
order by … err报错
--select后 查询10号部门员工号,员工姓名,部门编号,部门名称
——多表查询写法
select e.empno,e.ename,e.deptno,d.dname
from emp e,dept d
where e.deptno=d.deptno
and e.deptno=10
——子查询写法
select e.empno,e.ename,e.deptno,(select dname from dept where deptno=10) dname
from emp e
where e.deptno=10
--from后 查询员工的姓名、薪水和年薪:说明:该问题不用子查询也可以完成。但如果是一道填空 题:select * from ___________________
select * from (select ename,sal,sal*16 from emp);
——注意:from后放置的是集合,你可以理解一个新的表
--where后 查询与ward相同job并且薪水比他高的员工信息
第一步:得到ward的job和sal
第二步:根据job和sal确定人
select job,sal from emp where ename='WARD';
select * from emp where sal> 1250 and job ='SALESMAN';
===>变成子查询
select * from emp where sal> (select sal from emp where ename='WARD') and job =(select job from emp where ename='WARD');
--having后 查询高于30号部门最低薪水的部门及其最低薪水
先得到30部门的最低薪水
select min(sal) from emp where deptno=30;
最低薪水大于950的部门及其最低薪水
select deptno,min(sal) from emp group by deptno having min(sal) > 950;
===>子查询写法 select deptno,min(sal) from emp group by deptno having min(sal) > (select min(sal) from emp where deptno=30);
5)不可以在主查询的group by后面放置子查询(SQL语句的语法规范)
6)强调:在from后面放置的子查询(***) from后面放置是一个集合(表、查询结果)
7)单行子查询只能使用单行操作符(>,<,=);多行子查询只能使用多行操作符
》举例说明:
--多行操作符有IN ANY(任意一个) ALL (所有)
--查询部门名称为SALES和ACCOUNTING的员工信息
得到对应的部门编号
select * from dept where dname='SALES' or dname='ACCOUNTING';
得到10和30部门的员工
select * from emp where deptno in (10,30);
===>变成子查询
select * from emp where deptno in (select deptno from dept where dname='SALES' or dname='ACCOUNTING');

--查询薪水比30号部门任意一个(某一个 ANY )员工高的员工信息 (有歧义)
比最低的高就可以
select min(sal) from emp where deptno=30;
select * from emp where sal > 950;
===>变成子查询:select * from emp where sal > (select min(sal) from emp where deptno=30);
使用多行操作符
select * from emp where sal > ANY (select sal from emp where deptno=30);
--查询比30号部门所有人工资高的员工信息
select * from emp where sal > ALL (select sal from emp where deptno=30);
select * from emp where sal > (select max(sal) from emp where deptno=30);
8)子查询中的null值
--查询不是老板的员工信息
□ 查询谁是老板
select * from emp where empno in( select distinct mgr from emp) ;
□ 查询不是老板
select * from emp where empno not in( select distinct mgr from emp) ;
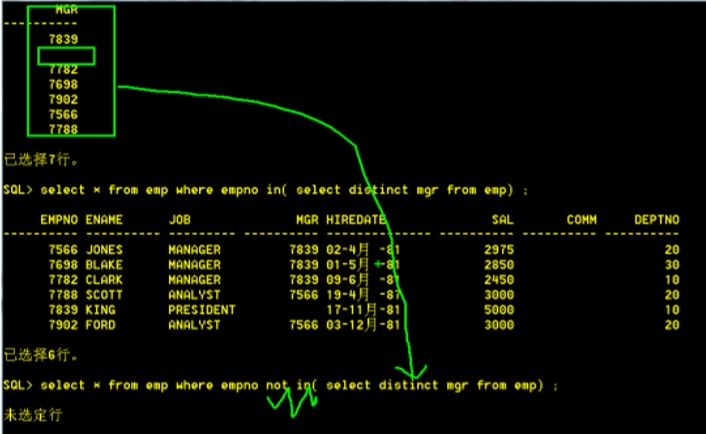
没有结果?not in 的集合中不能有null
select * from emp where empno not in( select distinct mgr from emp where mgr is not null);
9)一般先执行子查询(内查询),再执行主查询(外查询);但是相关子查询除外
10)一般不在子查询中使用order by, 但在Top-N分析问题中,必须使用order by
6、plsqldevloper介绍
PLSQL Developer是Oracle数据库开发工具,很牛也很好用,PLSQL Developer功能很强大,可以做为集成调试器,有SQL窗口,命令窗口,对象浏览器和性能优化等功能。
1)首先确保有oracle数据库或者有oracle服务器,然后才能使用PLSQL Developer连接数据库;
2)启动PLSQL Developer,登陆oracle用户账号后连接(这里不详细介绍如何配置tnsname.ora)了;
3)登陆成功后即可进入对象浏览器窗口界面;
4)在对象浏览器选择“my object”,这里边就是SCOTT(当前登陆的用户的所有object);
5)找到table文件夹,里边就是当前账户的所有表格
6)New——》选中Command Window,即可打开命令窗口;然后执行各种指令(和SQL语句相同,需要加分号);
7)New——》选中SQL Window,即可打开sql窗口了;在sql窗口内输入sql语句(一条不用加分号;可以输入多条,最后一条不用加分号“;”),全选,点击执行即可查看到结果,功能很强大
可以拷贝到excel:点击查询后的数据,右键选择“Copy to Excel”->“Copy as xls..”
可以把excel导入到表中:
先输入SQL命令:create table dept_bak as select * from dept where 1=2;(然后选中执行)
再输入SQL命令查看:select * from dept_bak for update(然后选中执行)
点击查询数据任务栏上的“🔒”解锁,然后在excel中Ctrl+c复制数据,到查询的数据处先点击表格一下,再点击标签一下,然后Ctrl+v,再点击查询数据任务栏上“✔”,再点击查询数据任务栏上的“🔒”锁上,然后点击菜单栏上的“Commit 提交”按钮(看着像下载的按钮)。
然后,选中select * from dept_bak(选中执行)
8)优化:点击菜单栏“Tools”的“Preferences”,然后在左侧选择“Key Configuration”,在右侧设置快捷键(为经常使用的Command Window和SQL Window设置快捷键)。
9)优化:点击菜单栏“🔑”,选中“Confiure”,然后优化:点击“Tools”的“Preferences”,然后在左侧选择“Logon History”,在右侧“Fixed Users”中填入经常登录的用户信息。
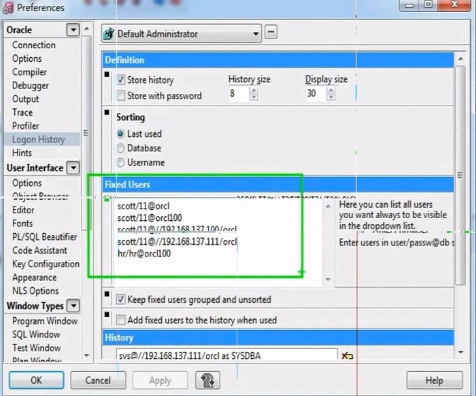
点击菜单栏“🔑”,即可快速切换不同的用户。(将用户信息保存到txt中,如果重装软件的话,直接粘贴复制到此处,方便登录。)


scott/11@orcl scott/11@orcl100 scott/11@//192.168.137.100/orcl scott/11@//192.168.137.111/orcl hr/hr@orcl100
10)美化:点击菜单栏“PL/SQL Beautiful”可以美化SQL代码。
7、集合运算

并集:
○ union 两个集合相同的部分保留一份
○ union all 两个集合相同的部分都保留
交集:
○ intersect 两个集合交集只保留相同的部分
差集:
○ minus 集合A-集合B,保留A中与B不同的部分
》练习:
并集:
select * from emp where deptno = 10 union select * from emp where deptno=20;
select * from emp where deptno = 10 union select * from emp where deptno in(20,10);
select * from emp where deptno = 10 union all select * from emp where deptno in(20,10);
交集:
select * from emp where deptno = 10 intersect select * from emp where deptno in(20,10);
差集:
select * from emp where deptno in(10,30) minus select * from emp where deptno in(20,10);
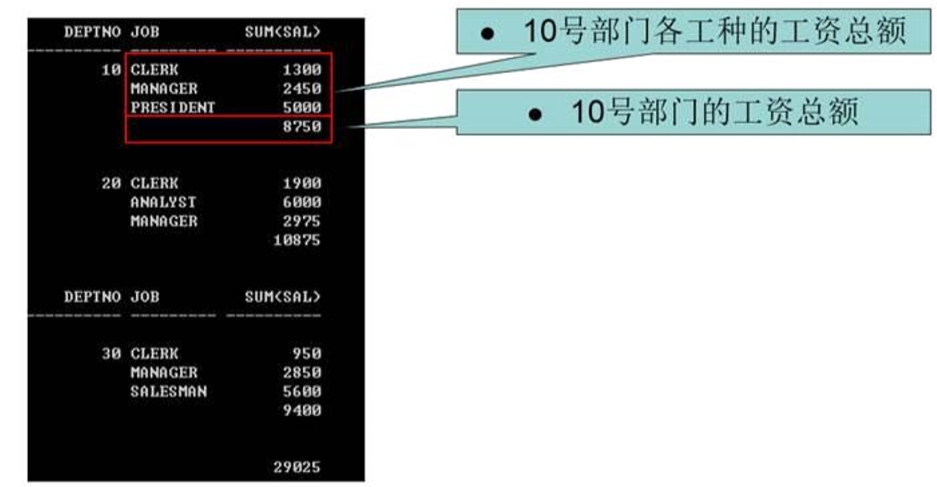
第一个集合:各个部门,各个工种的总工资
第二个集合:各个部门的总工资
第三个集合:总工资
select deptno,job,sum(sal) from emp group by deptno,job
union
select deptno,sum(sal) from emp group by deptno
union
select sum(sal) from emp

》集合注意事项:
1)参与运算的各个集合必须列数相同,且类型一致。
2)用第一个集合的表头作为最终使用的表头。 (别名也只能在第一个集合上起)
3)可以使用括号()先执行后面的语句
上述结果错误的原因,类型不一致,列数不相同
select deptno,job,sum(sal) from emp group by deptno,job
union
select deptno,to_char(null),sum(sal) from emp group by deptno
union
select to_number(null),to_char(null),sum(sal) from emp
扩:报表显示设置
break on deptno skip 2;
关闭显示效果
break on null;
8、新增数据
》SQL语言的类型:
○ DML data manipulation language 数据操作语言,对应增删改查
○ DDL data definition language 数据定义语言create |truncate |O_TRUNC
○ DCL data control language 数据控制语言grant,revoke
》新增数据:insert
○语法:insert into tablename[col1,…] values(val1,…);
insert into dept values(51,'51name','51loc');
--隐式插入null
insert into dept(deptno,dname) values(52,'52name');
--显示插入null
insert into dept(deptno,dname,loc) values(53,'53name',null);
&符号的使用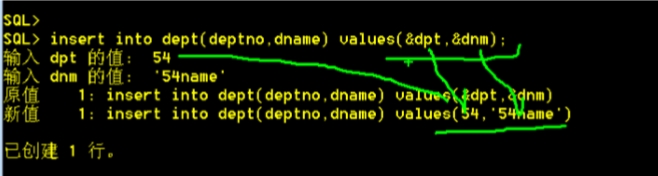

SQL> insert into dept(deptno,dname) values(&dpt,'&dnm');
输入dpt 的值: 56
输入dnm 的值: 56name
原值 1: insert into dept(deptno,dname) values(&dpt,'&dnm')
新值 1: insert into dept(deptno,dname) values(56,'56name')
已创建1 行。
》创建一个与emp相同结构的表,不拷贝数据(1等于2不成立,所以只拷贝了表结构,如果想备份表:create table emp10 as select * from emp;)
create table emp10 as select * from emp where 1=2;
可用于做项目中创建表—如:

》批量插入:
insert into emp10 select * from emp where deptno=10;
9、修改和删除数据
》修改数据:update—注意安全
○ 语法:update tablename set col1=val1,col2=val2,… where cond;
○ 举例
原数据为:
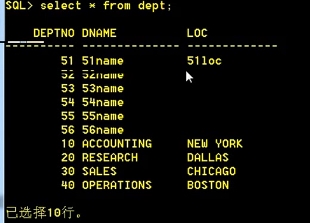
▪ update dept set loc='52loc' where deptno=52;
▪ update dept set loc=null where deptno=52;--设置的时候,null可以使用等号
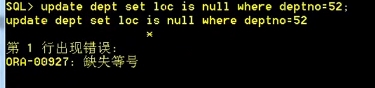
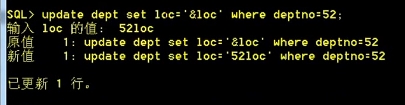
支持地址符号:
》删除数据:delete —注意安全 ,做好备份
○ 用法:delete from tablename where cond;
○ 举例
删除前数据为:
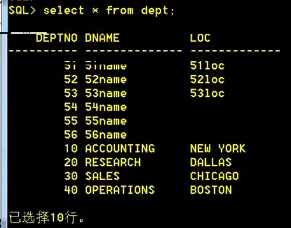
▪ delete from dept where deptno =56;
▪ delete from dept where deptno >53;
▪ delete from dept where deptno =&dpt;
》结论:DML语句都可以使用&
10、delete与truncate
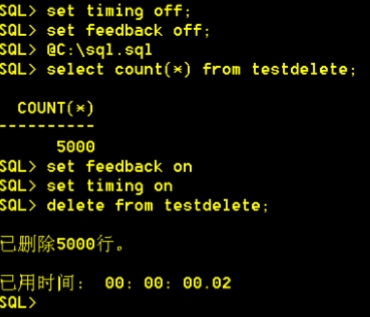
【做实验sql.sql】:验证delete和truncate的时效性。终端里@c:\sql.sql可以执行脚本sql.sql
语句执行时间记录开关:set timing on/off
回显开关:set feedback on/off
【测试步骤】:
1. 关闭开关:SQL> set timing off; SQL> set feedback off;
2. 使用脚本创建表:SQL> @c:\sql.sql
3. 打开时间开关:SQL> set timing on;
4. 使用delete删除表内容:SQL> delete from testdelete;
5. 删除表:SQL> drop table testdelete purge;
6. 关闭时间开关:SQL> set timing off;
7. 使用脚本创建表:SQL> @c:\sql.sql
8. 打开时间开关:SQL> set timing on;
9. 使用truncate删除表内容:SQL> truncate table testdelete;
》测试
先delete测试:
首先在把sql.sql放置到相应目录,(我的为:C:\sql.sql)——sql.sql代表较长,此处代码插入不了。
再删除表 drop table testdelete purge;
然后,使用truncate测试步骤: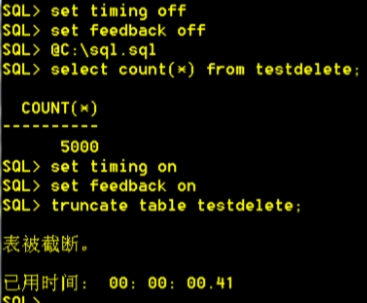
》结论:当前数量级delete更快,当数量级特别大的时候,truncate更快 truncate 先摧毁表,再重建。
delete 是逐行删除。
》delete 和 truncate的区别:
1.delete 逐条删除表“内容”,truncate 先摧毁表再重建。
(由于delete使用频繁,Oracle对delete优化后delete快于truncate)
2.delete 是DML语句,truncate 是DDL语句。
DML语句可以闪回(flashback),DDL语句不可以闪回。
(闪回: 做错了一个操作并且commit了,对应的撤销行为。了解)
3.由于delete是逐条操作数据,所以delete会产生碎片,truncate不会产生碎片。
(同样是由于Oracle对delete进行了优化,让delete不产生碎片)。
两个数据之间的数据被删除,删除的数据——碎片,整理碎片,数据连续,行移动【图示】
4.delete不会释放空间,truncate 会释放空间
用delete删除一张10M的表,空间不会释放。而truncate会。所以当确定表不再使用,应truncate
5.delete可以回滚rollback,truncate不可以回滚rollback。
11、事务相关的概念
》需求:
银行转账: 最核心的步骤 A --- > B 1000 rmb
A账户- 1000 ok
B账户+1000 失败
这样导致银行帐不平
程序员需要恢复之前的数据修改操作。
操作n个表,m个字段
insert into tabname(col1,..) values(val1,…); ---->delete
update ------- update
恢复数据难度很大?
所以使用数据库的事务!
什么是事务?
以DML语句开始,执行一系列数据修改的操作
事务特点:要么一起成功,要么一起失败
事务结束:
○ 提交结束 commit
▪ 显式提交:commit;
▪ 隐式提交:执行了DDL语句(create,truncate),正常退出(quit)
回滚结束rollback
▪ 显式回滚:rollbac
▪ 隐式回滚:掉电,宕机,异常退出(点叉子)
》事务有四个特性(ACID):原子性,一致性,隔离型,持久性
○原子性 (Atomicity):事务中的全部操作在数据库中是不可分割的,要么全部完成,要么均不执行。
○一致性 (Consistency):几个并行执行的事务,其执行结果必须与按某一顺序串行执行的结果相一致。
○隔离性 (Isolation):事务的执行不受其他事务的干扰,当数据库被多个客户端并发访问时,隔离它们的操作,防止出现:脏读、幻读、不可重复读。
○持久性 (Durability):对于任意已提交事务,系统必须保证该事务对数据库的改变不被丢失,即使数据库出现故障。
•脏读: 对于两个事物 T1, T2, T1 读取了已经被 T2 更新但还没有被提交的字段. 之后, 若 T2 回滚, T1读取的内容就是临时且无效的.
•不可重复读: 对于两个事物 T1, T2, T1 读取了一个字段, 然后 T2 更新了该字段. 之后, T1再次读取同一个字段, 值就不同了.
•幻读: 对于两个事物 T1, T2, T1 从一个表中读取了一个字段, 然后 T2 在该表中插入了一些新的行. 之后, 如果 T1 再次读取同一个表, 就会多出几行.
》数据库事务的隔离性: 数据库系统必须具有隔离并发运行各个事务的能力, 使它们不会相互影响, 避免各种并发问题.
一个事务与其他事务隔离的程度称为隔离级别. 数据库规定了多种事务隔离级别, 不同隔离级别对应不同的干扰程度, 隔离级别越高, 数据一致性就越好, 但并发性越弱
SQL99定义4中隔离级别:
1. Read Uncommitted读未提交数据。
2.Read Commited读已提交数据。(Oracle默认)
3.Repeatable Read可重复读。(MySQL默认)
4.Serializable序列化、串行化。 (查询也要等前一个事务结束)
这4种MySQL都支持
》Oracle支持的隔离级别:Read Commited(默认)和 Serializable,以及Oracle自定义的Read Only三种。(oracle支持上述2,4隔离级别 支持三个,还有一个自定义的:read-only )
Read Only:由于大多数情况下,在事务操作的过程中,不希望别人也来操作,但是如果将别人的隔离级别设置为Serializable(串行),但是单线程会导致数据库的性能太差。是应该允许别人来进行read操作的。
》练习:
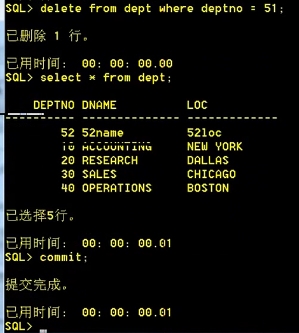
登录两个客户端,原dept表有6条数据:一个客户端删除一条数据,commit未提交时,另一个客户端仍显示6条数据,当执行commit提交后,另一个客户端显示5条数据。

12、事务控制
》savepoint:保存点(savepoint)可以防止错误操作影响整个事务,方便进行事务控制。

【示例】:
1. SQL> create table testsp ( tid number, tname varchar2(20));
DDL语句会隐式commit之前操作
2. set feedback on
打开回显
3. insert into testsp values(1, 'Tom')
4. insert into testsp values(2, 'Mary')
5. savepoint aaa
6. insert into testsp values(3, 'Moke')
故意将“Mike”错写成“Moke”。
7. select * from testsp
三条数据都显示出来。
8. rollback to savepoint aaa
回滚到保存点aaa
9. select * from testsp
发现表中的数据保存到第二条操作结束的位置
10.rollback ;
——事务结束(表在,数据不在)
select * from testsp;
需要注意,前两次的操作仍然没有提交。如操作完成应该显示的执行 commit 提交。
savepoint主要用于在事务上下文中声明一个中间标记,将一个长事务分隔为多个较小的部分,和我们编写文档时,习惯性保存一下一样,都是为了防止出错和丢失。如果保存点设置名称重复,则会删除之前的那个保存点。一但commit之后,savepoint将失效。
注意:当已经回退到aaa,此时不能再回退到bbb

13、练习及答案
(1)题目
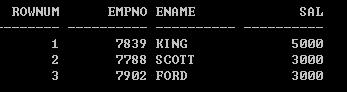
【第一题】:找到员工表中工资最高的前三名, 要求按如下格式输出
》第一题提示:
——涉及Top-N分析问题。
一般不在子查询中使用order by, 但在Top-N分析问题中,必须使用order by
》补充知识:rownum 行号(伪列)
SQL> select rownum, empno, ename, sal from emp
借助行号将薪水降序排列。前三条即是我们想要的内容。
SQL> select * from emp order by sal desc 但问题是如何取出前三行。
SQL> select * from emp where rownum <= 3 order by sal 发现取出的结果不正确。
》行号rownum需要注意的问题:
1.rownum永远按照默认的顺序生成。
SQL> select rownum, empno, ename, sal from emp order by sal desc
——发现行号是跟着行走的。查询结果顺序变了,行号依然固定在原来的行上。
行号始终使用默认顺序:select * from emp所得到的顺序,没有排序,没有分组等。
只要能使行号随着重新排序,发生改变,那么取前三条记录,就是我们想要的结果。
2.rownum只能使用<, <=符号,不能使用>,>=符号。
想将现有的表进行分页。1-4第一页,5-8第二页……
SQL> select rownum, empno, ename, sal from emp where rownum >=1 and rownum<=4
SQL> select rownum, empno, ename, sal from emp where rownum >=5 and rownum<=8
执行,发现结果:未选定行。原因是rownum不能使用>=符号。Where永远为假。
与行号生成的机制有关:Oracle中的行号永远从1开始——取了1才能取2,取了2才能取3,……
<=8可以是因为1234567挨着取到,而>=5不行,因为没有1234,不能直接取5。
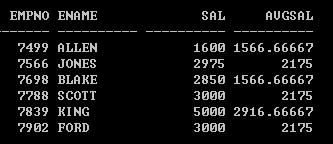
【第二题】:找到emp表中薪水大于本部门平均薪水的员工
【第三题】:统计每年入职的员工个数

——员工的入职年份是已知条件——1980、1981、1982、1987这4个。
要统计每年入职的人数,一定要知道每个员工的入职日期,可以通过查询hiredate列来得到。
SQL> select hiredate from emp;
结合查询结果,以1981年为例,如何统计出81年入职的有多少个人呢?可以从写C程序的角度入手。
思路:定义一个计数器count=0; 有一个81年的员工,就+1,不是81的就+0;最后查看count的值就可以了。
求和,使用sum函数,内部逻辑:sum(if 是81年 then +1 else +0)
也就是取员工的hiredate列的“年”那一部分,与81比较,进行判断。
to_char(hiredate, ‘yyyy’) 得到年,与‘1981’进行比较。
提示:该练习只考察函数的应用,注意调用关系。
(2)分析及答案
【第一题】:
解决该问题,select * from emp order by sal desc 这条查询必须要有,但是排序后行号rownums没有改变,如果可以改变那么问题就可以解决。
select * from emp order by sal desc这条查询结果本身是一个集合,
特点1:emp表所有数据均有,
特点2:已经按薪水降序排列好。
把这条语句的执行结果当成一个表来看待即可。——可以将它放置到“from”后面。
SQL> select rownum, empno, ename, sal from (select * from emp order by sal desc) where rownum <=3
注:语句中所有的rownum所代表的行号是from后面子查询查出来的新行号,而不是emp表默认的行号。
》扩展思考:如何获取5-8行的数据?
只需要将上条语句改成“where rownum <=8”上限即可获得?
SQL> select rownum, empno, ename, sal from (select * from emp order by sal desc) where rownum <=8
关键是 >=5 的获取问题,是不能直接写>=5的。但是这条SQL语句查询的结果是一个新的“集合”,
该集合中有一列是专门表示行号,可以假想这列不再是伪列,而是该集合中专门用来表示行号的列。
所以,可以给该列取一个别名r,并把该查询语句整体作为子查询,放到另外一条SQL语句的from后。
SQL> select * from ( select rownum r, empno, ename, sal from (select * from emp order by sal desc) where rownum <=8 ) where r >=5;
法二:也可以集合做差集,取前8名,减去前4名。——省略
》总计:集合运算一般效率比较低!
【第二题】:
先得到各个部门的平均工资 SQL> select deptno,avg(sal) from emp group by deptno; 看成一个表
接下来的问题就是多表查询
SQL> select e.empno, e.ename, e.sal, d.avgsal from emp e, (select deptno, avg(sal) avgsal from emp group by deptno) d where e.deptno=d.deptno and e.sal > d.avgsal;
》扩展:使用子查询解决?
9)一般先执行子查询(内查询),再执行主查询(外查询);但是相关子查询除外。
10)主查询通过别名,将部门号传递给子查询。
先查询10号部门工资大于本部门平均工资的信息
select e.empno,e.ename,e.sal,(select avg(sal) from emp where deptno=10) avgsal from emp e where e.deptno=10 and e.sal > (select avg(sal) from emp where deptno=10)
变成相关子查询
select e.empno,e.ename,e.sal,(select avg(sal) from emp where deptno=e.deptno) avgsal from emp e where e.sal > (select avg(sal) from emp where deptno=e.deptno)
》上述2个方式哪个更好?
多表查询更好!!!
sql优化的一个最大的前提:尽量避免与数据库的交互
多表查询相当于传说中的空间换时间!!!
【第三题】:
思路:先取出年份,用条件表达式来处理,得到0或者1,便于之 后计数
根据提示,主要使用sum来完成对1和0的求和操作。sum函数内部,是一个if、else判断。实现是使用decode或者case。由于sum是函数,我们同样用函数decode来实现。
——decode():第一个参数:待判断的值,条件,结果,条件,结果……最后是else的情况。
SQL> select count(*) “Total”, sum(decode(to_char(hiredate, 'yyyy'), '1981', 1, 0)) "1981", sum(decode(to_char(hiredate, 'yyyy'), '1980', 1, 0)) "1980", sum(decode(to_char(hiredate, 'yyyy'), '1982', 1, 0)) "1982", sum(decode(to_char(hiredate, 'yyyy'), '1987', 1, 0)) "1987" from emp;
》其他写法:
select count(e.hiredate) total, c1.c "1980", c2.c "1981", c3.c "1982", c4.c "1987" from emp e, (select count(*) c from emp where to_char(hiredate, 'yyyy') = '1980') c1, (select count(*) c from emp where to_char(hiredate, 'yyyy') = '1981') c2, (select count(*) c from emp where to_char(hiredate, 'yyyy') = '1982') c3, (select count(*) c from emp where to_char(hiredate, 'yyyy') = '1987') c4 group by c1.c, c2.c, c3.c, c4.c
select * from (select count(*) "Total" from emp) c0, (select count(*) "1980" from emp where to_char(hiredate, 'yyyy') = '1980') c1, (select count(*) "1981" from emp where to_char(hiredate, 'yyyy') = '1981') c2, (select count(*) "1982" from emp where to_char(hiredate, 'yyyy') = '1982') c3, (select count(*) "1987" from emp where to_char(hiredate, 'yyyy') = '1987') c4
select count(*) Total, sum(CASE hrd when '1980' then 1 END) as "1980", sum(CASE hrd when '1981' then 1 END) as "1981", sum(CASE hrd when '1982' then 1 END) as "1982", sum(CASE hrd when '1987' then 1 END) as "1987" from ( select (to_char(emp.hiredate,'yyyy'))as hrd
from emp )
在学习数据库编程总结了笔记,并分享出来。有问题请及时联系博主:Alliswell_WP,转载请注明出处。
posted on 2020-07-17 18:32 Alliswell_WP 阅读(354) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号