云从科技 OCR任务 pixel-anchor 方法
云从科技提出了一种端到端的深度学习文本检测框架Pixel-Anchor,通过特征共享的方式高效的把像素级别的图像语义分割和锚检测回归放入一个网络之中,
把像素分割结果转换为锚检测回归过程中的一种注意力机制,使得锚检测回归的方法在获得高检出率的同时,也获得高精确度。此外,对于如中文这样文本长
度跨度很大的语言,在Pixel-Anchor中,提出了一个自适应的预测层,针对不同层级的特征所对应的感受野范围,设计不同的锚以及锚的空间位置分布,以更
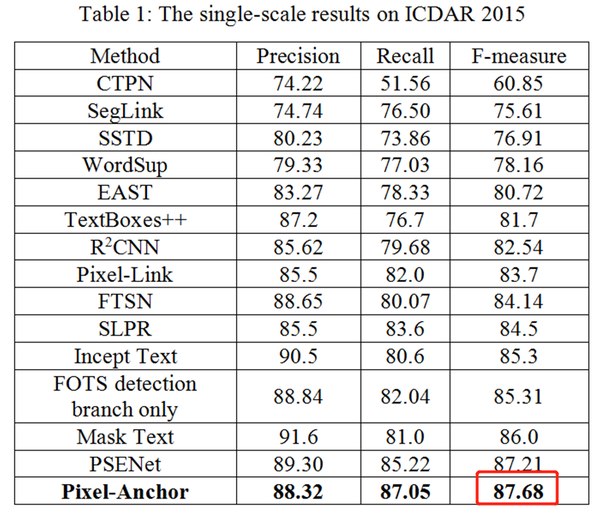
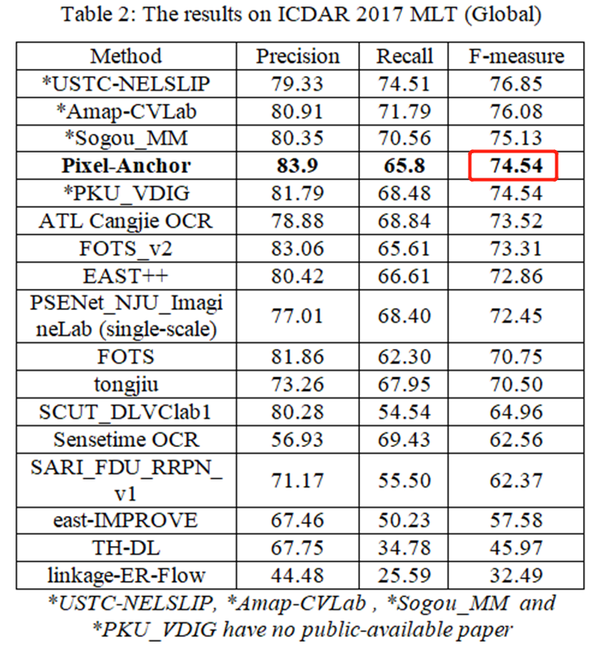
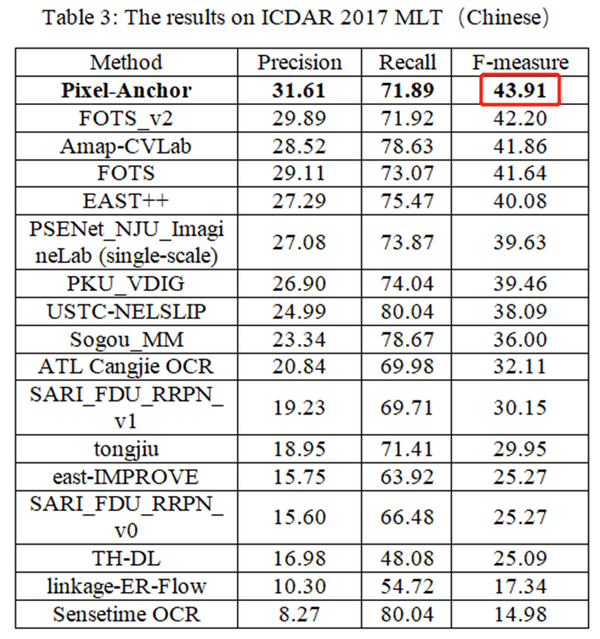
高的效率更好的适应变化的文本长度。如前所述,在两个具有挑战性的自然场景文本检测测试集ICDAR2015以及ICDAR2017 MLT,Pixel-Anchor在检测准确率
和检测效率两个综合维度上,获得了至今为止最好的结果(具体结果见下面Table 1,Table 2和Table 3)。该框架在满足生产环境实时性要求的基础上获得了很
高的检测准确率,目前该框架已在云从科技的证件票据识别系统和图片广告过滤系统中上线。
文章导读
Pixel-Anchor这套文本检测框架,和目前主流的文本检测框架相比,提出了两个大的改进点:
第一点是提出了把像素级别的图像语义分割以及基于锚的检测回归方法高效融合在一起,可端到端训练的检测网络。在该网络中,像素级别的图像语义分割以及基于锚的检测回归方法共享基础特征,而像素级别的图像语义分割结果作为一种注意力机制,用以监督锚检测回归的执行过程,在有效保证文本检出率的同时,提升了文本检测的精度。
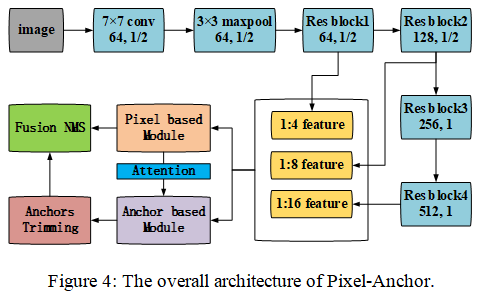
总体框架见上图,Pixel-Anchor采用学术界通用的ResNet-50作为特征提取主干网络,提取出1/4,1/8,1/16的特征图作为像素级别语义分割模块(Figure 5)以及锚检测回归模块(Figure 6)的基础特征,同时语义分割模块的输出结果以热力图的形式注入到锚检测回归模块中。整个网络简单轻巧,可通过ADAM优化方法进行端到端的训练。
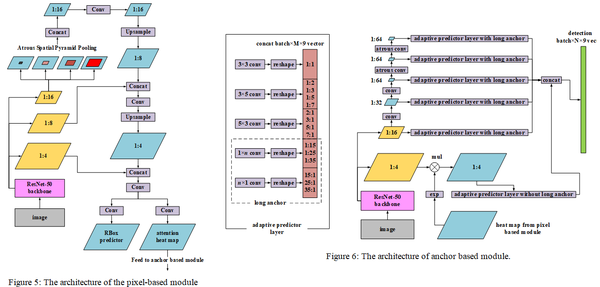
第二点是在锚检测回归这个模块中引入了自适应预测层“Adaptive Predictor Layer”,该预测层连接在不同层级的特征图之后,根据各特征图感受野的不同,调整锚的长宽比,卷积核的形状以及锚的空间密度(anchor density,见Figure 7),用以高效的获得各特征图上的文本检测结果,进而对文本长度的变化获得更好的适应性。自适应预测层在检测水平长文本上的性能非常出色,和经典的CTPN方法相比,我们的方法不需要复杂的后处理,更鲁棒的同时效率更高。

链接:https://zhuanlan.zhihu.com/p/50401761

 浙公网安备 33010602011771号
浙公网安备 33010602011771号