

数据采集第二次作业
一.作业①
(作业要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。)
1.代码与运行
(1)代码展示:
import sqlite3
from bs4 import BeautifulSoup
import urllib.request
class WTFC:
def __init__(self, db_name='weather.db'):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36 Edg/130.0.0.0"}
self.cityCode = {"北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601"}
self.conn = sqlite3.connect(db_name)
self.cursor = self.conn.cursor()
self.create_table()
def create_table(self):
"""创建存储天气数据的表"""
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS weather (
id INTEGER PRIMARY KEY,
city TEXT,
date TEXT,
weather TEXT,
temperature TEXT
)
''')
self.conn.commit()
def fC(self, city):
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req).read()
soup = BeautifulSoup(data, "lxml")
eles = soup.select("ul[class='t clearfix'] li")
for li in eles:
try:
print(city, li.select('h1')[0].text,li.select('p[class="wea"]')[0].text, li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text)
self.save_to_db(city, li.select('h1')[0].text,li.select('p[class="wea"]')[0].text, li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text)
except Exception as err:
print("Error")
except Exception as err:
print("Error")
def save_to_db(self, city, date, weather, temperature):
"""将天气数据保存到数据库"""
self.cursor.execute('''
INSERT INTO weather (city, date, weather, temperature) VALUES (?, ?, ?, ?)
''', (city, date, weather, temperature))
self.conn.commit()
def dealing(self, cities):
for city in cities:
self.fC(city)
def close(self):
"""关闭数据库连接"""
self.conn.close()
# 实例化WTFC,打开数据库,爬取数据,提取数据,存进数据库,关闭数据库
a = WTFC()
a.dealing(["北京", "上海", "广州", "深圳"])
a.close()
(2)运行展示:
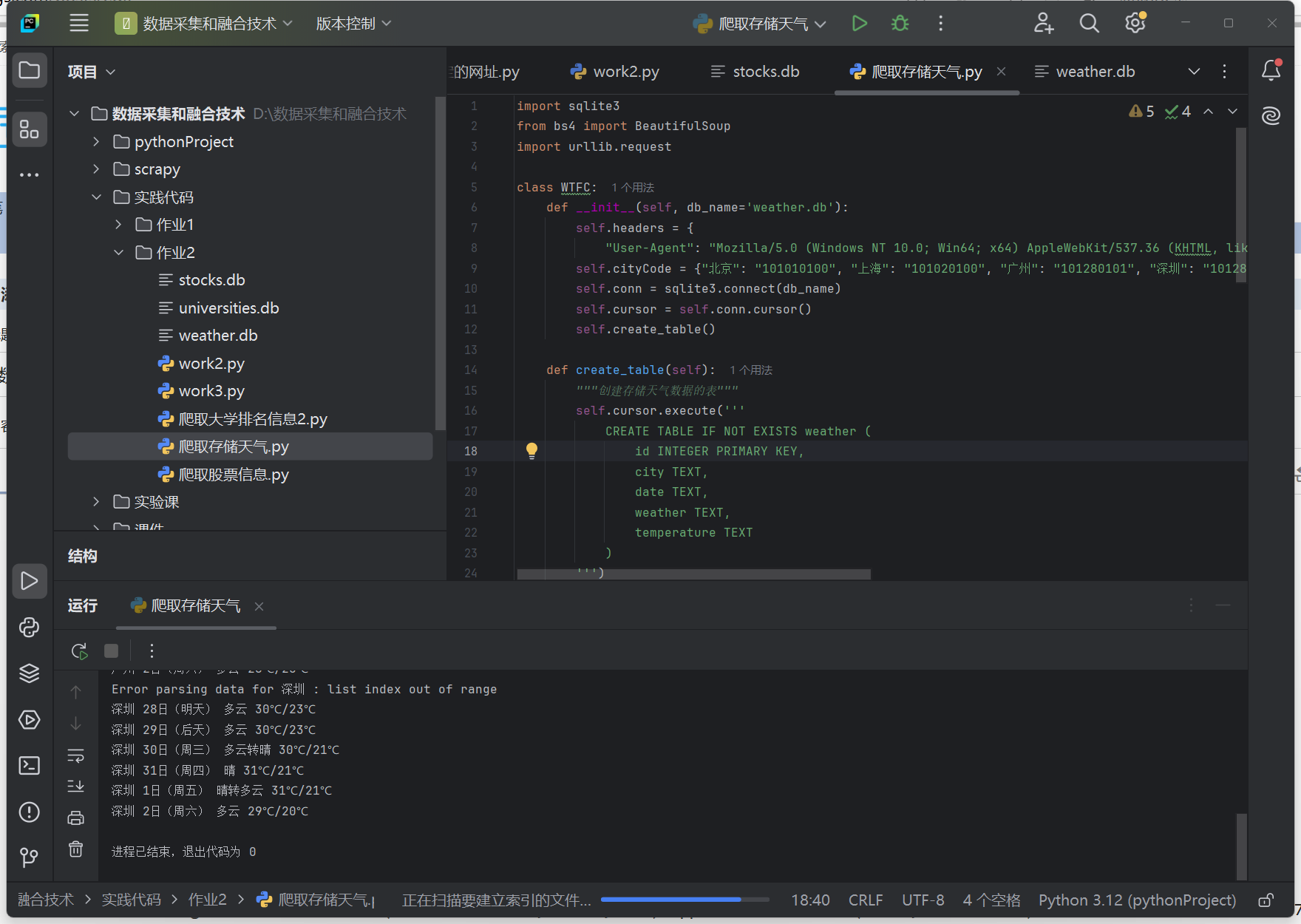
2.心得体会:
1.对数据库使用的记忆更加深刻。
码云链接 https://gitee.com/jia1666372886/data-collection-work/issues
二.作业②
(作业要求:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。)
1.代码与运行
(1)代码展示:
import requests
import re
import json
import sqlite3
import pandas as pd
def fetch_data(api_url, headers):
"""发送请求并获取数据"""
response = requests.get(api_url, headers=headers)
return response.text
def extract_json(jsonp_text):
"""从JSONP文本中提取JSON数据"""
match = re.search(r'\((.*)\)', jsonp_text)
if match:
return json.loads(match.group(1))
return None
def create_or_connect_db(db_name):
"""连接或创建数据库"""
return sqlite3.connect(db_name)
def setup_table(cursor):
"""设置数据库表"""
cursor.execute('''
CREATE TABLE IF NOT EXISTS stocks (
id INTEGER PRIMARY KEY AUTOINCREMENT,
code TEXT,
name TEXT,
price REAL,
change_percent REAL,
volume INTEGER,
amount REAL
)
''')
def insert_stock_data(cursor, stock):
"""插入单条股票数据"""
cursor.execute('''
INSERT INTO stocks (code, name, price, change_percent, volume, amount)
VALUES (?, ?, ?, ?, ?, ?)
''', (stock['f12'], stock['f14'], stock['f2'], stock['f3'], stock['f5'], stock['f6']))
def store_data(data, db_connection):
"""存储数据到数据库"""
cursor = db_connection.cursor()
setup_table(cursor)
for stock in data['data']['diff']:
insert_stock_data(cursor, stock)
db_connection.commit()
def query_and_display_data(db_connection):
"""查询数据库并展示数据"""
cursor = db_connection.cursor()
query = 'SELECT * FROM stocks'
df = pd.read_sql_query(query, db_connection)
return df
def main():
api_url = 'https://71.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124071710431543095_1728983729650&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1728983729651'
headers = {
'user-agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0'
}
# 获取数据
jsonp_text = fetch_data(api_url, headers)
data = extract_json(jsonp_text)
# 存储数据到数据库
if data:
db_connection = create_or_connect_db('stocks.db')
store_data(data, db_connection)
db_connection.close()
else:
print("No data retrieved.")
# 查询并展示数据
db_connection = create_or_connect_db('stocks.db')
df = query_and_display_data(db_connection)
db_connection.close()
print(df)
if __name__ == "__main__":
main()
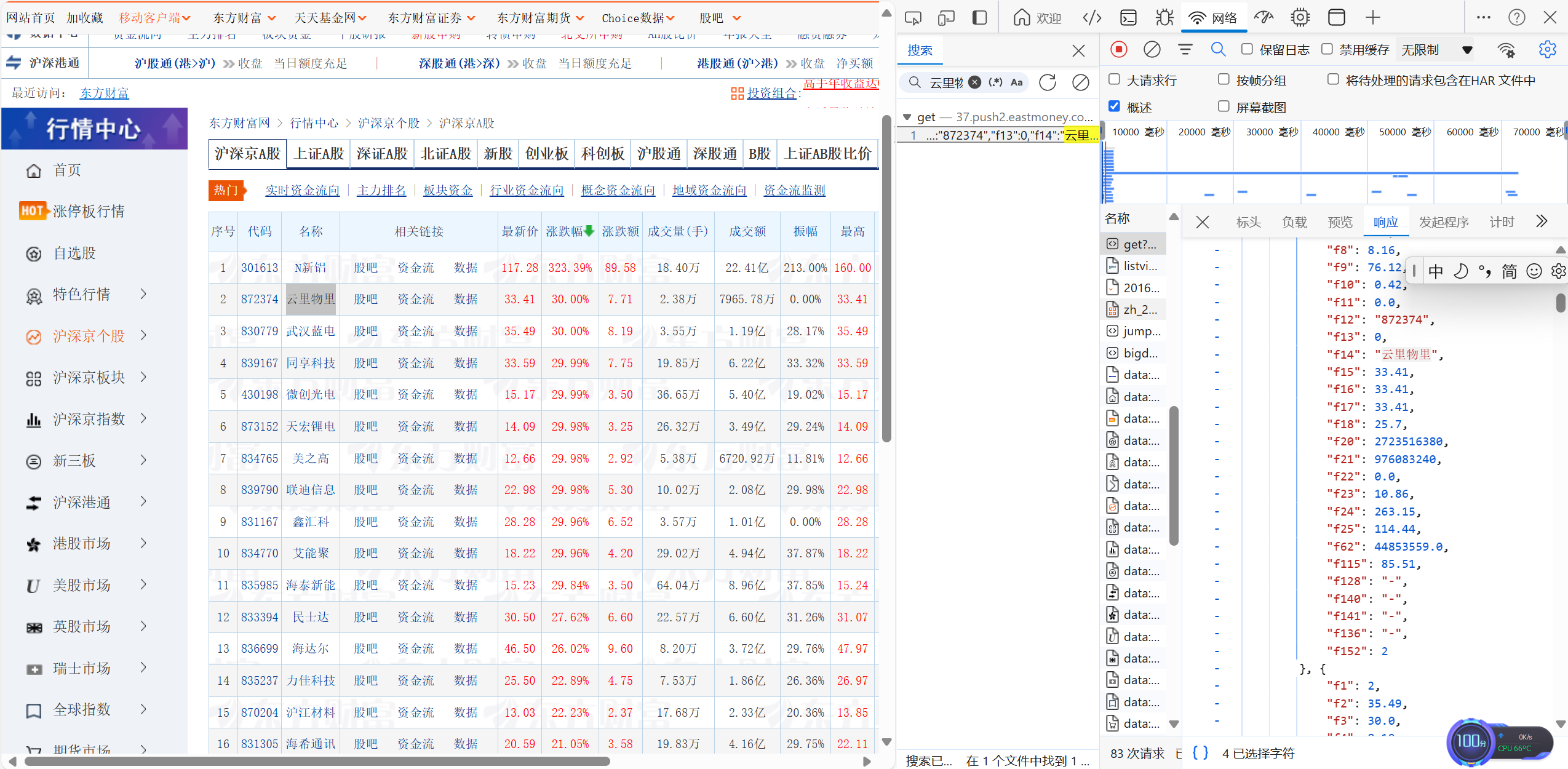
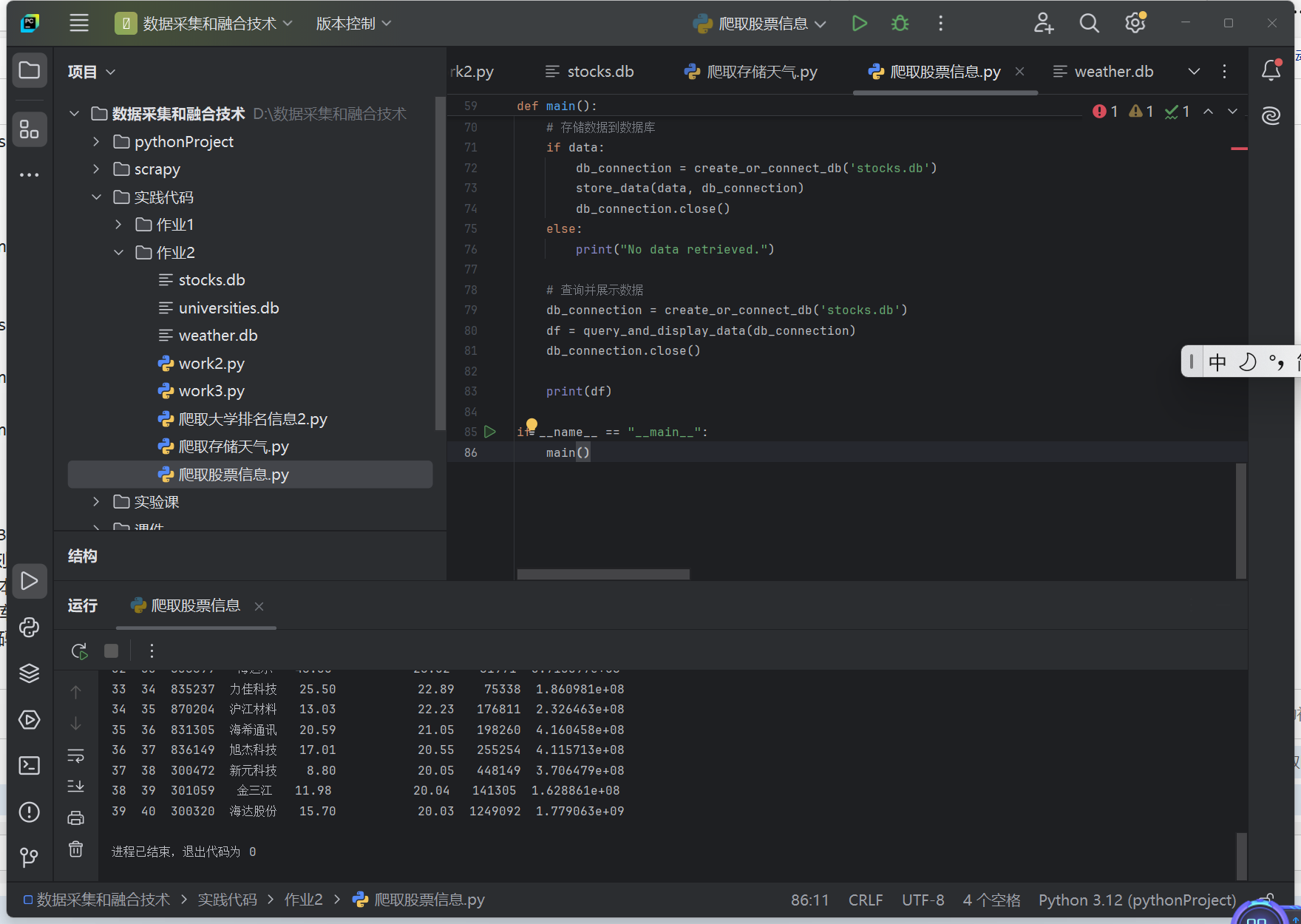
(2)运行展示:
抓包过程
运行结果
码云链接 https://gitee.com/jia1666372886/data-collection-work/issues
2.心得体会:
1学会了抓包过程,分析api返回值和参数
三.作业③
(作业要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。)
1.代码与运行
(1)代码展示:
import urllib.request
from bs4 import BeautifulSoup
import sqlite3
def fetch_html(url, headers):
"""使用urllib请求网页内容,并返回HTML内容"""
req = urllib.request.Request(url, headers=headers)
with urllib.request.urlopen(req) as response:
return response.read().decode('utf-8')
def parse_html(html_content):
"""使用BeautifulSoup解析HTML,并返回包含排名信息的表格"""
soup = BeautifulSoup(html_content, 'html.parser')
return soup.find('table', {'class': 'rk-table'})
def create_db_table(cursor):
"""在数据库中创建表格"""
cursor.execute('''
CREATE TABLE IF NOT EXISTS rankings (
id INTEGER PRIMARY KEY AUTOINCREMENT,
rank TEXT,
name TEXT,
province TEXT,
type TEXT,
score TEXT
)
''')
def extract_data(table):
"""从表格中提取排名信息,并返回数据列表"""
data = []
for row in table.find_all('tr')[1:]:
cols = row.find_all('td')
data.append({
'rank': cols[0].get_text(strip=True),
'name': cols[1].get_text(strip=True),
'province': cols[2].get_text(strip=True),
'type': cols[3].get_text(strip=True),
'score': cols[4].get_text(strip=True)
})
return data
def insert_data(cursor, data):
"""将数据插入数据库"""
cursor.executemany('''
INSERT INTO rankings (rank, name, province, type, score)
VALUES (?, ?, ?, ?, ?)
''', [(item['rank'], item['name'], item['province'], item['type'], item['score']) for item in data])
def main():
url = 'http://www.shanghairanking.cn/rankings/bcur/2021'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
# 获取网页内容
html_content = fetch_html(url, headers)
# 解析网页
table = parse_html(html_content)
# 连接或创建数据库
conn = sqlite3.connect('university_rankings.db')
cursor = conn.cursor()
# 创建表格
create_db_table(cursor)
# 提取数据并插入数据库
data = extract_data(table)
insert_data(cursor, data)
# 提交事务
conn.commit()
# 关闭数据库连接
conn.close()
print("数据成功保存到数据库。")
if __name__ == "__main__":
main()
(2)运行展示:
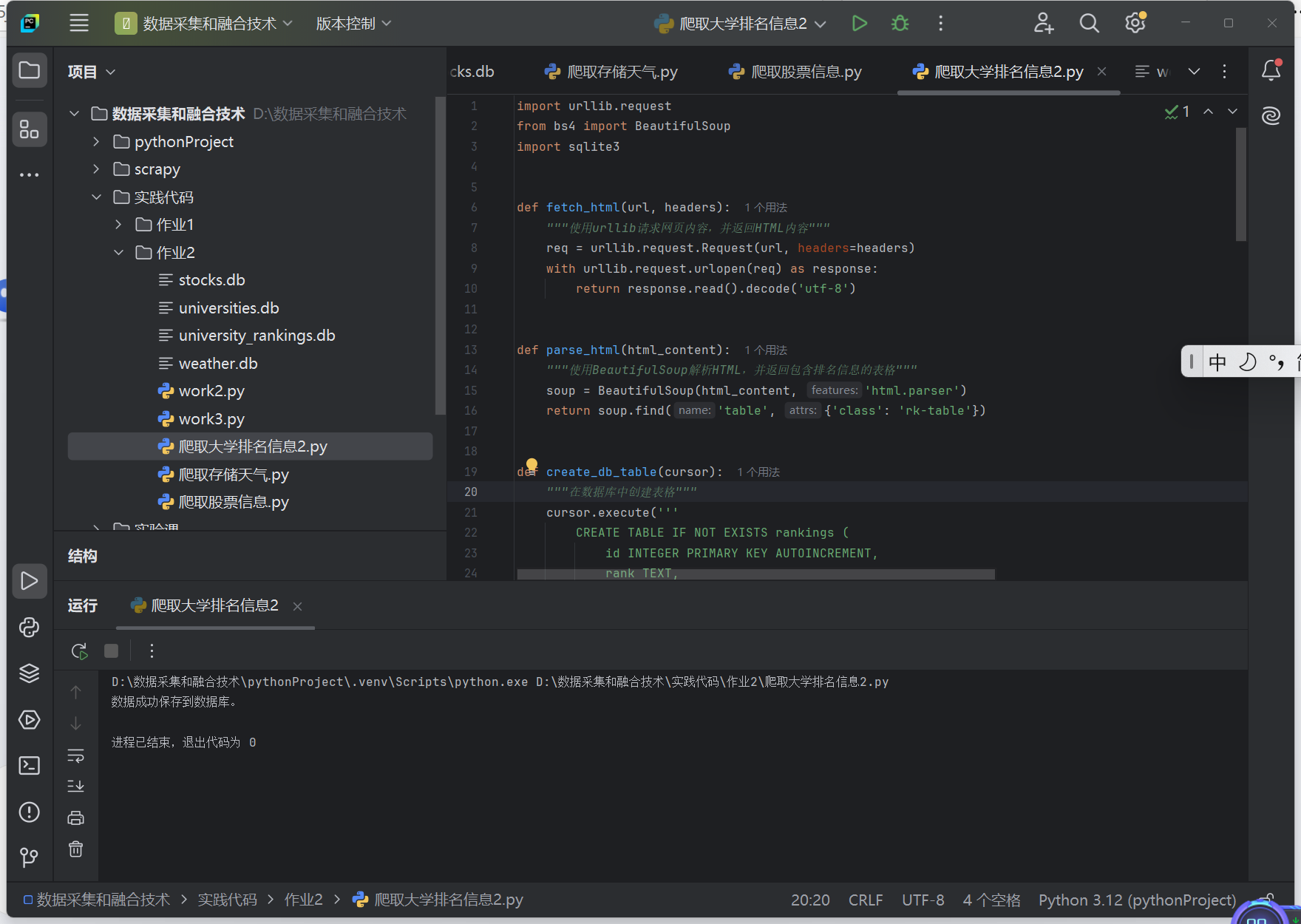
码云链接 https://gitee.com/jia1666372886/data-collection-work/issues
2.心得体会:
加深了抓包爬取的理解,巩固了api分析技巧的记忆
