
数据采集第三次作业
一.作业①
(要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。)
1.代码与运行
(1)代码展示:
spider代码:
import scrapy
import json
class StockSpider(scrapy.Spider):
name = 'stock_info'
start_urls = [
# URL remains the same
]
def start_requests(self):
headers = {
'User-Agent': self.user_agent,
}
for url in self.start_urls:
yield scrapy.Request(url, headers=headers, callback=self.parse)
def parse(self, response):
data = response.text
json_data = json.loads(data[data.find('(') + 1:data.rfind(')')])
stock_list = json_data.get('data', {}).get('diff', [])
for stock in stock_list:
item = StockInfoItem()
item['stock_code'] = stock.get('f12')
item['stock_name'] = stock.get('f14')
item['current_price'] = stock.get('f2')
item['price_change_rate'] = stock.get('f3')
item['price_change_amount'] = stock.get('f4')
item['trade_volume'] = stock.get('f5')
item['price_fluctuation'] = stock.get('f7')
item['highest_price'] = stock.get('f15')
item['lowest_price'] = stock.get('f16')
item['opening_price'] = stock.get('f17')
item['closing_price'] = stock.get('f18')
yield item
@property
def user_agent(self):
return 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36 Edg/130.0.0.0'
items代码:
import scrapy
class StockInfoItem(scrapy.Item):
item_id = scrapy.Field() # 序号
stock_code = scrapy.Field() # 股票代码
stock_name = scrapy.Field() # 股票名称
current_price = scrapy.Field() # 最新报价
price_change_rate = scrapy.Field() # 涨跌幅
price_change_amount = scrapy.Field() # 涨跌额
trade_volume = scrapy.Field() # 成交量
price_fluctuation = scrapy.Field() # 振幅
highest_price = scrapy.Field() # 最高
lowest_price = scrapy.Field() # 最低
opening_price = scrapy.Field() # 今开
closing_price = scrapy.Field() # 昨收
pipelines代码:
import mysql.connector
class DatabasePipeline:
def open_spider(self, spider):
self.connection = mysql.connector.connect(
host='localhost',
user='root',
password='123456',
database='hh'
)
self.cursor = self.connection.cursor()
def close_spider(self, spider):
self.cursor.close()
self.connection.close()
def process_item(self, item, spider):
sql = """
INSERT INTO stocks (bStockNo, stockName, latestPrice, changeRate, changeAmount, volume, amplitude, high, low, openPrice, closePrice)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
self.cursor.execute(sql, (
item['stock_code'], item['stock_name'], item['current_price'],
item['price_change_rate'], item['price_change_amount'], item['trade_volume'],
item['price_fluctuation'], item['highest_price'], item['lowest_price'],
item['opening_price'], item['closing_price']
))
self.connection.commit()
return item
(2)运行展示:
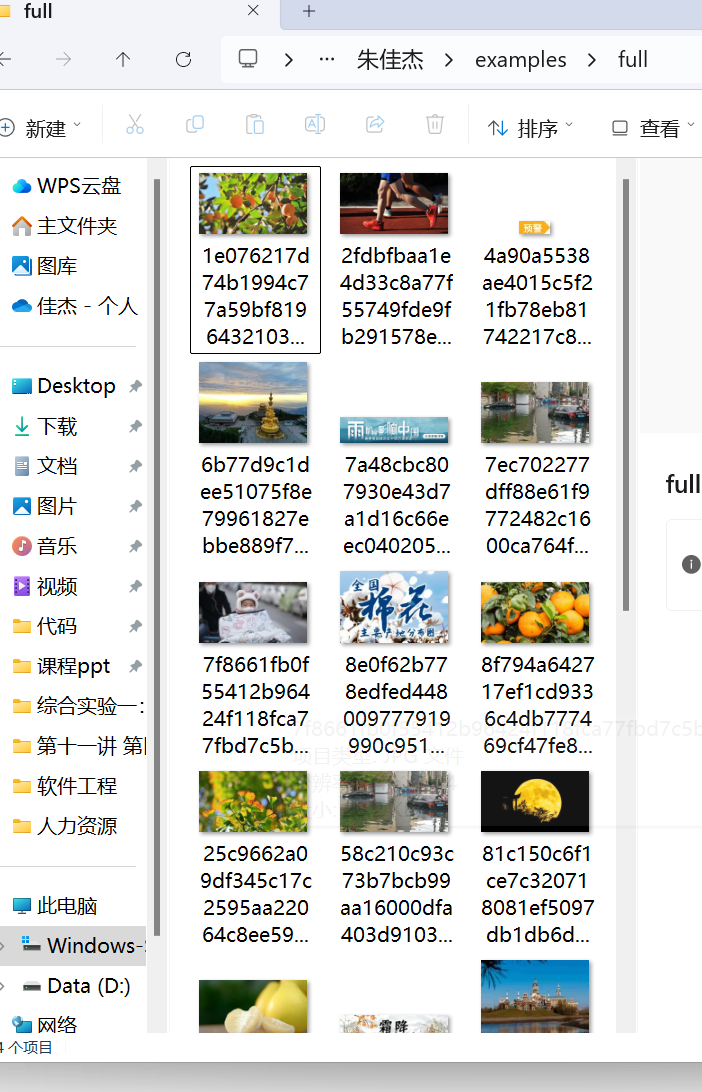
三.作业③
(要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。)
1.代码与运行
(1)代码展示:
spider代码:
import scrapy
from ..items import ChinaBankItem
class BankSpider(scrapy.Spider):
name = "bank_spider"
allowed_domains = ["www.boc.cn"]
def start_requests(self):
num_pages = 2
base_url = "https://www.boc.cn/sourcedb/whpj/index.html"
for page in range(num_pages):
url = base_url if page == 0 else f"{base_url}_{page}.html"
yield scrapy.Request(url=url, callback=self.parse_page)
def parse_page(self, response):
html_data = response.body.decode('utf-8')
selector = scrapy.Selector(text=html_data)
table_selector = selector.xpath("//div[@class='publish']//table")
table_rows = table_selector.xpath(".//tr")
headers = table_rows[1].xpath('.//th/text()').extract()
print(headers)
for row in table_rows[2:]:
bank_item = ChinaBankItem()
bank_item["currency"] = row.xpath("./td[1]/text()").get()
bank_item["tbp"] = row.xpath("./td[2]/text()").get()
bank_item["cbp"] = row.xpath("./td[3]/text()").get()
bank_item["tsp"] = row.xpath("./td[4]/text()").get()
bank_item["csp"] = row.xpath("./td[5]/text()").get()
bank_item["time"] = row.xpath("./td[7]/text()").get()
yield bank_item
items代码:
import scrapy
class ChinaBankItem(scrapy.Item):
currency = scrapy.Field()
tbp = scrapy.Field()
cbp = scrapy.Field()
tsp = scrapy.Field()
csp = scrapy.Field()
time = scrapy.Field()
pipelines代码:
from itemadapter import ItemAdapter
import mysql.connector
class ChinaBankPipeline:
processed_count = 0
def process_item(self, item, spider):
try:
database_connection = mysql.connector.connect(
host="localhost",
user="root",
password="123456",
database="DataAcquisition"
)
cursor = database_connection.cursor()
if self.processed_count == 0:
self.create_table_structure(cursor)
self.insert_into_database(cursor, item)
database_connection.commit()
database_connection.close()
except Exception as e:
print(f"Database error: {e}")
finally:
self.processed_count += 1
return item
def create_table_structure(self, cursor):
cursor.execute("DROP TABLE IF EXISTS bank")
cursor.execute("""
CREATE TABLE bank (
currency VARCHAR(64) PRIMARY KEY,
tbp FLOAT,
cbp FLOAT,
tsp FLOAT,
csp FLOAT,
time VARCHAR(64)
)
""")
def insert_into_database(self, cursor, item):
sql = """
INSERT INTO bank (currency, tbp, cbp, tsp, csp, time)
VALUES (%s, %s, %s, %s, %s, %s)
"""
cursor.execute(sql, (
item.get('currency'),
item.get('tbp'),
item.get('cbp'),
item.get('tsp'),
item.get('csp'),
item.get('time')
))
(2)运行展示(我电脑的mysql有问题,mysql.connector没办法和mysql里的插件兼容,升级connector包,重装mysql,插件调换都没有用):
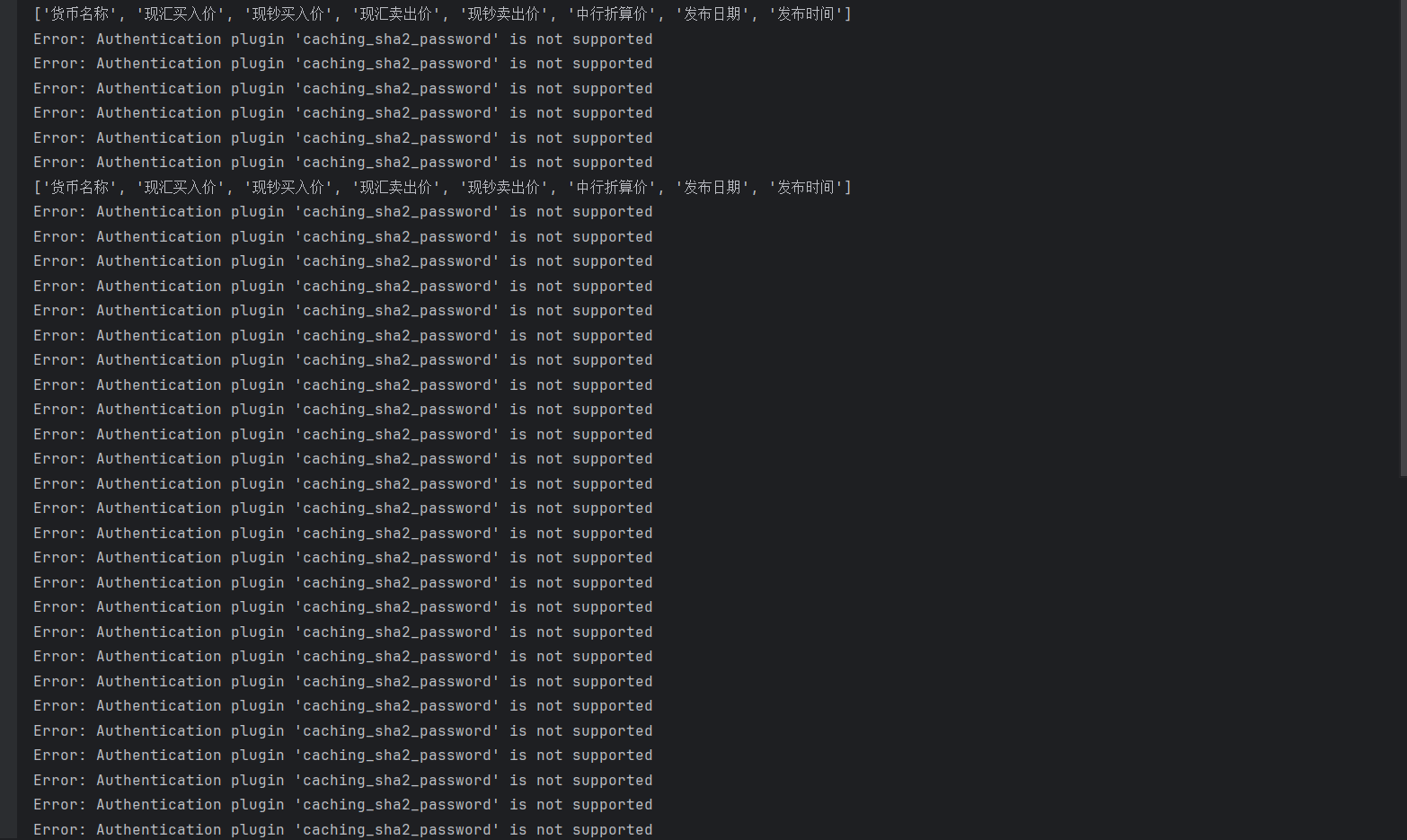
二.作业②
(要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。)
1.代码与运行
(1)代码展示:
spider代码:
import scrapy
import json
class StockSpider(scrapy.Spider):
name = 'stock_info'
start_urls = [
# URL remains the same
]
def start_requests(self):
headers = {
'User-Agent': self.user_agent,
}
for url in self.start_urls:
yield scrapy.Request(url, headers=headers, callback=self.parse)
def parse(self, response):
data = response.text
json_data = json.loads(data[data.find('(') + 1:data.rfind(')')])
stock_list = json_data.get('data', {}).get('diff', [])
for stock in stock_list:
item = StockInfoItem()
item['stock_code'] = stock.get('f12')
item['stock_name'] = stock.get('f14')
item['current_price'] = stock.get('f2')
item['price_change_rate'] = stock.get('f3')
item['price_change_amount'] = stock.get('f4')
item['trade_volume'] = stock.get('f5')
item['price_fluctuation'] = stock.get('f7')
item['highest_price'] = stock.get('f15')
item['lowest_price'] = stock.get('f16')
item['opening_price'] = stock.get('f17')
item['closing_price'] = stock.get('f18')
yield item
@property
def user_agent(self):
return 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36 Edg/130.0.0.0'
items代码:
import scrapy
class StockInfoItem(scrapy.Item):
item_id = scrapy.Field() # 序号
stock_code = scrapy.Field() # 股票代码
stock_name = scrapy.Field() # 股票名称
current_price = scrapy.Field() # 最新报价
price_change_rate = scrapy.Field() # 涨跌幅
price_change_amount = scrapy.Field() # 涨跌额
trade_volume = scrapy.Field() # 成交量
price_fluctuation = scrapy.Field() # 振幅
highest_price = scrapy.Field() # 最高
lowest_price = scrapy.Field() # 最低
opening_price = scrapy.Field() # 今开
closing_price = scrapy.Field() # 昨收
pipelines代码:
import mysql.connector
class DatabasePipeline:
def open_spider(self, spider):
self.connection = mysql.connector.connect(
host='localhost',
user='root',
password='123456',
database='hh'
)
self.cursor = self.connection.cursor()
def close_spider(self, spider):
self.cursor.close()
self.connection.close()
def process_item(self, item, spider):
sql = """
INSERT INTO stocks (bStockNo, stockName, latestPrice, changeRate, changeAmount, volume, amplitude, high, low, openPrice, closePrice)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
self.cursor.execute(sql, (
item['stock_code'], item['stock_name'], item['current_price'],
item['price_change_rate'], item['price_change_amount'], item['trade_volume'],
item['price_fluctuation'], item['highest_price'], item['lowest_price'],
item['opening_price'], item['closing_price']
))
self.connection.commit()
return item
(2)运行展示(问题同上,电脑的mysql有问题,mysql.connector没办法和mysql里的插件兼容,升级connector包,重装mysql,插件调换都没有用,显示不出来结果):
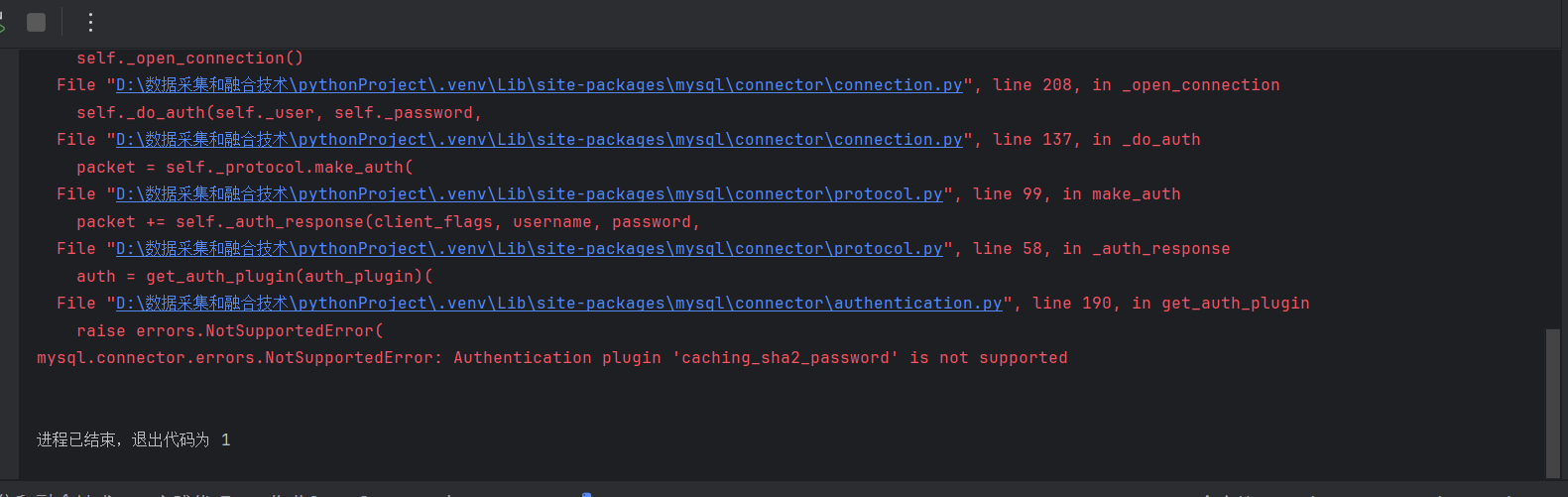
心得体会
通过三次实践作业,加深了对scrapy,数据库,xpath的理论知识的记忆,对三者在实践中的结合以及具体应用场景中三者的结构有了一定的理解和体会。虽然没办法使用mysql
查看结果数据库,但是在排查原因以及尝试解决mysql问题的过程中对数据库管理系统有更细致的认识
码云链接
https://gitee.com/jia1666372886/data-collection-practice/tree/master/作业3/


