
综合实战篇
倪朋飞 《Linux 性能优化实战》
46 | 案例篇:为什么应用容器化后,启动慢了很多?


容器慢案例:1.资源限制导致OOM机制被杀死;2.资源少导致服务启动慢 ============================================================================================================== 基于 Docker 的微服务架构带来的各种优势,比如: 使用 Docker ,把应用程序以及相关依赖打包到镜像中后,部署和升级更快捷; 把传统的单体应用拆分成多个更小的微服务应用后,每个微服务的功能都更简单,并且可以单独管理和维护; 每个微服务都可以根据需求横向扩展。即使发生故障,也只是局部服务不可用,而不像以前那样,导致整个服务不可用。 jq 工具专门用来在命令行中处理 json。为了更好的展示 json 数据,我们用这个工具,来格式化 json 输出。 ----------------------------------------------------------------------------------------------- 案例的2个根因: 1.对容器进行了资源限制 -m 512M;但是容器内部的真正限制却并不是512M,而是物理机资源额度;然后JVM的堆内存限制是基于物理机资源的,计算出的结果实际超过512M;最终导致了OOM杀死进程 2.给予的CPU资源过少,导致容器服务启动慢 ----------------------------------------------------------------------------------------------- 案例 server端: $ docker run --name tomcat --cpus 0.1 -m 512M -p 8080:8080 -itd feisky/tomcat:8 # -m表示设置内存为512MB [root@yefeng ~]# curl localhost:8080 #本地访问容器服务,响应很慢 Hello, wolrd! [root@yefeng ~]# curl localhost:8080 #过几分钟后,再次访问,服务挂了 curl: (52) Empty reply from server [root@yefeng ~]# docker ps -a #容器已经exit CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 440bcf0b5979 feisky/tomcat:8 "catalina.sh run" 5 minutes ago Exited (137) About a minute ago tomcat [root@yefeng ~]# docker logs -f 440bcf0b5979 #查看容器日志 Using CATALINA_BASE: /usr/local/tomcat Using CATALINA_HOME: /usr/local/tomcat Using CATALINA_TMPDIR: /usr/local/tomcat/temp Using JRE_HOME: /docker-java-home/jre Using CLASSPATH: /usr/local/tomcat/bin/bootstrap.jar:/usr/local/tomcat/bin/tomcat-juli.jar 09-Jul-2022 15:01:19.019 INFO [main] org.apache.catalina.startup.VersionLoggerListener.log Server version: Apache Tomcat/8.5.38 09-Jul-2022 15:01:19.120 INFO [main] org.apache.catalina.startup.VersionLoggerListener.log Server built: Feb 5 2019 11:42:42 UTC 09-Jul-2022 15:01:19.120 INFO [main] org.apache.catalina.startup.VersionLoggerListener.log Server number: 8.5.38.0 09-Jul-2022 15:01:19.120 INFO [main] org.apache.catalina.startup.VersionLoggerListener.log OS Name: Linux 09-Jul-2022 15:01:19.121 INFO [main] org.apache.catalina.startup.VersionLoggerListener.log OS Version: 5.18.3-1.el7.elrepo.x86_64 09-Jul-2022 15:01:19.121 INFO [main] org.apache.catalina.startup.VersionLoggerListener.log Architecture: amd64 09-Jul-2022 15:01:19.121 INFO [main] org.apache.catalina.startup.VersionLoggerListener.log Java Home: /usr/lib/jvm/java-8-openjdk-amd64/jre 09-Jul-2022 15:01:19.121 INFO [main] org.apache.catalina.startup.VersionLoggerListener.log JVM Version: 1.8.0_181-8u181-b13-2~deb9u1-b13 09-Jul-2022 15:01:19.122 INFO [main] org.apache.catalina.startup.VersionLoggerListener.log JVM Vendor: Oracle Corporation 09-Jul-2022 15:01:19.122 INFO [main] org.apache.catalina.startup.VersionLoggerListener.log CATALINA_BASE: /usr/local/tomcat 09-Jul-2022 15:01:19.122 INFO [main] org.apache.catalina.startup.VersionLoggerListener.log CATALINA_HOME: /usr/local/tomcat 09-Jul-2022 15:01:19.123 INFO [main] org.apache.catalina.startup.VersionLoggerListener.log Command line argument: -Djava.util.logging.config.file=/usr/local/tomcat/conf/logging.properties 09-Jul-2022 15:01:19.123 INFO [main] org.apache.catalina.startup.VersionLoggerListener.log Command line argument: -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager 09-Jul-2022 15:01:19.123 INFO [main] org.apache.catalina.startup.VersionLoggerListener.log Command line argument: -Djdk.tls.ephemeralDHKeySize=2048 09-Jul-2022 15:01:19.123 INFO [main] org.apache.catalina.startup.VersionLoggerListener.log Command line argument: -Djava.protocol.handler.pkgs=org.apache.catalina.webresources 09-Jul-2022 15:01:19.218 INFO [main] org.apache.catalina.startup.VersionLoggerListener.log Command line argument: -Dorg.apache.catalina.security.SecurityListener.UMASK=0027 09-Jul-2022 15:01:19.218 INFO [main] org.apache.catalina.startup.VersionLoggerListener.log Command line argument: -Dignore.endorsed.dirs= 09-Jul-2022 15:01:19.218 INFO [main] org.apache.catalina.startup.VersionLoggerListener.log Command line argument: -Dcatalina.base=/usr/local/tomcat 09-Jul-2022 15:01:19.219 INFO [main] org.apache.catalina.startup.VersionLoggerListener.log Command line argument: -Dcatalina.home=/usr/local/tomcat 09-Jul-2022 15:01:19.219 INFO [main] org.apache.catalina.startup.VersionLoggerListener.log Command line argument: -Djava.io.tmpdir=/usr/local/tomcat/temp 09-Jul-2022 15:01:19.219 INFO [main] org.apache.catalina.core.AprLifecycleListener.lifecycleEvent Loaded APR based Apache Tomcat Native library [1.2.21] using APR version [1.5.2]. 09-Jul-2022 15:01:19.219 INFO [main] org.apache.catalina.core.AprLifecycleListener.lifecycleEvent APR capabilities: IPv6 [true], sendfile [true], accept filters [false], random [true]. 09-Jul-2022 15:01:19.219 INFO [main] org.apache.catalina.core.AprLifecycleListener.lifecycleEvent APR/OpenSSL configuration: useAprConnector [false], useOpenSSL [true] 09-Jul-2022 15:01:19.222 INFO [main] org.apache.catalina.core.AprLifecycleListener.initializeSSL OpenSSL successfully initialized [OpenSSL 1.1.0j 20 Nov 2018] 09-Jul-2022 15:01:20.520 INFO [main] org.apache.coyote.AbstractProtocol.init Initializing ProtocolHandler ["http-nio-8080"] 09-Jul-2022 15:01:20.623 INFO [main] org.apache.tomcat.util.net.NioSelectorPool.getSharedSelector Using a shared selector for servlet write/read 09-Jul-2022 15:01:20.823 INFO [main] org.apache.coyote.AbstractProtocol.init Initializing ProtocolHandler ["ajp-nio-8009"] 09-Jul-2022 15:01:20.919 INFO [main] org.apache.tomcat.util.net.NioSelectorPool.getSharedSelector Using a shared selector for servlet write/read 09-Jul-2022 15:01:20.920 INFO [main] org.apache.catalina.startup.Catalina.load Initialization processed in 7199 ms 09-Jul-2022 15:01:21.225 INFO [main] org.apache.catalina.core.StandardService.startInternal Starting service [Catalina] 09-Jul-2022 15:01:21.225 INFO [main] org.apache.catalina.core.StandardEngine.startInternal Starting Servlet Engine: Apache Tomcat/8.5.38 09-Jul-2022 15:01:21.422 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployDirectory Deploying web application directory [/usr/local/tomcat/webapps/ROOT] 09-Jul-2022 15:01:27.318 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployDirectory Deployment of web application directory [/usr/local/tomcat/webapps/ROOT] has finished in [5,896] ms 09-Jul-2022 15:01:27.319 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployDirectory Deploying web application directory [/usr/local/tomcat/webapps/docs] 09-Jul-2022 15:01:27.721 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployDirectory Deployment of web application directory [/usr/local/tomcat/webapps/docs] has finished in [402] ms 09-Jul-2022 15:01:27.724 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployDirectory Deploying web application directory [/usr/local/tomcat/webapps/examples] 09-Jul-2022 15:01:31.823 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployDirectory Deployment of web application directory [/usr/local/tomcat/webapps/examples] has finished in [4,099] ms 09-Jul-2022 15:01:31.823 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployDirectory Deploying web application directory [/usr/local/tomcat/webapps/host-manager] 09-Jul-2022 15:01:32.121 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployDirectory Deployment of web application directory [/usr/local/tomcat/webapps/host-manager] has finished in [297] ms 09-Jul-2022 15:01:32.121 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployDirectory Deploying web application directory [/usr/local/tomcat/webapps/manager] 09-Jul-2022 15:01:32.520 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployDirectory Deployment of web application directory [/usr/local/tomcat/webapps/manager] has finished in [399] ms 09-Jul-2022 15:01:32.621 INFO [main] org.apache.coyote.AbstractProtocol.start Starting ProtocolHandler ["http-nio-8080"] 09-Jul-2022 15:01:32.918 INFO [main] org.apache.coyote.AbstractProtocol.start Starting ProtocolHandler ["ajp-nio-8009"] 09-Jul-2022 15:01:33.022 INFO [main] org.apache.catalina.startup.Catalina.start Server startup in 12102 ms [root@yefeng ~]# docker inspect tomcat -f '{{json .State}}' | jq # 显示容器状态,jq用来格式化json输出 { "Status": "exited", #容器已经处于 exited 状态 "Running": false, "Paused": false, "Restarting": false, "OOMKilled": true, #OOMKilled 是 true "Dead": false, "Pid": 0, "ExitCode": 137, #ExitCode 是 137 "Error": "", "StartedAt": "2022-07-09T15:01:11.944397977Z", "FinishedAt": "2022-07-09T15:05:18.109777032Z" } [root@yefeng ~]# docker inspect tomcat |grep "State" -A12 #上一个命令效果类似这个嘛。。。 "State": { "Status": "exited", "Running": false, "Paused": false, "Restarting": false, "OOMKilled": true, "Dead": false, "Pid": 0, "ExitCode": 137, "Error": "", "StartedAt": "2022-07-09T15:01:11.944397977Z", "FinishedAt": "2022-07-09T15:05:18.109777032Z" }, ***OOM 表示内存不足时,某些应用会被系统杀死; 我们的应用分配了 256 MB 的内存,而容器启动时,明明通过 -m 选项,设置了 512 MB 的内存,按说应该是足够的。 当 OOM 发生时,系统会把相关的 OOM 信息,记录到日志中。所以,接下来,我们可以在终端中执行 dmesg 命令,查看系统日志,并定位 OOM 相关的日志: [root@yefeng ~]# dmesg [80608.709252] java invoked oom-killer: gfp_mask=0xcc0(GFP_KERNEL), order=0, oom_score_adj=0 [80608.709279] CPU: 0 PID: 29118 Comm: java Tainted: G W E 5.18.3-1.el7.elrepo.x86_64 #1 [80608.709295] Hardware name: VMware, Inc. VMware Virtual Platform/440BX Desktop Reference Platform, BIOS 6.00 11/12/2020 [80608.709310] Call Trace: [80608.709325] <TASK> [80608.709354] dump_stack_lvl+0x49/0x5f [80608.725685] dump_stack+0x10/0x12 [80608.725687] dump_header+0x4f/0x200 [80608.725912] oom_kill_process.cold+0xb/0x10 [80608.725965] out_of_memory+0x1cf/0x540 [80608.726084] mem_cgroup_out_of_memory+0xe4/0x100 [80608.726108] try_charge_memcg+0x6a1/0x730 [80608.726110] ? __alloc_pages+0x17b/0x330 [80608.726148] charge_memcg+0x8b/0x100 [80608.726150] __mem_cgroup_charge+0x2d/0x80 [80608.726153] do_anonymous_page+0x108/0x390 [80608.726174] __handle_mm_fault+0x824/0x880 [80608.726177] handle_mm_fault+0xdb/0x2c0 [80608.726178] do_user_addr_fault+0x1be/0x650 [80608.726252] exc_page_fault+0x6c/0x150 [80608.726275] ? asm_exc_page_fault+0x8/0x30 [80608.726533] asm_exc_page_fault+0x1e/0x30 [80608.726536] RIP: 0033:0x7fc93e31620d [80608.726575] Code: 01 00 00 48 83 fa 40 77 77 c5 fe 7f 44 17 e0 c5 fe 7f 07 c5 f8 77 c3 66 0f 1f 44 00 00 c5 f8 77 48 89 d1 40 0f b6 c6 48 89 fa <f3> aa 48 89 d0 c3 0f 1f 00 66 2e 0f 1f 84 00 00 00 00 00 48 39 d1 [80608.726595] RSP: 002b:00007fc8ef1509e8 EFLAGS: 00010206 [80608.726615] RAX: 0000000000000000 RBX: 00007fc9381a8800 RCX: 0000000008aa7090 [80608.726616] RDX: 0000000755a28090 RSI: 0000000000000000 RDI: 000000075cf81000 [80608.726617] RBP: 00007fc8ef150a60 R08: 0000000002000002 R09: 00007fc93e1c68a1 [80608.726636] R10: 00007fc938018b90 R11: 0000000000000206 R12: 00000007c0000768 [80608.726637] R13: 00007fc9381a8800 R14: 00000007c0000768 R15: 0000000010000000 [80608.726640] </TASK> [80608.726738] memory: usage 524284kB, limit 524288kB, failcnt 29761 [80608.726740] memory+swap: usage 1048576kB, limit 1048576kB, failcnt 32 [80608.726741] kmem: usage 3900kB, limit 9007199254740988kB, failcnt 0 [80608.726742] Memory cgroup stats for /system.slice/docker-440bcf0b5979c56858162e816a779c3dc71647f104674d2ae51cee422e239a3a.scope: [80608.808074] anon 532013056 file 16384 kernel 3952640 kernel_stack 720896 pagetables 2510848 percpu 4680 sock 0 vmalloc 12288 shmem 0 file_mapped 8192 file_dirty 8192 file_writeback 0 swapcached 568717312 anon_thp 0 file_thp 0 shmem_thp 0 inactive_anon 530817024 active_anon 2039808 inactive_file 16384 active_file 0 unevictable 0 slab_reclaimable 168760 slab_unreclaimable 500840 slab 669600 workingset_refault_anon 4922 workingset_refault_file 6 workingset_activate_anon 0 workingset_activate_file 6 workingset_restore_anon 0 workingset_restore_file 0 workingset_nodereclaim 0 pgfault 160831 pgmajfault 3653 pgrefill 14 pgscan 449216 pgsteal 136014 pgactivate 505 pgdeactivate 14 pglazyfree 0 pglazyfreed 0 thp_fault_alloc 225 thp_collapse_alloc 0 [80608.808094] Tasks state (memory values in pages): [80608.808094] [ pid ] uid tgid total_vm rss pgtables_bytes swapents oom_score_adj name [80608.808102] [ 28962] 0 28962 1282795 134081 2523136 131569 0 java [80608.808120] oom-kill:constraint=CONSTRAINT_MEMCG,nodemask=(null),cpuset=docker-440bcf0b5979c56858162e816a779c3dc71647f104674d2ae51cee422e239a3a.scope,mems_allowed=0,oom_memcg=/system.slice/docker-440bcf0b5979c56858162e816a779c3dc71647f104674d2ae51cee422e239a3a.scope,task_memcg=/system.slice/docker-440bcf0b5979c56858162e816a779c3dc71647f104674d2ae51cee422e239a3a.scope,task=java,pid=28962,uid=0 [80608.808166] Memory cgroup out of memory: Killed process 28962 (java) total-vm:5131180kB, anon-rss:516256kB, file-rss:20068kB, shmem-rss:0kB, UID:0 pgtables:2464kB oom_score_adj:0 [80609.409454] docker0: port 1(veth1a194a0) entered disabled state [80609.410704] vethe2b94bf: renamed from eth0 [80609.434731] docker0: port 1(veth1a194a0) entered disabled state [80609.436548] device veth1a194a0 left promiscuous mode [80609.436555] docker0: port 1(veth1a194a0) entered disabled state [root@yefeng ~]# $ dmesg [193038.106393] java invoked oom-killer: gfp_mask=0x14000c0(GFP_KERNEL), nodemask=(null), order=0, oom_score_adj=0 [193038.106396] java cpuset=0f2b3fcdd2578165ea77266cdc7b1ad43e75877b0ac1889ecda30a78cb78bd53 mems_allowed=0 [193038.106402] CPU: 0 PID: 27424 Comm: java Tainted: G OE 4.15.0-1037 #39-Ubuntu [193038.106404] Hardware name: Microsoft Corporation Virtual Machine/Virtual Machine, BIOS 090007 06/02/2017 [193038.106405] Call Trace: [193038.106414] dump_stack+0x63/0x89 [193038.106419] dump_header+0x71/0x285 [193038.106422] oom_kill_process+0x220/0x440 [193038.106424] out_of_memory+0x2d1/0x4f0 [193038.106429] mem_cgroup_out_of_memory+0x4b/0x80 [193038.106432] mem_cgroup_oom_synchronize+0x2e8/0x320 [193038.106435] ? mem_cgroup_css_online+0x40/0x40 [193038.106437] pagefault_out_of_memory+0x36/0x7b [193038.106443] mm_fault_error+0x90/0x180 [193038.106445] __do_page_fault+0x4a5/0x4d0 [193038.106448] do_page_fault+0x2e/0xe0 [193038.106454] ? page_fault+0x2f/0x50 [193038.106456] page_fault+0x45/0x50 [193038.106459] RIP: 0033:0x7fa053e5a20d [193038.106460] RSP: 002b:00007fa0060159e8 EFLAGS: 00010206 [193038.106462] RAX: 0000000000000000 RBX: 00007fa04c4b3000 RCX: 0000000009187440 [193038.106463] RDX: 00000000943aa440 RSI: 0000000000000000 RDI: 000000009b223000 [193038.106464] RBP: 00007fa006015a60 R08: 0000000002000002 R09: 00007fa053d0a8a1 [193038.106465] R10: 00007fa04c018b80 R11: 0000000000000206 R12: 0000000100000768 [193038.106466] R13: 00007fa04c4b3000 R14: 0000000100000768 R15: 0000000010000000 [193038.106468] Task in /docker/0f2b3fcdd2578165ea77266cdc7b1ad43e75877b0ac1889ecda30a78cb78bd53 killed as a result of limit of /docker/0f2b3fcdd2578165ea77266cdc7b1ad43e75877b0ac1889ecda30a78cb78bd53 [193038.106478] memory: usage 524288kB, limit 524288kB, failcnt 77 [193038.106480] memory+swap: usage 0kB, limit 9007199254740988kB, failcnt 0 [193038.106481] kmem: usage 3708kB, limit 9007199254740988kB, failcnt 0 [193038.106481] Memory cgroup stats for /docker/0f2b3fcdd2578165ea77266cdc7b1ad43e75877b0ac1889ecda30a78cb78bd53: cache:0KB rss:520580KB rss_huge:450560KB shmem:0KB mapped_file:0KB dirty:0KB writeback:0KB inactive_anon:0KB active_anon:520580KB inactive_file:0KB active_file:0KB unevictable:0KB [193038.106494] [ pid ] uid tgid total_vm rss pgtables_bytes swapents oom_score_adj name [193038.106571] [27281] 0 27281 1153302 134371 1466368 0 0 java [193038.106574] Memory cgroup out of memory: Kill process 27281 (java) score 1027 or sacrifice child [193038.148334] Killed process 27281 (java) total-vm:4613208kB, anon-rss:517316kB, file-rss:20168kB, shmem-rss:0kB [193039.607503] oom_reaper: reaped process 27281 (java), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB 第一,被杀死的是一个 java 进程。从内核调用栈上的 mem_cgroup_out_of_memory 可以看出,它是因为超过 cgroup 的内存限制,而被 OOM 杀死的。 第二,java 进程是在容器内运行的,而容器内存的使用量和限制都是 512M(524288kB)。目前使用量已经达到了限制,所以会导致 OOM。 第三,被杀死的进程,PID 为 27281,虚拟内存为 4.3G(total-vm:4613208kB),匿名内存为 505M(anon-rss:517316kB),页内存为 19M(20168kB)。换句话说,匿名内存是主要的内存占用。而且,匿名内存加上页内存,总共是 524M,已经超过了 512M 的限制。 综合这几点,可以看出,Tomcat 容器的内存主要用在了匿名内存中,而匿名内存,其实就是主动申请分配的堆内存。 问题1根因:JVM 根据系统的内存总量,来自动管理堆内存,不明确配置的话,堆内存的默认限制是物理内存的四分之一。不过,前面我们已经限制了容器内存为 512 M,java 的堆内存到底是多少呢? 重新启动 tomcat 容器,并调用 java 命令行来查看堆内存大小: $ docker rm -f tomcat # 重新启动容器 $ docker run --name tomcat --cpus 0.1 -m 512M -p 8080:8080 -itd feisky/tomcat:8 $ docker exec tomcat java -XX:+PrintFlagsFinal -version | grep HeapSize # 查看堆内存,注意单位是字节 uintx ErgoHeapSizeLimit = 0 {product} uintx HeapSizePerGCThread = 87241520 {product} uintx InitialHeapSize := 132120576 {product} uintx LargePageHeapSizeThreshold = 134217728 {product} uintx MaxHeapSize := 2092957696 可以看到,初始堆内存的大小(InitialHeapSize)是 126MB,而最大堆内存则是 1.95GB,这可比容器限制的 512 MB 大多了。 之所以会这么大,其实是因为,容器内部看不到 Docker 为它设置的内存限制。 虽然在启动容器时,我们通过 -m 512M 选项,给容器设置了 512M 的内存限制。但实际上,从容器内部看到的限制,却并不是 512M。 $ docker exec tomcat free -m total used free shared buff/cache available Mem: 7977 521 1941 0 5514 7148 Swap: 0 0 0 [root@yefeng ~]# docker run --name tomcat --cpus 0.1 -m 512M -p 8080:8080 -itd feisky/tomcat:8 WARNING: IPv4 forwarding is disabled. Networking will not work. d09d189952a89e16d6f2190444bc2915f1a1a0399d9ef94512b62fe188605e3c [root@yefeng ~]# docker exec -it d09d189952a89e16d6f2190444bc2915f1a1a0399d9ef94512b62fe188605e3c free -h total used free shared buff/cache available Mem: 9.7G 996M 7.4G 36M 1.3G 8.4G Swap: 2.0G 604K 2.0G 容器内部看到的内存,仍是主机内存 执行下面的命令,通过环境变量 JAVA_OPTS=’-Xmx512m -Xms512m’ ,把 JVM 的初始内存和最大内存都设为 512MB: # 删除问题容器 $ docker rm -f tomcat # 运行新的容器 $ docker run --name tomcat --cpus 0.1 -m 512M -e JAVA_OPTS='-Xmx512m -Xms512m' -p 8080:8080 -itd feisky/tomcat:8 [root@yefeng ~]# for ((i=0;i<30;i++)); do curl localhost:8080; sleep 1; done Hello, wolrd! Hello, wolrd! Hello, wolrd! Hello, wolrd! Hello, wolrd! Hello, wolrd! #再次测试,除了第一次的响应特别慢,其他都正常了 Hello, wolrd! Hello, wolrd! Hello, wolrd! Hello, wolrd! Hello, wolrd! Hello, wolrd! Hello, wolrd! Hello, wolrd! ---------------------------------------------------------------------------------------------------- 处理问题2:启动慢 [root@yefeng ~]# docker logs tomcat |tail 09-Jul-2022 15:36:07.118 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployDirectory Deployment of web application directory [/usr/local/tomcat/webapps/docs] has finished in [597] ms 09-Jul-2022 15:36:07.119 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployDirectory Deploying web application directory [/usr/local/tomcat/webapps/examples] 09-Jul-2022 15:36:10.619 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployDirectory Deployment of web application directory [/usr/local/tomcat/webapps/examples] has finished in [3,499] ms 09-Jul-2022 15:36:10.619 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployDirectory Deploying web application directory [/usr/local/tomcat/webapps/host-manager] 09-Jul-2022 15:36:10.923 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployDirectory Deployment of web application directory [/usr/local/tomcat/webapps/host-manager] has finished in [303] ms 09-Jul-2022 15:36:10.923 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployDirectory Deploying web application directory [/usr/local/tomcat/webapps/manager] 09-Jul-2022 15:36:11.218 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployDirectory Deployment of web application directory [/usr/local/tomcat/webapps/manager] has finished in [295] ms 09-Jul-2022 15:36:11.319 INFO [main] org.apache.coyote.AbstractProtocol.start Starting ProtocolHandler ["http-nio-8080"] 09-Jul-2022 15:36:11.619 INFO [main] org.apache.coyote.AbstractProtocol.start Starting ProtocolHandler ["ajp-nio-8009"] 09-Jul-2022 15:36:11.722 INFO [main] org.apache.catalina.startup.Catalina.start Server startup in 11003 ms #查看日志,发现服务初始化时间需要11秒。。。 通过不断地删除容器,启动新容器,来观察容器启动慢的原因 $ docker rm -f tomcat # 删除旧容器 $ docker run --name tomcat --cpus 0.1 -m 512M -e JAVA_OPTS='-Xmx512m -Xms512m' -p 8080:8080 -itd feisky/tomcat:8 # 运行新容器 $ top #使用top进行观察 top - 12:57:18 up 2 days, 5:50, 2 users, load average: 0.00, 0.02, 0.00 Tasks: 131 total, 1 running, 74 sleeping, 0 stopped, 0 zombie %Cpu0 : 3.0 us, 0.3 sy, 0.0 ni, 96.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st #整理的指标看起来都不高 %Cpu1 : 5.7 us, 0.3 sy, 0.0 ni, 94.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 8169304 total, 2465984 free, 500812 used, 5202508 buff/cache KiB Swap: 0 total, 0 free, 0 used. 7353652 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 29457 root 20 0 2791736 73704 19164 S 10.0 0.9 0:01.61 java #但是实际上10%的使用率已经跑满了,因为该容器对资源进行了限制"--cpus 0.1";但是这里选择了无视 27349 root 20 0 1121372 96760 39340 S 0.3 1.2 4:20.82 dockerd 27376 root 20 0 1031760 43768 21680 S 0.3 0.5 2:44.47 docker-containe 29430 root 20 0 7376 3604 3128 S 0.3 0.0 0:00.01 docker-containe 1 root 20 0 78132 9332 6744 S 0.0 0.1 0:16.12 systemd 这里只是觉得java占用cpu偏高,觉得可疑 删除并启动新容器,并使用pidstat进行观察 $ docker rm -f tomcat # 删除旧容器 $ docker run --name tomcat --cpus 0.1 -m 512M -e JAVA_OPTS='-Xmx512m -Xms512m' -p 8080:8080 -itd feisky/tomcat:8 # 运行新容器 $ PID=$(docker inspect tomcat -f '{{.State.Pid}}') # 查询新容器中进程的Pid $ pidstat -t -p $PID 1 # 执行 pidstat;-t表示显示线程,-p指定进程号 12:59:28 UID TGID TID %usr %system %guest %wait %CPU CPU Command 12:59:29 0 29850 - 10.00 0.00 0.00 0.00 10.00 0 java 12:59:29 0 - 29850 0.00 0.00 0.00 0.00 0.00 0 |__java 12:59:29 0 - 29897 5.00 1.00 0.00 86.00 6.00 1 |__java ... 12:59:29 0 - 29905 3.00 0.00 0.00 97.00 3.00 0 |__java 12:59:29 0 - 29906 2.00 0.00 0.00 49.00 2.00 1 |__java 12:59:29 0 - 29908 0.00 0.00 0.00 45.00 0.00 0 |__java 虽然 CPU 使用率(%CPU)很低,但等待运行的使用率(%wait)却非常高,最高甚至已经达到了 97%。这说明,这些线程大部分时间都在等待调度,而不是真正的运行。 为什么 CPU 使用率这么低,线程的大部分时间还要等待 CPU 呢?由于这个现象因 Docker 而起,自然的,你应该想到,这可能是因为 Docker 为容器设置了限制。 再回顾一下,案例开始时容器的启动命令。我们用 --cpus 0.1 ,为容器设置了 0.1 个 CPU 的限制,也就是 10% 的 CPU。这里也就可以解释,为什么 java 进程只有 10% 的 CPU 使用率,也会大部分时间都在等待了。 # 删除旧容器 $ docker rm -f tomcat # 运行新容器 #增大了CPU资源!!! $ docker run --name tomcat --cpus 1 -m 512M -e JAVA_OPTS='-Xmx512m -Xms512m' -p 8080:8080 -itd feisky/tomcat:8 # 查看容器日志 $ docker logs -f tomcat ... 18-Feb-2019 12:54:02.139 INFO [main] org.apache.catalina.startup.Catalina.start Server startup in 2001 ms #启动时间由22秒缩短为2秒 如果你在 Docker 容器中运行 Java 应用,一定要确保,在设置容器资源限制的同时,配置好 JVM 的资源选项(比如堆内存等)。当然,如果你可以升级 Java 版本,那么升级到 Java 10 ,就可以自动解决类似问题了。 容器化后的性能分析,跟前面内容稍微有些区别,比如下面这几点。 容器本身通过 cgroups 进行资源隔离,所以,在分析时要考虑 cgroups 对应用程序的影响。 容器的文件系统、网络协议栈等跟主机隔离。虽然在容器外面,我们也可以分析容器的行为,不过有时候,进入容器的命名空间内部,可能更为方便。 容器的运行可能还会依赖于其他组件,比如各种网络插件(比如 CNI)、存储插件(比如 CSI)、设备插件(比如 GPU)等,让容器的性能分析更加复杂。如果你需要分析容器性能,别忘了考虑它们对性能的影响。
47 | 案例篇:服务器总是时不时丢包,我该怎么办?(上)
48 | 案例篇:服务器总是时不时丢包,我该怎么办?(下)
容器化后,应用程序会通过命名空间进行隔离。所以,你在分析时,不要忘了结合命名空间、cgroups、iptables 等来综合分析。比如: cgroups 会影响容器应用的运行; iptables 中的 NAT,会影响容器的网络性能; 叠加文件系统,会影响应用的 I/O 性能等。 --------------------------------------------------------- 容器丢包案例:1.链路层tc规则随机丢包;2.iptable3规则随机丢包;3.mtu问题导致http GET请求被丢包 ============================================================================================================================== 本案例问题汇总: 1.tc命令配置随机丢弃,导致了hping3测试丢包 2.iptables配置了随机的drop规则,导致了hping3测试丢包 3.mtu 100,导致了tcp3次握手正常,但是业务数据包丢包 排查过程小结: hping3 -c 10 -S -p 80 192.168.0.30 测试,发现丢包现象 链路层 1.netstat -i/ifconfig/ip a #查看数据(RX: bytes packets errors dropped overrun) 2.tc -s qdisc show dev eth0 #查看tc规则是否导致丢包 网络层和传输层 1.netstat -s #查看ip、tcp、udp等的传输数据 排查 iptables 和内核的连接跟踪机制 1.sysctl net.netfilter.nf_conntrack_max sysctl net.netfilter.nf_conntrack_count #连接跟踪数不能超过最大连接跟踪数 2.iptables -t filter -nvL #查看各条规则的统计信息,此处重点关注drop规则的匹配数量 ----------------------------------------- 修复tc规则和iptables导致的丢包问题后,hping3测试无问题,但是curl访问却超时 1.netstat -i/ifconfig/ip a #查看数据(RX: bytes packets errors dropped overrun) 发现dropped数据在增长 最后发现网卡mtu配置为100 ----------------------------------------------------------------------------------------------------------- 启动容器,并观察到容器已经up $ docker run --name nginx --hostname nginx --privileged -p 80:80 -itd feisky/nginx:drop $ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES dae0202cc27e feisky/nginx:drop "/start.sh" 4 minutes ago Up 4 minutes 0.0.0.0:80->80/tcp nginx 执行hping3 命令,进一步验证 Nginx 是否可以正常访问了 $ hping3 -c 10 -S -p 80 192.168.0.30 # -c表示发送10个请求,-S表示使用TCP SYN,-p指定端口为80 HPING 192.168.0.30 (eth0 192.168.0.30): S set, 40 headers + 0 data bytes len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=3 win=5120 rtt=7.5 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=4 win=5120 rtt=7.4 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=5 win=5120 rtt=3.3 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=7 win=5120 rtt=3.0 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=6 win=5120 rtt=3027.2 ms --- 192.168.0.30 hping statistic --- 10 packets transmitted, 5 packets received, 50% packet loss #10 个请求包,却只收到了 5 个回复,50% 的包都丢了。 round-trip min/avg/max = 3.0/609.7/3027.2 ms #部分延迟很高 发现2个问题: 1.50%丢包 2.部分延迟高 ---------------------------------------------------------------------------- 全程都有丢包的可能。比如我们从下往上看: 在两台 VM 连接之间,可能会发生传输失败的错误,比如网络拥塞、线路错误等; 在网卡收包后,环形缓冲区可能会因为溢出而丢包; 在链路层,可能会因为网络帧校验失败、QoS 等而丢包; 在 IP 层,可能会因为路由失败、组包大小超过 MTU 等而丢包; 在传输层,可能会因为端口未监听、资源占用超过内核限制等而丢包; 在套接字层,可能会因为套接字缓冲区溢出而丢包; 在应用层,可能会因为应用程序异常而丢包; 此外,如果配置了 iptables 规则,这些网络包也可能因为 iptables 过滤规则而丢包。 在client端、server端、server端veth pair设备抓包,结果显示一致,说明了中间链路、宿主机的因素可以排除 ---------------------------------------------------------------------------- 查看容器的链路层 root@nginx:/# netstat -i Kernel Interface table Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg eth0 100 31 0 0 0 8 0 0 0 BMRU lo 65536 0 0 0 0 0 0 0 0 LRU RX-OK 总包数 RX-ERR 总错误数 RX-DRP 进入 Ring Buffer 后因其他原因(如内存不足)导致的丢包数 RX-OVR Ring Buffer 溢出导致的丢包数 其实这几个参数,ifconfig,ip -s a 都可以看到 ethtool -S可以看到更详细的统计信息 但是veth 驱动并没有实现网络统计的功能,所以使用 ethtool -S 命令,无法得到veth pair网卡收发数据的汇总信息 查看 eth0 上是否配置了 tc 规则,并查看有没有丢包 root@nginx:/# tc -s qdisc show dev eth0 qdisc netem 800d: root refcnt 2 limit 1000 loss 30% Sent 432 bytes 8 pkt (dropped 4, overlimits 0 requeues 0) ###tc规则丢弃了4个包 backlog 0b 0p requeues 0 从 tc 的输出中可以看到, eth0 上面配置了一个网络模拟排队规则(qdisc netem),并且配置了丢包率为 30%(loss 30%)。再看后面的统计信息,发送了 8 个包,但是丢了 4 个。 解决方法也就很简单了,直接删掉 netem 模块就可以了。 root@nginx:/# tc qdisc del dev eth0 root netem loss 30% 清除tc规则后,重新测试 $ hping3 -c 10 -S -p 80 192.168.0.30 HPING 192.168.0.30 (eth0 192.168.0.30): S set, 40 headers + 0 data bytes len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=0 win=5120 rtt=7.9 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=2 win=5120 rtt=1003.8 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=5 win=5120 rtt=7.6 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=6 win=5120 rtt=7.4 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=9 win=5120 rtt=3.0 ms --- 192.168.0.30 hping statistic --- 10 packets transmitted, 5 packets received, 50% packet loss round-trip min/avg/max = 3.0/205.9/1003.8 ms 测试结果显示仍然存在丢包,但是高延迟似乎有好转,由3s下降为1s ---------------------------------------------------------------------------- 网络层和传输层 执行netstat -s 命令,就可以看到协议的收发汇总,以及错误信息: netstat 汇总了 IP、ICMP、TCP、UDP 等各种协议的收发统计信息。 root@nginx:/# netstat -s Ip: Forwarding: 1 //开启转发 31 total packets received //总收包数 0 forwarded //转发包数 0 incoming packets discarded //接收丢包数 25 incoming packets delivered //接收的数据包数 15 requests sent out //发出的数据包数 Icmp: 0 ICMP messages received //收到的ICMP包数 0 input ICMP message failed //收到ICMP失败数 ICMP input histogram: 0 ICMP messages sent //ICMP发送数 0 ICMP messages failed //ICMP失败数 ICMP output histogram: Tcp: 0 active connection openings //主动连接数 0 passive connection openings //被动连接数 11 failed connection attempts //失败连接尝试数 #11 次连接失败重试 0 connection resets received //接收的连接重置数 0 connections established //建立连接数 25 segments received //已接收报文数 21 segments sent out //已发送报文数 4 segments retransmitted //重传报文数 #4 次重传 0 bad segments received //错误报文数 0 resets sent //发出的连接重置数 Udp: 0 packets received ... TcpExt: 11 resets received for embryonic SYN_RECV sockets //半连接重置数 #11 次半连接重置 0 packet headers predicted TCPTimeouts: 7 //超时数 #7 次超时 TCPSynRetrans: 4 //SYN重传数 #4 次 SYN 重传 ... 这个结果告诉我们,TCP 协议有多次超时和失败重试,并且主要错误是半连接重置。换句话说,主要的失败,都是三次握手失败。 ------------------------------------------------------------------------------------------------------------- 48 | 案例篇:服务器总是时不时丢包,我该怎么办?(下) #排查 iptables 和内核的连接跟踪机制 除了网络层和传输层的各种协议,iptables 和内核的连接跟踪机制也可能会导致丢包。 我已经在 如何优化 NAT 性能 文章中,给你讲过连接跟踪的优化思路。 要确认是不是连接跟踪导致的问题,其实只需要对比当前的连接跟踪数和最大连接跟踪数即可。 连接跟踪在 Linux 内核中是全局的(不属于网络命名空间),我们需要退出容器终端,回到主机中来查看。 # 主机终端中查询内核配置 $ sysctl net.netfilter.nf_conntrack_max net.netfilter.nf_conntrack_max = 262144 $ sysctl net.netfilter.nf_conntrack_count net.netfilter.nf_conntrack_count = 182 #连接跟踪数只有 182,而最大连接跟踪数则是 262144。显然,这里的丢包,不可能是连接跟踪导致的。 iptables 更简单的方法,就是直接查询 DROP 和 REJECT 等规则的统计信息,看看是否为 0。如果统计值不是 0 ,再把相关的规则拎出来进行分析。 iptables -nvL 命令,查看各条规则的统计信息。 root@nginx:/# iptables -t filter -nvL # 在容器中执行 Chain INPUT (policy ACCEPT 25 packets, 1000 bytes) pkts bytes target prot opt in out source destination 6 240 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 statistic mode random probability 0.29999999981 Chain FORWARD (policy ACCEPT 0 packets, 0 bytes) pkts bytes target prot opt in out source destination Chain OUTPUT (policy ACCEPT 15 packets, 660 bytes) pkts bytes target prot opt in out source destination 6 264 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 statistic mode random probability 0.29999999981 可以看到,两条 DROP 规则的统计数值不是 0,它们分别在 INPUT 和 OUTPUT 链中。这两条规则实际上是一样的,指的是使用 statistic 模块,进行随机 30% 的丢包。 再观察一下它们的匹配规则。0.0.0.0/0 表示匹配所有的源 IP 和目的 IP,也就是会对所有包都进行随机 30% 的丢包。 修复:删除这两条 DROP 规则 root@nginx:/# iptables -t filter -D INPUT -m statistic --mode random --probability 0.30 -j DROP root@nginx:/# iptables -t filter -D OUTPUT -m statistic --mode random --probability 0.30 -j DROP $ hping3 -c 10 -S -p 80 192.168.0.30 #修复后测试,hping3结果已经ok HPING 192.168.0.30 (eth0 192.168.0.30): S set, 40 headers + 0 data bytes len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=0 win=5120 rtt=11.9 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=1 win=5120 rtt=7.8 ms ... len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=9 win=5120 rtt=15.0 ms --- 192.168.0.30 hping statistic --- 10 packets transmitted, 10 packets received, 0% packet loss round-trip min/avg/max = 3.3/7.9/15.0 ms ------------------------------------------------------------------------------------------------------------- 接下来用curl命令验证业务情况,结果发现超时 $ curl --max-time 3 http://192.168.0.30 curl: (28) Operation timed out after 3000 milliseconds with 0 bytes received 在服务端的容器veth pair设备上抓包,抓包现象比较明显:3次握手没问题,但是发送http GET请求,服务端一直无响应(wireshark查看更清晰) [root@yefeng ~]# tcpdump -nnvvi veth524ff9a host 192.168.1.88 and tcp port 80 tcpdump: listening on veth524ff9a, link-type EN10MB (Ethernet), capture size 262144 bytes 21:42:29.052572 IP (tos 0x0, ttl 63, id 37145, offset 0, flags [DF], proto TCP (6), length 60) 192.168.1.88.60802 > 172.17.0.2.80: Flags [S], cksum 0x1bba (correct), seq 1719104784, win 64240, options [mss 1460,sackOK,TS val 2898873629 ecr 0,nop,wscale 7], length 0 21:42:29.052779 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto TCP (6), length 60) 172.17.0.2.80 > 192.168.1.88.60802: Flags [S.], cksum 0x6e42 (incorrect -> 0x30b5), seq 2397574152, ack 1719104785, win 65392, options [mss 256,sackOK,TS val 2607000787 ecr 2898873629,nop,wscale 7], length 0 21:42:29.053012 IP (tos 0x0, ttl 63, id 37146, offset 0, flags [DF], proto TCP (6), length 52) 192.168.1.88.60802 > 172.17.0.2.80: Flags [.], cksum 0x5847 (correct), seq 1, ack 1, win 502, options [nop,nop,TS val 2898873630 ecr 2607000787], length 0 21:42:29.053014 IP (tos 0x0, ttl 63, id 37147, offset 0, flags [DF], proto TCP (6), length 129) 192.168.1.88.60802 > 172.17.0.2.80: Flags [P.], cksum 0xefad (correct), seq 1:78, ack 1, win 502, options [nop,nop,TS val 2898873630 ecr 2607000787], length 77: HTTP, length: 77 GET / HTTP/1.1 User-Agent: curl/7.29.0 Host: 192.168.1.150 Accept: */* 21:42:29.260432 IP (tos 0x0, ttl 63, id 37148, offset 0, flags [DF], proto TCP (6), length 129) 192.168.1.88.60802 > 172.17.0.2.80: Flags [P.], cksum 0xeede (correct), seq 1:78, ack 1, win 502, options [nop,nop,TS val 2898873837 ecr 2607000787], length 77: HTTP, length: 77 GET / HTTP/1.1 User-Agent: curl/7.29.0 Host: 192.168.1.150 Accept: */* 21:42:29.468972 IP (tos 0x0, ttl 63, id 37149, offset 0, flags [DF], proto TCP (6), length 129) 192.168.1.88.60802 > 172.17.0.2.80: Flags [P.], cksum 0xee0e (correct), seq 1:78, ack 1, win 502, options [nop,nop,TS val 2898874045 ecr 2607000787], length 77: HTTP, length: 77 GET / HTTP/1.1 User-Agent: curl/7.29.0 Host: 192.168.1.150 Accept: */* 21:42:29.876434 IP (tos 0x0, ttl 63, id 37150, offset 0, flags [DF], proto TCP (6), length 129) 192.168.1.88.60802 > 172.17.0.2.80: Flags [P.], cksum 0xec76 (correct), seq 1:78, ack 1, win 502, options [nop,nop,TS val 2898874453 ecr 2607000787], length 77: HTTP, length: 77 GET / HTTP/1.1 User-Agent: curl/7.29.0 Host: 192.168.1.150 Accept: */* 21:42:30.740512 IP (tos 0x0, ttl 63, id 37151, offset 0, flags [DF], proto TCP (6), length 129) 192.168.1.88.60802 > 172.17.0.2.80: Flags [P.], cksum 0xe916 (correct), seq 1:78, ack 1, win 502, options [nop,nop,TS val 2898875317 ecr 2607000787], length 77: HTTP, length: 77 GET / HTTP/1.1 User-Agent: curl/7.29.0 Host: 192.168.1.150 Accept: */* 21:42:32.054218 IP (tos 0x0, ttl 63, id 37152, offset 0, flags [DF], proto TCP (6), length 52) 192.168.1.88.60802 > 172.17.0.2.80: Flags [F.], cksum 0x4c40 (correct), seq 78, ack 1, win 502, options [nop,nop,TS val 2898876631 ecr 2607000787], length 0 21:42:32.054310 IP (tos 0x0, ttl 64, id 33311, offset 0, flags [DF], proto TCP (6), length 64) 172.17.0.2.80 > 192.168.1.88.60802: Flags [.], cksum 0x6e46 (incorrect -> 0x5ec0), seq 1, ack 1, win 511, options [nop,nop,TS val 2607003789 ecr 2898873630,nop,nop,sack 1 {78:79}], length 0 21:42:32.054507 IP (tos 0x0, ttl 63, id 37153, offset 0, flags [DF], proto TCP (6), length 129) 192.168.1.88.60802 > 172.17.0.2.80: Flags [P.], cksum 0xd83a (correct), seq 1:78, ack 1, win 502, options [nop,nop,TS val 2898876631 ecr 2607003789], length 77: HTTP, length: 77 GET / HTTP/1.1 User-Agent: curl/7.29.0 Host: 192.168.1.150 Accept: */* 21:42:32.261066 IP (tos 0x0, ttl 63, id 37154, offset 0, flags [DF], proto TCP (6), length 129) 192.168.1.88.60802 > 172.17.0.2.80: Flags [P.], cksum 0xd76b (correct), seq 1:78, ack 1, win 502, options [nop,nop,TS val 2898876838 ecr 2607003789], length 77: HTTP, length: 77 GET / HTTP/1.1 User-Agent: curl/7.29.0 Host: 192.168.1.150 Accept: */* 21:42:32.668406 IP (tos 0x0, ttl 63, id 37155, offset 0, flags [DF], proto TCP (6), length 129) 192.168.1.88.60802 > 172.17.0.2.80: Flags [P.], cksum 0xd5d4 (correct), seq 1:78, ack 1, win 502, options [nop,nop,TS val 2898877245 ecr 2607003789], length 77: HTTP, length: 77 GET / HTTP/1.1 User-Agent: curl/7.29.0 Host: 192.168.1.150 Accept: */* 21:42:33.492459 IP (tos 0x0, ttl 63, id 37156, offset 0, flags [DF], proto TCP (6), length 129) 192.168.1.88.60802 > 172.17.0.2.80: Flags [P.], cksum 0xd29c (correct), seq 1:78, ack 1, win 502, options [nop,nop,TS val 2898878069 ecr 2607003789], length 77: HTTP, length: 77 GET / HTTP/1.1 User-Agent: curl/7.29.0 Host: 192.168.1.150 Accept: */* 再次查看网卡的链路层数据,发现dorpped有增长 [root@yefeng ~]# docker exec -it nginx netstat -i Kernel Interface table Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg eth0 100 316 0 42 0 147 0 0 0 BMRU lo 65536 0 0 0 0 0 0 0 0 LRU [root@yefeng ~]# docker exec -it nginx ip -s a s eth0 28: eth0@if29: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 100 qdisc noqueue state UP group default qlen 1000 link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 172.17.0.2/16 scope global eth0 valid_lft forever preferred_lft forever RX: bytes packets errors dropped overrun mcast 18003 316 0 42 0 0 TX: bytes packets errors dropped carrier collsns 8422 147 0 0 0 0 [root@yefeng ~]# docker exec -it nginx ifconfig eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 100 inet 172.17.0.2 netmask 255.255.0.0 broadcast 0.0.0.0 ether 02:42:ac:11:00:02 txqueuelen 1000 (Ethernet) RX packets 316 bytes 18003 (17.5 KiB) RX errors 0 dropped 42 overruns 0 frame 0 TX packets 147 bytes 8422 (8.2 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 总结一下:奇怪的现象,hping3测试不丢包,curl测试却丢包了 根据抓包分析,也就是HTTP GET请求丢包了,而且稳定丢 然后神器的发现了eth0的mtu只有100... [root@yefeng ~]# docker exec -it nginx ifconfig eth0 mtu 1500 修复mtu后再次curl测试,问题彻底修复
49 | 案例篇:内核线程 CPU 利用率太高,我该怎么办?
内核线程概述;常见的内核线程 =================================================================================== 在排查网络问题时,我们还经常碰到的一个问题,就是内核线程的 CPU 使用率很高。 比如,在高并发的场景中,内核线程 ksoftirqd 的 CPU 使用率通常就会比较高。 要分析 ksoftirqd 这类 CPU 使用率比较高的内核线程,一般需要借助于其他性能工具,进行辅助分析。 以 ksoftirqd 为例,如果你怀疑是网络问题,就可以用 sar、tcpdump 等分析网络流量,进一步确认网络问题的根源。 本案例推荐使用perf+火焰图在综合分析 ---------------------------- 内核线程 Linux 在启动过程中,有三个特殊的进程,也就是 PID 号最小的三个进程。 0 号进程为 idle 进程,这也是系统创建的第一个进程,它在初始化 1 号和 2 号进程后,演变为空闲任务。当 CPU 上没有其他任务执行时,就会运行它。 1 号进程为 init 进程,通常是 systemd 进程,在用户态运行,用来管理其他用户态进程。 2 号进程为 kthreadd 进程,在内核态运行,用来管理内核线程。 ps 命令,来查找 kthreadd 的子进程 $ ps -f --ppid 2 -p 2 #方式1 UID PID PPID C STIME TTY TIME CMD root 2 0 0 12:02 ? 00:00:01 [kthreadd] root 9 2 0 12:02 ? 00:00:21 [ksoftirqd/0] root 10 2 0 12:02 ? 00:11:47 [rcu_sched] root 11 2 0 12:02 ? 00:00:18 [migration/0] ... root 11094 2 0 14:20 ? 00:00:00 [kworker/1:0-eve] root 11647 2 0 14:27 ? 00:00:00 [kworker/0:2-cgr] $ ps -ef | grep "\[.*\]" #方式2,因为内核线程的名称(CMD)都在中括号里 root 2 0 0 08:14 ? 00:00:00 [kthreadd] root 3 2 0 08:14 ? 00:00:00 [rcu_gp] root 4 2 0 08:14 ? 00:00:00 [rcu_par_gp] ... ------------------------------------------------------------------- 常见的内核线程: kswapd0:用于内存回收。在 Swap 变高 案例中,我曾介绍过它的工作原理。 kworker:用于执行内核工作队列,分为绑定 CPU (名称格式为 kworker/CPU86330)和未绑定 CPU(名称格式为 kworker/uPOOL86330)两类。 migration:在负载均衡过程中,把进程迁移到 CPU 上。每个 CPU 都有一个 migration 内核线程。 jbd2/sda1-8:jbd 是 Journaling Block Device 的缩写,用来为文件系统提供日志功能,以保证数据的完整性;名称中的 sda1-8,表示磁盘分区名称和设备号。每个使用了 ext4 文件系统的磁盘分区,都会有一个 jbd2 内核线程。 pdflush:用于将内存中的脏页(被修改过,但还未写入磁盘的文件页)写入磁盘(已经在 3.10 中合并入了 kworker 中)。
DOS攻击导致内核线程 CPU 利用率太高的案例:perf工具;FlameGraph(火焰图) ============================================================================================================================== 运行案例容器 $ docker run -itd --name=nginx -p 80:80 nginx # 运行Nginx服务并对外开放80端口 [root@yefeng ~]# curl http://192.168.1.150 #curl命令进行测试,返回正常结果 使用hping3命令发起攻击 [root@yefeng ~]# hping3 -S -p 80 -i u1 192.168.1.150 # -S参数表示设置TCP协议的SYN(同步序列号),-p表示目的端口为80 # -i u10表示每隔10微秒发送一个网络帧 # 注:如果你在实践过程中现象不明显,可以尝试把10调小,比如调成5甚至1 -------------------------------------------------------------------------------- 排查过程: 回到server端,你应该就会发现异常-----系统的响应明显变慢了 $ top top - 08:31:43 up 17 min, 1 user, load average: 0.00, 0.00, 0.02 Tasks: 128 total, 1 running, 69 sleeping, 0 stopped, 0 zombie %Cpu0 : 0.3 us, 0.3 sy, 0.0 ni, 66.8 id, 0.3 wa, 0.0 hi, 32.4 si, 0.0 st #软中断数据比较高 %Cpu1 : 0.0 us, 0.3 sy, 0.0 ni, 65.2 id, 0.0 wa, 0.0 hi, 34.5 si, 0.0 st KiB Mem : 8167040 total, 7234236 free, 358976 used, 573828 buff/cache KiB Swap: 0 total, 0 free, 0 used. 7560460 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 9 root 20 0 0 0 0 S 7.0 0.0 0:00.48 ksoftirqd/0 # 18 root 20 0 0 0 0 S 6.9 0.0 0:00.56 ksoftirqd/1 2489 root 20 0 876896 38408 21520 S 0.3 0.5 0:01.50 docker-containe 3008 root 20 0 44536 3936 3304 R 0.3 0.0 0:00.09 top 1 root 20 0 78116 9000 6432 S 0.0 0.1 0:11.77 systemd #两个 CPU 的软中断使用率都超过了 30%;而 CPU 使用率最高的进程,正好是软中断内核线程 ksoftirqd/0 和 ksoftirqd/1。 [root@yefeng ~]# awk '{print $1,$2,$3}' /proc/softirqs #可以看到NET_RX数据是变更较大的 ***对于普通进程,我们要观察其行为有很多方法,比如 strace、pstack、lsof 等等。但这些工具并不适合内核线程, 比如,如果你用 pstack ,或者通过 /proc/pid/stack 查看 ksoftirqd/0(进程号为 9)的调用栈时,分别可以得到以下输出: $ pstack 9 #pstack 报出的是不允许挂载进程的错误; Could not attach to target 9: Operation not permitted. detach: No such process $ cat /proc/9/stack # /proc/9/stack 方式虽然有输出,但输出中并没有详细的调用栈情况。 [<0>] smpboot_thread_fn+0x166/0x170 [<0>] kthread+0x121/0x140 [<0>] ret_from_fork+0x35/0x40 [<0>] 0xffffffffffffffff perf 可以对指定的进程或者事件进行采样,并且还可以用调用栈的形式,输出整个调用链上的汇总信息。 $ perf record -a -g -p 9 -- sleep 30 #-p采集指定进程,采样30s后退出 $ perf report #进行分析 Samples: 1K of event 'cpu-clock', Event count (approx.): 342750000 Children Self Command Shared Object Symbol + 100.00% 0.00% ksoftirqd/1 [kernel.kallsyms] [k] ret_from_fork - 100.00% 0.00% ksoftirqd/1 [kernel.kallsyms] [k] kthread - kthread - 99.93% smpboot_thread_fn - 99.27% run_ksoftirqd - 99.20% __softirqentry_text_start - net_rx_action #接收数据包 - 99.12% __napi_poll - 95.26% process_backlog - 95.04% __netif_receive_skb - __netif_receive_skb_one_core - 87.24% __netif_receive_skb_core - 86.94% br_handle_frame #数据包经过了网桥 - br_handle_frame_finish - 86.36% br_pass_frame_up #表明网桥处理后,再交给桥接的其他桥接网卡进一步处理。比如,在新的网卡上接收网络包、执行 netfilter 过滤规则等等。 - 86.21% br_netif_receive_skb netif_receive_skb #接收数据包 + __netif_receive_skb + 7.51% ip_rcv + 3.65% e1000_clean + 0.66% schedule + 99.93% 0.00% ksoftirqd/1 [kernel.kallsyms] [k] smpboot_thread_fn 从这个图中,你可以清楚看到 ksoftirqd 执行最多的调用过程。虽然你可能不太熟悉内核源码,但通过这些函数,我们可以大致看出它的调用栈过程。 net_rx_action 和 netif_receive_skb,表明这是接收网络包(rx 表示 receive)。 br_handle_frame ,表明网络包经过了网桥(br 表示 bridge)。 br_nf_pre_routing ,表明在网桥上执行了 netfilter 的 PREROUTING(nf 表示 netfilter)。而我们已经知道 PREROUTING 主要用来执行 DNAT,所以可以猜测这里有 DNAT 发生。 可能内核版本不一致吧,没有找到案例中的"br_nf_pre_routing"函数 br_pass_frame_up,表明网桥处理后,再交给桥接的其他桥接网卡进一步处理。比如,在新的网卡上接收网络包、执行 netfilter 过滤规则等等。 虽然perf工具很好,但是火焰图观察汇总结果更为直观 要理解火焰图,我们最重要的是区分清楚横轴和纵轴的含义。 1.横轴表示采样数和采样比例。一个函数占用的横轴越宽,就代表它的执行时间越长。同一层的多个函数,则是按照字母来排序。 2.纵轴表示调用栈,由下往上根据调用关系逐个展开。换句话说,上下相邻的两个函数中,下面的函数,是上面函数的父函数。这样,调用栈越深,纵轴就越高。 3.另外,要注意图中的颜色,并没有特殊含义,只是用来区分不同的函数。 火焰图是动态的矢量图格式,所以它还支持一些动态特性。比如,鼠标悬停到某个函数上时,就会自动显示这个函数的采样数和采样比例。而当你用鼠标点击函数时,火焰图就会把该层及其上的各层放大,方便你观察这些处于火焰图顶部的调用栈的细节。 如果我们根据性能分析的目标来划分,火焰图可以分为下面这几种。 1.on-CPU 火焰图:表示 CPU 的繁忙情况,用在 CPU 使用率比较高的场景中。 2.off-CPU 火焰图:表示 CPU 等待 I/O、锁等各种资源的阻塞情况。 3.内存火焰图:表示内存的分配和释放情况。 4.热 / 冷火焰图:表示将 on-CPU 和 off-CPU 结合在一起综合展示。 5.差分火焰图:表示两个火焰图的差分情况,红色表示增长,蓝色表示衰减。差分火焰图常用来比较不同场景和不同时期的火焰图,以便分析系统变化前后对性能的影响情况。 安装FlameGraph $ git clone https://github.com/brendangregg/FlameGraph $ cd FlameGraph 生成火焰图,其实主要需要三个步骤: 1.执行 perf script ,将 perf record 的记录转换成可读的采样记录; 2.执行 stackcollapse-perf.pl 脚本,合并调用栈信息; 3.执行 flamegraph.pl 脚本,生成火焰图。 #在 Linux 中,我们可以使用管道,来简化这三个步骤的执行过程。假设刚才用 perf record 生成的文件路径为 /root/perf.data,执行下面的命令,你就可以直接生成火焰图: perf script -i /root/perf.data | ./stackcollapse-perf.pl --all | ./flamegraph.pl > ksoftirqd.svg 使用浏览器打开 ksoftirqd.svg ,你就可以看到生成的火焰图了
50 | 案例篇:动态追踪怎么用?(上)
51 | 案例篇:动态追踪怎么用?(下)
strace和ptrace =========================================== strace 简单易用的好处,却忽略了它对进程性能带来的影响。从原理上来说,strace 基于系统调用 ptrace 实现,这就带来了两个问题。 1.由于 ptrace 是系统调用,就需要在内核态和用户态切换。当事件数量比较多时,繁忙的切换必然会影响原有服务的性能; 2.ptrace 需要借助 SIGSTOP 信号挂起目标进程。这种信号控制和进程挂起,会影响目标进程的行为。 所以,在性能敏感的应用(比如数据库)中,我并不推荐你用 strace (或者其他基于 ptrace 的性能工具)去排查和调试。
动态追踪技术概述 ============================================================================ 动态追踪技术,通过探针机制,来采集内核或者应用程序的运行信息,从而可以不用修改内核和应用程序的代码,就获得丰富的信息,帮你分析、定位想要排查的问题。 相比以往的进程级跟踪方法(比如 ptrace),动态追踪往往只会带来很小的性能损耗(通常在 5% 或者更少)。 根据事件类型的不同,动态追踪所使用的事件源,可以分为静态探针、动态探针以及硬件事件等三类。 硬件事件通常由性能监控计数器 PMC(Performance Monitoring Counter)产生,包括了各种硬件的性能情况,比如 CPU 的缓存、指令周期、分支预测等等。 静态探针,是指事先在代码中定义好,并编译到应用程序或者内核中的探针。 动态探针,则是指没有事先在代码中定义,但却可以在运行时动态添加的探针 ftrace 最早用于函数跟踪,后来又扩展支持了各种事件跟踪功能。 perf 是我们的老朋友了,我们在前面的好多案例中,都使用了它的事件记录和分析功能,这实际上只是一种最简单的静态跟踪机制。你也可以通过 perf ,来自定义动态事件(perf probe),只关注真正感兴趣的事件。 eBPF 则在 BPF(Berkeley Packet Filter)的基础上扩展而来,不仅支持事件跟踪机制,还可以通过自定义的 BPF 代码(使用 C 语言)来自由扩展。所以,eBPF 实际上就是常驻于内核的运行时,可以说就是 Linux 版的 DTrace。 最常见的就是前面提到的 SystemTap,我们之前多次使用过的 BCC(BPF Compiler Collection),以及常用于容器性能分析的 sysdig 等。
ftrace 和 trace-cmd工具;perf 和 perf trace;eBPF 和 BCC;SystemTap 和 sysdig(待学习)
52 | 案例篇:服务吞吐量下降很厉害,怎么分析?
服务吞吐量下降的案例:net.netfilter.nf_conntrack_count;内存、CPU资源过少;net.core.somaxconn;net.ipv4.ip_local_port_range;net.ipv4.tcp_tw_reuse ============================================================================================================================== 本案例问题汇总: 1.连接跟踪数太少 2.内存、CPU资源过少 3.套接字监听队列太短 4.设备client时的临时端口太少 5.火焰图分析,系统函数__init_check_established消耗了大量的CPU资源,需要开启端口号的重用 ---------------------------------------------- $ docker run --name nginx --network host --privileged -itd feisky/nginx-tp $ docker run --name phpfpm --network host --privileged -itd feisky/php-fpm-tp $ docker ps #容器已经处于运行状态(Up) CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 09e0255159f0 feisky/php-fpm-tp "php-fpm -F --pid /o…" 28 seconds ago Up 27 seconds phpfpm 6477c607c13b feisky/nginx-tp "/init.sh" 29 seconds ago Up 28 seconds nginx $ curl http://192.168.0.30 $ wrk --latency -c 1000 http://192.168.0.30 ## 默认测试时间为10s,请求超时2s Running 10s test @ http://192.168.0.30 2 threads and 1000 connections Thread Stats Avg Stdev Max +/- Stdev Latency 14.82ms 42.47ms 874.96ms 98.43% Req/Sec 550.55 1.36k 5.70k 93.10% Latency Distribution 50% 11.03ms 75% 15.90ms 90% 23.65ms 99% 215.03ms 1910 requests in 10.10s, 573.56KB read #一共1910个请求 Non-2xx or 3xx responses: 1910 #所有 1910 个请求收到的都是异常响应(非 2xx 或 3xx) Requests/sec: 189.10 #吞吐量(也就是每秒请求数)只有 189 Transfer/sec: 56.78KB 可以看到wrk的测试结果,数据很差 ---------------------------------------------------------------------------------------------- 开始测试并优化 $ wrk --latency -c 1000 -d 1800 http://192.168.0.30 ## 测试时间30分钟 server端观察连接数 $ ss -s Total: 177 (kernel 1565) TCP: 1193 (estab 5, closed 1178, orphaned 0, synrecv 0, timewait 1178/0), ports 0 Transport Total IP IPv6 * 1565 - - RAW 1 0 1 UDP 2 2 0 TCP 15 12 3 INET 18 14 4 FRAG 0 0 0 #wrk 并发 1000 请求时,建立连接数只有 5,而 closed 和 timewait 状态的连接则有 1100 多 #一个是建立连接数太少了 #一个是 timewait 状态连接太多了 先来看第二个关于 timewait 的问题 内核中的连接跟踪模块,有可能会导致 timewait 问题。 我们今天的案例还是基于 Docker 运行,而 Docker 使用的 iptables ,就会使用连接跟踪模块来管理 NAT。 确认是不是连接跟踪导致的问题的方法: 通过 dmesg 查看系统日志,如果有连接跟踪出了问题,应该会看到 nf_conntrack 相关的日志。 $ dmesg | tail [88356.354329] nf_conntrack: nf_conntrack: table full, dropping packet [88356.354374] nf_conntrack: nf_conntrack: table full, dropping packet #说明正是连接跟踪导致的问题 $ sysctl net.netfilter.nf_conntrack_max #连接跟踪数的最大限制 net.netfilter.nf_conntrack_max = 200 $ sysctl net.netfilter.nf_conntrack_count #当前的连接跟踪数 net.netfilter.nf_conntrack_count = 200 $ sysctl -w net.netfilter.nf_conntrack_max=1048576 #将 nf_conntrack_max 增大 ----------------------------------------- server端再次进行测试 $ wrk --latency -c 1000 http://192.168.0.30 # 默认测试时间为10s,请求超时2s ... 54221 requests in 10.07s, 15.16MB read Socket errors: connect 0, read 7, write 0, timeout 110 Non-2xx or 3xx responses: 45577 #10s 内的总请求数虽然增大到了 5 万,但是有 4 万多响应异常,说白了,真正成功的只有 8000 多个(54221-45577=8644)。 Requests/sec: 5382.21 #连接跟踪的优化效果非常好,吞吐量已经从刚才的 189 增大到了 5382。看起来性能提升了将近 30 倍 Transfer/sec: 1.50MB 响应的状态码并不是我们期望的 2xx (表示成功)或 3xx(表示重定向) 这种情况下,搞清楚 Nginx 真正的响应就很重要了。 查询 Nginx 容器日志 $ docker logs nginx --tail 3 192.168.0.2 - - [15/Mar/2019:2243:27 +0000] "GET / HTTP/1.1" 499 0 "-" "-" "-" #499 并非标准的 HTTP 状态码,而是由 Nginx 扩展而来,表示服务器端还没来得及响应时,客户端就已经关闭连接了。 192.168.0.2 - - [15/Mar/2019:22:43:27 +0000] "GET / HTTP/1.1" 499 0 "-" "-" "-" 192.168.0.2 - - [15/Mar/2019:22:43:27 +0000] "GET / HTTP/1.1" 499 0 "-" "-" "-" #问题在于服务器端处理太慢,客户端因为超时(wrk 超时时间为 2s),主动断开了连接。 案例本身是 Nginx+PHP 的应用,那是不是可以猜测,是因为 PHP 处理过慢呢? $ docker logs phpfpm --tail 5 [15-Mar-2019 22:28:56] WARNING: [pool www] server reached max_children setting (5), consider raising it [15-Mar-2019 22:43:17] WARNING: [pool www] server reached max_children setting (5), consider raising it #从这个日志中,我们可以看到两条警告信息,server reached max_children setting (5),并建议增大 max_children。 max_children 表示 php-fpm 子进程的最大数量,当然是数值越大,可以同时处理的请求数就越多。 不过由于这是进程问题,数量增大,也会导致更多的内存和 CPU 占用。所以,我们还不能设置得过大。 一般来说,每个 php-fpm 子进程可能会占用 20 MB 左右的内存。所以,你可以根据内存和 CPU 个数,估算一个合理的值。 这儿我把它设置成了 20,并将优化后的配置重新打包成了 Docker 镜像。你可以执行下面的命令来执行它: # 停止旧的容器 $ docker rm -f nginx phpfpm # 使用新镜像启动Nginx和PHP $ docker run --name nginx --network host --privileged -itd feisky/nginx-tp:1 $ docker run --name phpfpm --network host --privileged -itd feisky/php-fpm-tp:1 那么问题2其实是PHP容器的子进程数量过少,应付不了这么高的并发导致的 ----------------------------------------- server端再次进行测试 $ wrk --latency -c 1000 http://192.168.0.30 # 默认测试时间为10s,请求超时2s ... 47210 requests in 10.08s, 12.51MB read Socket errors: connect 0, read 4, write 0, timeout 91 Non-2xx or 3xx responses: 31692 #但是测试期间成功的请求数却多了不少,从原来的 8000,增长到了 15000(47210-31692=15518)。 Requests/sec: 4683.82 #吞吐量只有 4683,比刚才的 5382 少了一些; Transfer/sec: 1.24MB 虽然性能有所提升,可 4000 多的吞吐量显然还是比较差的,并且大部分请求的响应依然还是异常。 重新运行测试,这次还是要用 -d 参数延长测试时间,以便模拟性能瓶颈的现场 $ wrk --latency -c 1000 -d 1800 http://192.168.0.30 ## 测试时间30分钟 # 只关注套接字统计 $ netstat -s | grep socket 73 resets received for embryonic SYN_RECV sockets 308582 TCP sockets finished time wait in fast timer 8 delayed acks further delayed because of locked socket 290566 times the listen queue of a socket overflowed 290566 SYNs to LISTEN sockets dropped # 稍等一会,再次运行 $ netstat -s | grep socket 73 resets received for embryonic SYN_RECV sockets 314722 TCP sockets finished time wait in fast timer 8 delayed acks further delayed because of locked socket 344440 times the listen queue of a socket overflowed #有大量的套接字丢包,并且丢包都是套接字队列溢出导致的 344440 SYNs to LISTEN sockets dropped #有大量的套接字丢包,并且丢包都是套接字队列溢出导致的 这说明要么测试并发过高,要么服务端的tcp半连接队列太短 接下来,我们应该分析连接队列的大小是不是有异常。 $ ss -ltnp State Recv-Q Send-Q Local Address:Port Peer Address:Port LISTEN 10 10 0.0.0.0:80 0.0.0.0:* users:(("nginx",pid=10491,fd=6),("nginx",pid=10490,fd=6),("nginx",pid=10487,fd=6)) LISTEN 7 10 *:9000 *:* users:(("php-fpm",pid=11084,fd=9),...,("php-fpm",pid=10529,fd=7)) Nginx 和 php-fpm 的监听队列 (Send-Q)只有 10,而 nginx 的当前监听队列长度 (Recv-Q)已经达到了最大值,php-fpm 也已经接近了最大值。 很明显,套接字监听队列的长度太小了,需要增大。 关于套接字监听队列长度的设置,既可以在应用程序中,通过套接字接口调整,也支持通过内核选项来配置。 $ docker exec nginx cat /etc/nginx/nginx.conf | grep backlog # listen 80 backlog=10; $ docker exec phpfpm cat /opt/bitnami/php/etc/php-fpm.d/www.conf | grep backlog ## 查询php-fpm监听队列长度 ; Set listen(2) backlog. ;listen.backlog = 511 $ sysctl net.core.somaxconn ## somaxconn是系统级套接字监听队列上限 net.core.somaxconn = 10 从输出中可以看到,Nginx 和 somaxconn 的配置都是 10,而 php-fpm 的配置也只有 511,显然都太小了。 解决办法:优化方法就是增大这三个配置,比如,可以把 Nginx 和 php-fpm 的队列长度增大到 8192,而把 somaxconn 增大到 65536。 # 停止旧的容器 $ docker rm -f nginx phpfpm # 使用新镜像启动Nginx和PHP $ docker run --name nginx --network host --privileged -itd feisky/nginx-tp:2 $ docker run --name phpfpm --network host --privileged -itd feisky/php-fpm-tp:2 -------------------------------------------------------------------------- $ wrk --latency -c 1000 http://192.168.0.30 ... 62247 requests in 10.06s, 18.25MB read Non-2xx or 3xx responses: 62247 Requests/sec: 6185.65 Transfer/sec: 1.81MB #吞吐量已经增大到了 6185,并且在测试的时候,如果你在终端一中重新执行 netstat -s | grep socket,还会发现,现在已经没有套接字丢包问题了。 # Nginx 的响应,再一次全部失败了,都是 Non-2xx or 3xx。 查看 Nginx 日志 $ docker logs nginx --tail 10 2019/03/15 16:52:39 [crit] 15#15: *999779 connect() to 127.0.0.1:9000 failed (99: Cannot assign requested address) while connecting to upstream, client: 192.168.0.2, server: localhost, request: "GET / HTTP/1.1", upstream: "fastcgi://127.0.0.1:9000", host: "192.168.0.30" #Nginx 报出了无法连接 fastcgi 的错误,错误消息是 Connect 时, Cannot assign requested address。这个错误消息对应的错误代码为 EADDRNOTAVAIL,表示 IP 地址或者端口号不可用。 显然只能是端口号的问题。接下来,我们就来分析端口号的情况 根据网络套接字的原理,当客户端连接服务器端时,需要分配一个临时端口号,而 Nginx 正是 PHP-FPM 的客户端。端口号的范围并不是无限的,最多也只有 6 万多。 查询系统配置的临时端口号范围 $ sysctl net.ipv4.ip_local_port_range #临时端口的范围只有 50 个,显然太小了 net.ipv4.ip_local_port_range=20000 20050 $ sysctl -w net.ipv4.ip_local_port_range="10000 65535" #把端口号范围扩展为 “10000 65535” net.ipv4.ip_local_port_range = 10000 65535 ------------------------------------------------ $ wrk --latency -c 1000 http://192.168.0.30/ ... 32308 requests in 10.07s, 6.71MB read Socket errors: connect 0, read 2027, write 0, timeout 433 Non-2xx or 3xx responses: 30 Requests/sec: 3208.58 Transfer/sec: 682.15KB #异常的响应少多了 ,不过,吞吐量也下降到了 3208。并且,这次还出现了很多 Socket read errors。显然,还得进一步优化。 前面我们已经优化了很多配置。这些配置在优化网络的同时,却也会带来其他资源使用的上升。这样来看,是不是说明其他资源遇到瓶颈了呢? $ wrk --latency -c 1000 -d 1800 http://192.168.0.30 # 测试时间30分钟 $ top #sever端观察 ... %Cpu0 : 30.7 us, 48.7 sy, 0.0 ni, 2.3 id, 0.0 wa, 0.0 hi, 18.3 si, 0.0 st %Cpu1 : 28.2 us, 46.5 sy, 0.0 ni, 2.0 id, 0.0 wa, 0.0 hi, 23.3 si, 0.0 st KiB Mem : 8167020 total, 5867788 free, 490400 used, 1808832 buff/cache KiB Swap: 0 total, 0 free, 0 used. 7361172 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 20379 systemd+ 20 0 38068 8692 2392 R 36.1 0.1 0:28.86 nginx 20381 systemd+ 20 0 38024 8700 2392 S 33.8 0.1 0:29.29 nginx 1558 root 20 0 1118172 85868 39044 S 32.8 1.1 22:55.79 dockerd 20313 root 20 0 11024 5968 3956 S 27.2 0.1 0:22.78 docker-containe 13730 root 20 0 0 0 0 I 4.0 0.0 0:10.07 kworker/u4:0-ev 从 top 的结果中可以看到,可用内存还是很充足的,但系统 CPU 使用率(sy)比较高,两个 CPU 的系统 CPU 使用率都接近 50%, 且空闲 CPU 使用率只有 2%。再看进程部分,CPU 主要被两个 Nginx 进程和两个 docker 相关的进程占用,使用率都是 30% 左右。 CPU 使用率上升了,该怎么进行分析呢?我想,你已经还记得我们多次用到的 perf,再配合前两节讲过的火焰图,很容易就能找到系统中的热点函数。 # 执行perf记录事件 $ perf record -g # 切换到FlameGraph安装路径执行下面的命令生成火焰图 $ perf script -i ~/perf.data | ./stackcollapse-perf.pl --all | ./flamegraph.pl > nginx.svg 查看火焰图进行分析 根据我们讲过的火焰图原理,这个图应该从下往上、沿着调用栈中最宽的函数,来分析执行次数最多的函数。 中间的 do_syscall_64、tcp_v4_connect、inet_hash_connect 这个堆栈,很明显就是最需要关注的地方。 inet_hash_connect() 是 Linux 内核中负责分配临时端口号的函数。 所以,这个瓶颈应该还在临时端口的分配上。 在上一步的“端口号”优化中,临时端口号的范围,已经优化成了 “10000 65535”。这显然是一个非常大的范围,那么,端口号的分配为什么又成了瓶颈呢? 再顺着 inet_hash_connect 往堆栈上面查看,下一个热点是 __init_check_established 函数 __init_check_established 函数的目的,是检查端口号是否可用。 结合这一点,你应该可以想到,如果有大量连接占用着端口,那么检查端口号可用的函数,不就会消耗更多的 CPU 吗? $ ss -s #查看连接状态统计 TCP: 32775 (estab 1, closed 32768, orphaned 0, synrecv 0, timewait 32768/0), ports 0 ... 有大量连接(这儿是 32768)处于 timewait 状态,而 timewait 状态的连接,本身会继续占用端口号。如果这些端口号可以重用,那么自然就可以缩短 __init_check_established 的过程。 $ sysctl net.ipv4.tcp_tw_reuse #tcp_tw_reuse 选项,用来控制端口号的重用 net.ipv4.tcp_tw_reuse = 0 #tcp_tw_reuse 是 0,也就是禁止状态。 优化方法也很容易,把它设置成 1 就可以开启了。 # 停止旧的容器 $ docker rm -f nginx phpfpm # 使用新镜像启动Nginx和PHP $ docker run --name nginx --network host --privileged -itd feisky/nginx-tp:3 $ docker run --name phpfpm --network host --privileged -itd feisky/php-fpm-tp:3 ------------------------------------------------------------------- 最终测试 $ wrk --latency -c 1000 http://192.168.0.30/ ... 52119 requests in 10.06s, 10.81MB read Socket errors: connect 0, read 850, write 0, timeout 0 Requests/sec: 5180.48 Transfer/sec: 1.07MB 吞吐量已经达到了 5000 多,并且只有少量的 Socket errors,也不再有 Non-2xx or 3xx 的响应了。说明一切终于正常了。
53 | 套路篇:系统监控的综合思路
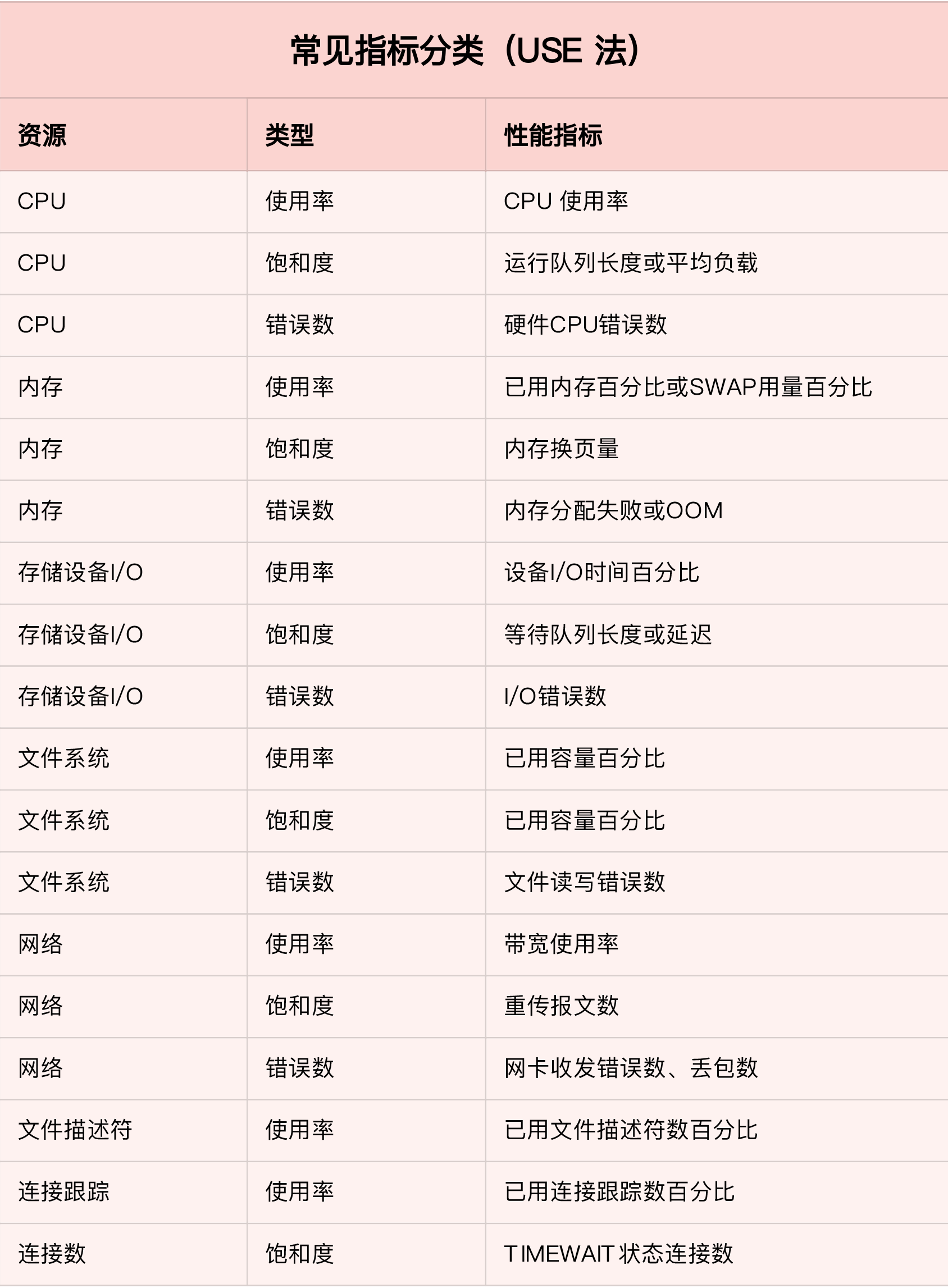
USE 法把系统资源的性能指标,简化成了三个类别,即使用率、饱和度以及错误数。 使用率,表示资源用于服务的时间或容量百分比。100% 的使用率,表示容量已经用尽或者全部时间都用于服务。 饱和度,表示资源的繁忙程度,通常与等待队列的长度相关。100% 的饱和度,表示资源无法接受更多的请求。 错误数表示发生错误的事件个数。错误数越多,表明系统的问题越严重。
54 | 套路篇:应用监控的一般思路
55 | 套路篇:分析性能问题的一般步骤
56 | 套路篇:优化性能问题的一般方法
57 | 套路篇:Linux 性能工具速查

 浙公网安备 33010602011771号
浙公网安备 33010602011771号